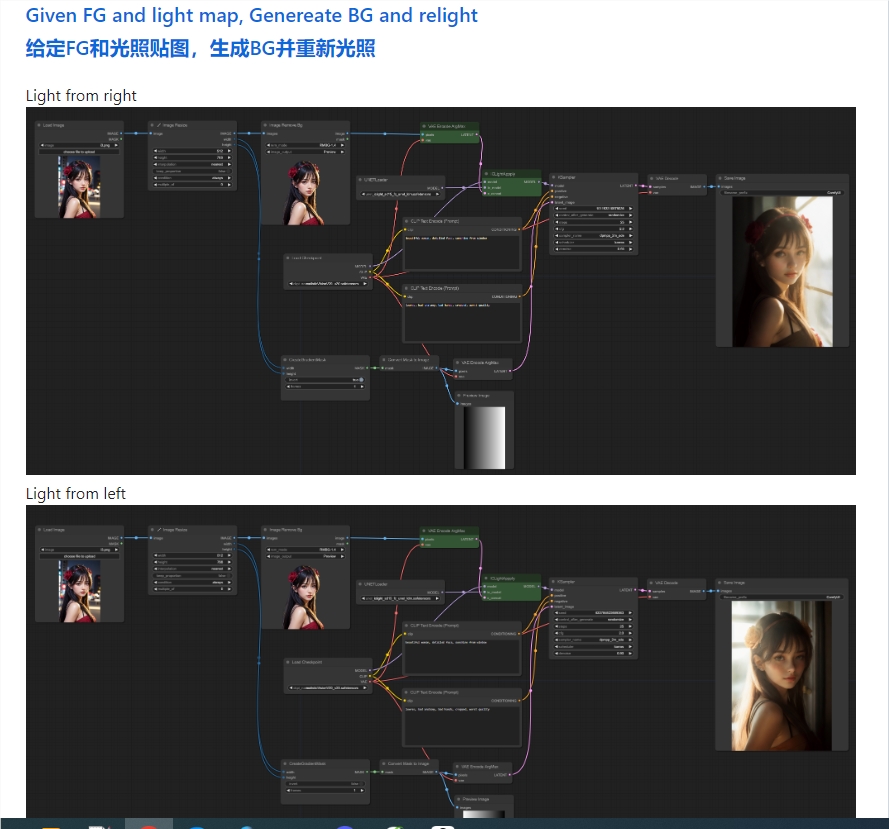
图片质量媲美Midjourney、SDXL?PixArt训练成本减少90%
要点:
PixArt-α是一款基于Transformer的文本到图像生成模型,具有竞争力的图像生成质量,且训练成本明显低于现有大规模文本到图像模型。
PixArt-α采用了三项核心设计:训练策略分解,高效的T2I Transformer,以及使用高信息密度的数据进行训练,从而实现高分辨率图像合成,并在训练成本上取得显著节约。
PixArt-α不仅能够生成高分辨率图像,而且在复杂文本提示下表现出色,与现有系统如Stable Diffusion XL、Imagen和DALL-E2相比,既能匹敌其质量,又更加高效。
PixArt是一款基于Transformer的文本到图像生成模型,其图像生成质量可与最先进的图像生成器(例如Imagen、SDXL,甚至Midjourney)竞争,达到接近商业应用的标准。这种新模型使用Transformer扩散模型,可以比使用UNet模型训练便宜90%。它还支持高达1024px 分辨率的高分辨率图像合成,且训练成本较低。

项目地址:
https://huggingface.co/docs/diffusers/main/en/api/pipelines/pixart?utm_source=talkingdev.uwl.me
该模型通过三项核心设计实现了高分辨率图像的合成,同时显著降低了训练成本。首先,采用训练策略分解,将训练过程分为三个步骤,分别优化像素依赖性、文本-图像对齐和图像审美质量。其次,引入了高效的T2I Transformer,通过在Diffusion Transformer中加入交叉注意力模块,注入文本条件并简化计算密集型的类别条件分支。最后,利用高信息密度的数据进行训练,强调文本-图像对中概念密度的重要性,并借助大型视觉语言模型自动标注密集伪标题,助力文本-图像对齐学习。
PixArt不仅在高分辨率图像合成上表现出色,还能有效遵循复杂文本提示,使其在图像生成领域具有广泛的应用前景。与现有系统相比,如Stable Diffusion XL、Imagen和DALL-E2,PixArt-α不仅匹敌其生成质量,而且在训练效率上更为高效。
实验证明,PixArt的训练速度仅占Stable Diffusion v1.5训练时间的10.8%(675vs.6,250A100GPU天),节省近30万美元和减少90%的CO2排放。与更大的SOTA模型RAPHAEL相比,训练成本仅为1%。总体而言,PixArt-α在图像质量、艺术性和语义控制方面都表现卓越,为AIGC社区和初创公司提供了加速从零开始构建高质量低成本生成模型的新视角。
在使用PixArt时,可以通过设定不同的尺寸范围来获得最佳结果,作者推荐了一些尺寸范围。此外,PixArt支持高分辨率图像合成,最高可达1024像素,且训练成本较低。因此,PixArt不仅在技术上取得了显著进展,而且在实际应用中具有巨大的潜力。
谷歌Gemini翻车内幕被曝光:内部管理混乱,生图机制过分 “多元化”
划重点:⭐️谷歌Gemini生图机制内幕曝光⭐️内部“多元化”政策影响图片生成流程⭐️员工爆料谷歌内部管理混乱近日,谷歌Gemini生图机制内幕曝光,显示其内部管理混乱,生图机制过分“多元化”。站长网2024-03-07 16:42:500000IC-Light ComfyUI节点发布 商品图重绘表现出色
在视觉设计和图像处理领域,光照和背景的匹配对于最终效果至关重要。目前,原生的IC-LightComfyUI节点已经发布了,为设计师和摄影师带来了一系列创新功能,极大地提升了图像编辑和合成的效率与质量。项目地址:https://top.aibase.com/tool/comfyui-ic-light主要功能亮点站长网2024-05-11 06:51:130001OpenAI与阿联酋科技巨头G42达成合作 提供AI解决方案
阿联酋科技巨头G42与OpenAI于10月18日宣布建立合作伙伴关系,以在阿联酋和地区市场提供人工智能(AI)解决方案。根据声明,双方的合作将侧重于金融服务、能源、医疗保健和公共服务等G42所深耕的领域,并将采用OpenAI的生成式AI模型。站长网2023-10-19 08:33:310000再次失败,马斯克的星舰发射后失联自毁
一级爆炸,二级失联,但向前迈进了一步。北京时间11月18日21时3分,在万众瞩目下,马斯克SpaceX的星舰——有史以来人类最强大的火箭,刚刚经历了第二次发射。这次发射尝试中,星舰经历了成功的一二级分离,但二级因速度不够导致切入轨道失败。在发射半小时后,SpaceX宣布二级自毁,火箭发射失败。但这次发射相比上次,距离成功更近了一步。站长网2023-11-19 09:39:320000一亿赔付之争:大主播翻车,赔偿全凭良心
辛巴和小杨哥的赔付之争,打了整个直播电商行业的脸。临近中秋节,头部主播们也忙了起来,忙着“翻车”,忙着赔付。交个朋友公开发文,称被品牌方混淆视听,上架了“李鬼”月饼,决定自掏腰包进行“退一赔三”。站长网2024-09-14 02:33:160000