比Transformer更好的模型架构?Monarch Mixer更低成本取得更优表现
要点:
1. Monarch Mixer (M2) 是一种新的模型架构,与传统的Transformer不同,它通过使用Monarch矩阵替代注意力和MLP,使之在语言和图像实验中以更低的成本取得了更优的表现。
2. Monarch Mixer 的关键创新点在于其次二次的复杂度,使其能够处理更长的序列和更高维度的表征,同时保持计算效率。
3. 实验证明,M2在各种任务上,包括语言建模和图像分类,能够与传统Transformer媲美,同时具有更高的硬件效率和更少的参数。
近年来,Transformer模型在自然语言处理和计算机视觉领域取得了巨大成功,但它的高成本、复杂性以及依赖于注意力机制和多层感知机(MLP)等组件使得人们开始寻求替代方案。论文介绍了一种名为Monarch Mixer(M2)的全新模型架构,这个架构在序列长度和模型维度上都表现出次二次复杂度的特点,同时在现代硬件加速器上具有出色的性能。

论文地址:https://arxiv.org/abs/2310.12109
代码地址:https://github.com/HazyResearch/m2
Monarch Mixer(M2)的主要创新点在于它采用了Monarch矩阵,将传统Transformer中的注意力机制和MLP替代为更高性能的结构。Monarch矩阵是一种次二次结构化矩阵,能够支持更长的序列和更高维度的表示,同时保持计算效率。这个矩阵可以通过分块对角矩阵的积进行参数化,其计算复杂度与输入长度呈次二次增长关系,这使得M2能够在处理大规模数据时具有出色的性能。
实验结果表明,M2在多个任务上都能够媲美传统Transformer模型,包括非因果语言建模、图像分类和因果语言建模。与传统Transformer相比,M2不仅能够节省大量参数,还具有更高的硬件效率,这使得它成为一个有潜力的替代选择。
斯坦福大学和纽约州立大学布法罗分校的研究团队的工作为机器学习领域带来了新的思路,挑战了传统Transformer模型的优越性。他们的研究不仅探索了Monarch Mixer的理论基础,还进行了一系列实验来验证其性能。这篇文章的发表为机器学习社区提供了一个全新的研究方向,也让人们重新思考了在自然语言处理和计算机视觉任务中的模型选择。
总的来说,Monarch Mixer(M2)是一种具有次二次复杂度的新型模型架构,能够在不使用传统Transformer中的注意力和MLP的情况下,在自然语言处理和计算机视觉任务中表现出色。它的硬件效率和参数效率使其成为一个有望取代传统Transformer的新选择,为深度学习研究领域带来了新的思考。
WhisperKit开源!可在iPhone和Mac流畅体验实时语音转录
划重点:-WhisperKit是Argmax公司推出的开源项目,旨在实现苹果芯片上的实时语音转文本,通过多项优化提高性能。-该项目采用MIT许可证,提供Swift包、iOS和macOS示例应用以及Python工具,为开发者提供最大便利。-WhisperKit的设计原则包括灵活性、可扩展性、可预测性,以及专注于实时性能。站长网2024-01-31 11:56:390000特斯拉Cybertruck儿童车4月23日发售:LED大灯、续航19公里
快科技4月19日消息,特斯拉儿童版Cybertruck即将于4月23日10:00正式登陆中国市场,为6至12岁的孩子们带来前所未有的科技驾驶体验。这款儿童车完美继承了特斯拉Cybertruck皮卡的经典造型,同时又融入了诸多贴心的设计元素,确保了孩子们在享受驾驶乐趣的同时,也能得到全方位的安全保障。车身细节处理得恰到好处,尤其是LED头尾灯,不仅提升了户外活动的安全性,还增添了一份科技魅力。站长网2024-04-19 13:58:090000百度CEO李彦宏:大模型将重新定义人工智能应用,不担心工作机会减少
今日,百度CEO李彦宏在第七届世界智能大会上发表了题为《大模型改变人工智能》的演讲。他表示,人类最大的威胁不是创新带来的不确定性,而是按照惯性走下去所带来的各种不可预知的风险。大模型之所以会改变人工智能,原因在于大算力、大模型、大数据导致了智能涌现。站长网2023-05-18 14:52:500000美团王兴:正研究和开发基础模型以及应用 对外部机会持开放态度
美团发布2023年第一季度财报。财报显示,一季度营收586.2亿元,同比增长26.7%,市场预期574.76亿元。一季度,研发支出同比增长至50亿元。站长网2023-05-26 08:57:490000新AI框架H2O:将人类动作实时转换为机器人动作 可行走、后空翻、踢球等
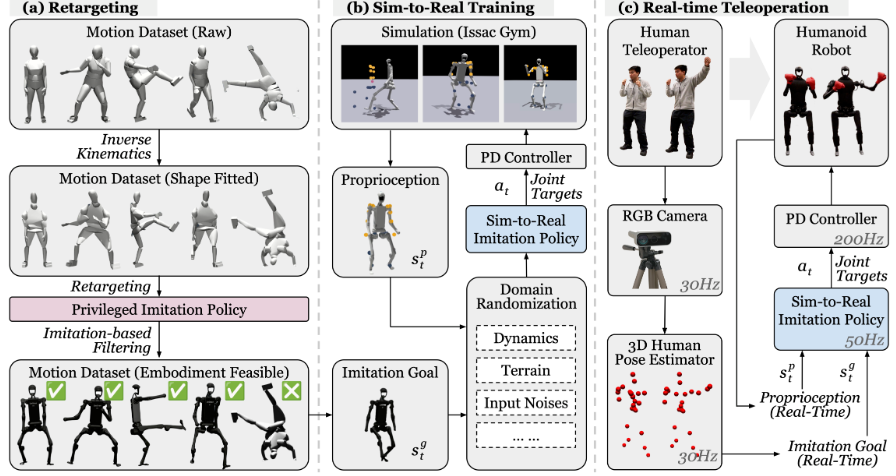
划重点:1.🔄**框架介绍**:H2O(HumantoHumanoid)是基于强化学习的框架,通过仅使用RGB摄像头实现了全尺寸人形机器人的实时全身遥控操作。2.🔄**数据处理过程**:采用可扩展的“从模拟到实际”处理,通过特权模仿者筛选和选择可行的动作,构建了大规模的重定目标运动数据集。站长网2024-03-11 11:22:420001