击败OpenAI,权重、数据、代码全开源,能完美复现的嵌入模型Nomic Embed来了
模型参数量只有137M,5天就能训练好。
一周前,OpenAI 给广大用户发放福利,在下场修复 GPT-4变懒的问题后,还顺道上新了5个新模型,其中就包括更小且高效的 text-embedding-3-small 嵌入模型。
我们知道,嵌入是表示自然语言或代码等内容中概念的数字序列。嵌入使得机器学习模型和其他算法更容易理解内容之间的关联,也更容易执行聚类或检索等任务。可见,嵌入在 NLP 领域是非常重要的。
不过,OpenAI 的嵌入模型并不是免费给大家使用的,比如 text-embedding-3-small 的收费价格是每1k tokens0.00002美元。
现在,比 text-embedding-3-small 更好的嵌入模型来了,并且还不收费。
AI 初创公司 Nomic AI 宣布推出 Nomic Embed,这是首个开源、开放数据、开放权重、开放训练代码、完全可复现和可审核的嵌入模型,上下文长度为8192,在短上下文和长上下文基准测试中击败 OpenAI text-embeding-3-small 和 text-embedding-ada-002。

文本嵌入是现代 NLP 应用程序的一个组成部分,为 LLM 和语义搜索提供了检索增强生成 (RAG)。该技术将有关句子或文档的语义信息编码为低维向量,然后用于下游应用程序,例如用于数据可视化、分类和信息检索的聚类。目前,最流行的长上下文文本嵌入模型是 OpenAI 的 text-embedding-ada-002,它支持8192的上下文长度。不幸的是,Ada 是闭源的,并且训练数据不可审计。
不仅如此,性能最佳的开源长上下文文本嵌入模型(例如 E5-Mistral 和 jina-embeddings-v2-base-en)要么由于模型大小而不适合通用用途,要么无法超越其 OpenAI 对应模型的性能。
Nomic-embed 的发布改变了这一点。该模型的参数量只有137M ,非常便于部署,5天就训练好了。

论文地址:https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
论文题目:Nomic Embed: Training a Reproducible Long Context Text Embedder
项目地址:https://github.com/nomic-ai/contrastors
如何构建 nomic-embed
现有文本编码器的主要缺点之一是受到序列长度限制,仅限于512个 token。为了训练更长序列的模型,首先要做的就是调整 BERT,使其能够适应长序列长度,该研究的目标序列长度为8192。
训练上下文长度为2048的 BERT
该研究遵循多阶段对比学习 pipeline 来训练 nomic-embed。首先该研究进行 BERT 初始化,由于 bert-base 只能处理最多512个 token 的上下文长度,因此该研究决定训练自己的2048个 token 上下文长度的 BERT——nomic-bert-2048。
受 MosaicBERT 的启发,研究团队对 BERT 的训练流程进行了一些修改,包括:
使用旋转位置嵌入来允许上下文长度外推;
使用 SwiGLU 激活,因为它已被证明可以提高模型性能;
将 dropout 设置为0。
并进行了以下训练优化:
使用 Deepspeed 和 FlashAttention 进行训练;
以 BF16精度进行训练;
将词表(vocab)大小增加到64的倍数;
训练的批大小为4096;
在掩码语言建模过程中,掩码率为30%,而不是15%;
不使用下一句预测目标。
训练时,该研究以最大序列长度2048来训练所有阶段,并在推理时采用动态 NTK 插值来扩展到8192序列长度。
实验
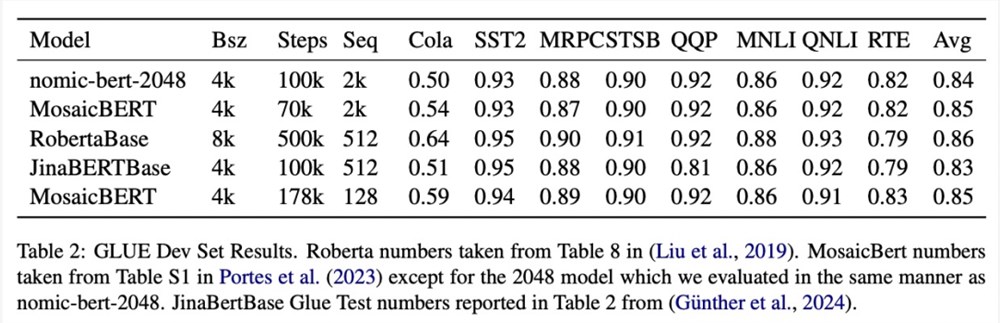
该研究在标准 GLUE 基准上评估了 nomic-bert-2048的质量,发现它的性能与其他 BERT 模型相当,但具有显著更长的上下文长度优势。
nomic-embed 的对比训练
该研究使用 nomic-bert-2048初始化 nomic-embed 的训练。对比数据集由约2.35亿文本对组成,并在收集过程中使用 Nomic Atlas 广泛验证了其质量。
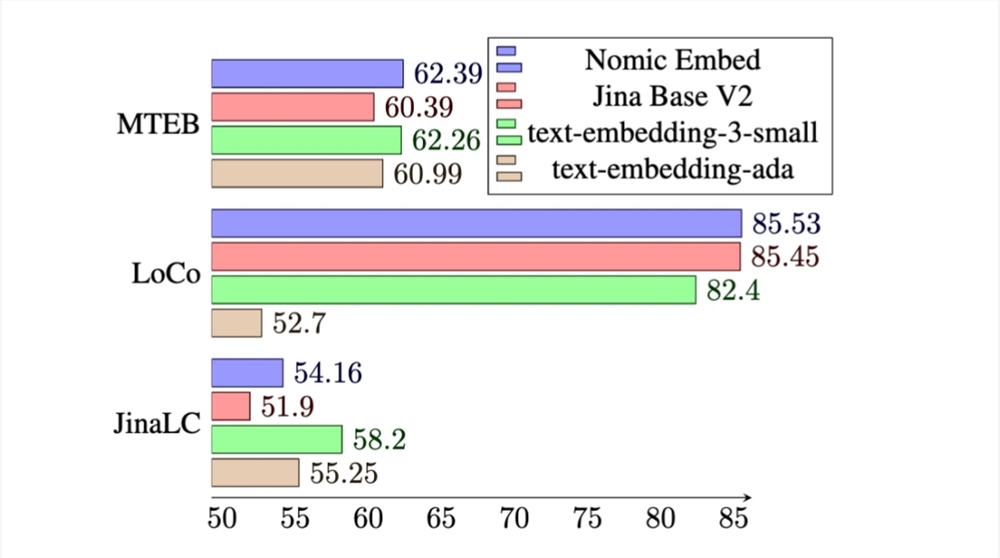
在 MTEB 基准上,nomic-embed 的性能优于 text-embedding-ada-002和 jina-embeddings-v2-base-en。

然而,MTEB 不能评估长上下文任务。因此,该研究在最近发布的 LoCo 基准以及 Jina Long Context 基准上评估了 nomic-embed。
对于 LoCo 基准,该研究按照参数类别以及评估是在监督或无监督设置中执行的分别进行评估。
如下表所示,Nomic Embed 是性能最佳的100M 参数无监督模型。值得注意的是,Nomic Embed 可与7B 参数类别中表现最好的模型以及专门针对 LoCo 基准在监督环境中训练的模型媲美:

在 Jina Long Context 基准上,Nomic Embed 的总体表现也优于 jina-embeddings-v2-base-en,但 Nomic Embed 在此基准测试中的表现并不优于 OpenAI ada-002或 text-embedding-3-small:

总体而言,Nomic Embed 在2/3基准测试中优于 OpenAI Ada-002和 text-embedding-3-small。
该研究表示,使用 Nomic Embed 的最佳选择是 Nomic Embedding API,获得 API 的途径如下所示:


最后是数据访问:为了访问完整数据,该研究向用户提供了 Cloudflare R2(类似 AWS S3的对象存储服务)访问密钥。要获得访问权限,用户需要先创建 Nomic Atlas 帐户并按照 contrastors 存储库中的说明进行操作。
contrastors 地址:https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
成交额翻四倍,珍珠何以卖爆冷清的双十一?
从黄金,到宝石,如今年轻人的新风潮又转向了珍珠。“黛安娜王妃不都说了嘛,‘女人如果只能拥有一件珠宝,必是珍珠’。”自诩入了珍珠“坑”的露露向价值星球表示,自己也是看着小红书上穿搭博主佩戴珍珠配饰,觉得好看才买,但没想到接触后,“对珍珠越来越心动。”像露露这样最近爱上珍珠的消费者,实则还不少。站长网2023-11-10 17:52:140000F1 将在阿布扎比大奖赛试用人工智能技术监控赛道界限违规
国际汽车联合会(FIA)宣布,在本周末的赛季收官阿布扎比大奖赛中,将试用人工智能(AI)技术来处理赛道界限违规问题。FIA将使用名为「计算机视觉」的技术,该技术通过分析形状来确定超出赛道边缘的像素数量。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2023-11-24 09:45:110000司机都下岗的节奏!黄仁勋:未来汽车将全自动驾驶
快科技1月11日消息,对于司机这个岗位来说,以后可能都有没有必要存在了。英伟达CEO黄仁勋在CES展会上表示,到20年后所有汽车都将具备自动驾驶功能。特别是下一代纯电动汽车(EV)将全部成为自动驾驶汽车”,作为理由列举了人工智能(AI)和传感器技术的进步。他认为乘车人可以自己选择,也可以选择自己开车”。黄仁勋说。0000会玩的年轻人,流行去滑雪场过周末
进入冬季,一年一度的滑雪热又来了。即便滑雪被称为中产运动,但爱玩的年轻人总能找到各种低价玩法,比如2023年的“穷滑”“拼单滑”大火,让很多年轻人体验了人生中的第一次滑雪。这个冬季,他们又带火了一种新玩法——“特种兵式滑雪”。此前的特种兵式旅游,以时间短、景点多、花费少、效率高著称,特种兵式滑雪也类似,主要体现在三方面:0000AI视野:荣耀发布魔法大模型;阿里推开源版FaceChain;钉钉小冰合作推一键定制数字人;微博上线AI评论机器人
欢迎来到【AI视野】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/🤖📈💻💡大模型动态荣耀发布魔法大模型站长网2024-01-10 16:50:010000










