DeepMind验证卷积神经网络在大规模数据集上可媲美视觉变换器
核心要点:
1. 最近的研究表明,卷积神经网络(ConvNets)在大规模数据集上可以与视觉变换器(Vision Transformers)媲美,挑战了以往认为视觉变换器在这方面具有卓越性能的观点。
2. 研究团队使用NFNet模型在巨大的JFT-4B数据集上进行了训练,发现随着计算资源的增加,ConvNets的性能可以与视觉变换器相匹敌,达到了令人印象深刻的ImageNet Top-1准确度。
3. 该研究突出了计算资源和可用于训练的数据量是影响模型性能的主要因素,以及ConvNets,特别是NFNet架构,具备在以往认为是视觉变换器领域的规模上竞争的能力。
最新研究表明,卷积神经网络(ConvNets)在大规模数据集上能够与视觉变换器(Vision Transformers)媲美,挑战了以往认为视觉变换器在这方面具有卓越性能的观点。在计算机视觉领域,ConvNets一直以来都是在各种基准测试中取得卓越性能的标准。然而,近年来,视觉变换器逐渐崭露头角,逐渐超越了ConvNets。有许多专家认为ConvNets在小到中等规模数据集上表现出色,但在面对大规模数据集时,视觉变换器占据了优势。
论文地址:https://arxiv.org/pdf/2310.16764.pdf
一项由Google DeepMind的研究团队进行的新研究挑战了视觉变换器在规模上具有卓越扩展能力的普遍观点。该团队对一种纯粹的ConvNet架构进行了全面评估,这种架构被称为NFNet模型,该模型在大规模数据集上进行了预训练。研究结果显示,ConvNets在大规模数据集上确实可以与视觉变换器相匹敌。
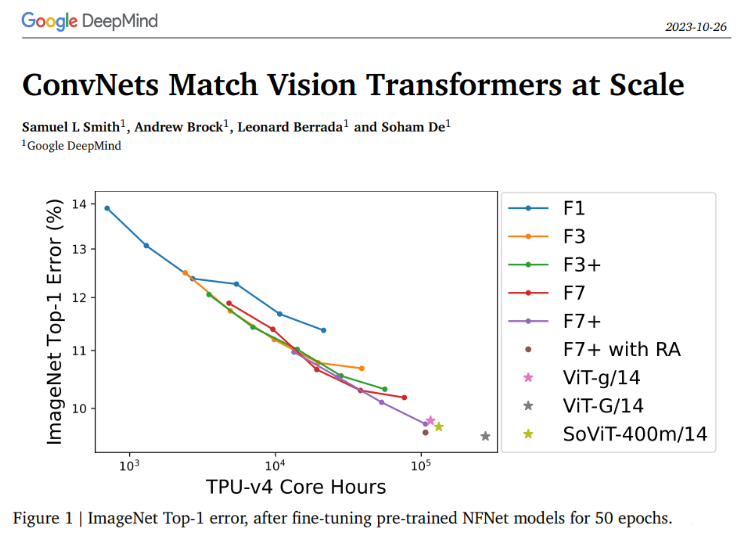
研究团队在巨大的JFT-4B数据集上训练了各种深度和宽度不同的NFNet模型。这个数据集包含大约40亿张图像,涵盖了3万个类别。在对预训练的NFNet模型进行50个时代的微调后,ImageNet Top-1误差在与预训练时使用的计算资源的直接相关性下持续改善。最大的模型,被称为F7 ,在可比较的计算预算下达到了与预训练的视觉变换器报告的性能相当的ImageNet Top-1准确度,达到了惊人的90.3%。
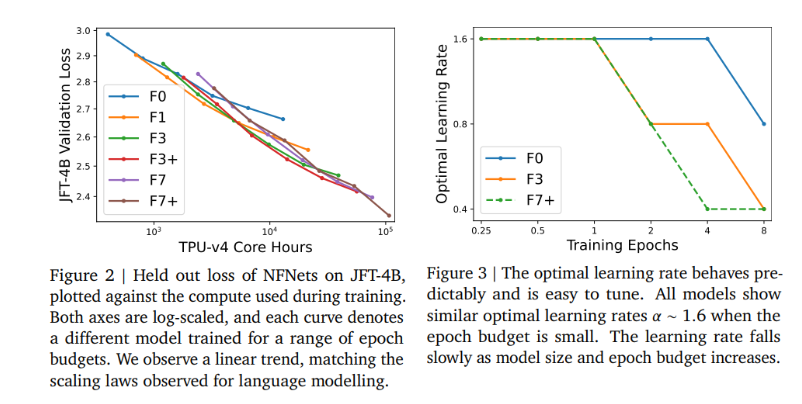
为了更清楚地了解验证损失与预训练计算之间的关系,研究团队绘制了每个模型所需计算预算结束时的验证损失。这个练习揭示了一个明显的线性趋势,与支配验证损失和预训练计算的对数缩放定律一致。随着计算资源的增加,最佳模型大小和训练时期的预算也随之增加。此外,人们还注意到,调整ConvNets的一个可靠经验法则是按比例调整模型大小和训练时期的数量。
有趣的是,研究人员还调查了NFNet系列的三种不同模型(F0、F3、F7 )在一系列时期预算下的最佳学习率。他们的研究结果表明,当受到较小的时期预算限制时,所有这些模型都表现出相似的最佳学习率(约为1.6)。然而,随着时期预算的增加,最佳学习率减小,较大的模型经历了更快的下降。
总的来说,这项研究强调了在计算机视觉领域,合理设计的模型性能的主要因素是计算资源和可用于训练的数据量。从这项工作中可以明显看出,ConvNets,特别是NFNet架构,具备在以往认为是视觉变换器领域的规模上竞争的能力。这些结果突显了同时扩展计算和数据资源的重要性,为计算机视觉研究的未来带来了新的启示。
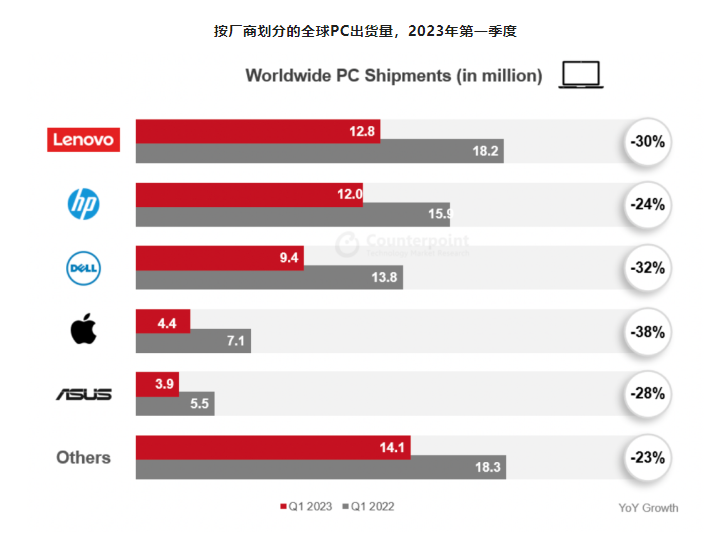
报告:2023年第一季度全球PC出货量同比下降28%
CounterpointResearch公布数据称,2023年第一季度,全球PC出货量为5,670万台,年同比下降28%,成为过去10年来,除2020年第一季度因新冠疫情爆发中断制造和生产外,出货量最低的季度。站长网2023-04-20 09:23:390000抖音推出首部AIGC科幻短剧集:共12集 暑期档播出
快科技6月17日消息,在博纳25周年向新而生”新闻发布会上,博纳影业出品制作、抖音联合出品的AIGC科幻短剧集《三星堆:未来启示录》正式亮相。该剧第一季共12集,作为抖音推出的首部AIGC科幻短剧集,预计上线今年的短剧暑期档,在即梦AI、博纳影业AIGMS、剪映的抖音官方账号同步更新。《三星堆:未来启示录》基于博纳影业2022年立项的同名电影所打造,是2024年立项的全国重点微短剧。站长网2024-06-18 20:02:070000Ouroboros3D:通过3D感知实现图像到3D的生成
划重点:🔍Ouroboros3D是一个集成了多视角图像生成和3D重建的统一3D生成框架🔍通过递归扩散过程,Ouroboros3D实现了从图像到3D的生成🔍Ouroboros3D采用了基于扩散的多视角图像生成和3D重建方法站长网2024-06-06 17:20:590000紧锣密鼓调整,美团正在下一盘大棋
王兴:如果不能做得更好,我们就处在一个非常危险的状态。美团调整组织架构,推行“蜂窝制”美团再一次“排兵布阵”。近日,记者从美团内部人士处了解到,自9月1日起,美团到店餐饮业务将在全国范围内进行一轮新的组织架构大调整。调整后,地面销售将从原来的“全城签维”运营,转变为以区域划分、责任到人的“蜂窝制”运营。站长网2024-09-02 09:51:400001迪拜AI配音公司Camb.AI种子融资400万美元,高还原度即时配音服务
划重点:💼迪拜AI配音初创公司Camb.AI筹集400万美元种子轮融资,由多家国际投资机构领投。🎙️Camb.AI的旗舰产品DubStudio能够提供高还原度的即时配音服务,涵盖100多种语言、方言和口音。🌍Camb.AI的技术已被广泛应用于媒体、体育和娱乐领域,客户包括多个知名体育组织和娱乐公司。站长网2024-03-20 10:01:030000