DeepMind让大模型学会归纳和演绎,GPT-4准确率提升13.7%
当前,大型语言模型(LLM)在推理任务上表现出令人惊艳的能力,特别是在给出一些样例和中间步骤时。然而,prompt 方法往往依赖于 LLM 中的隐性知识,当隐性知识存在错误或者与任务不一致时,LLM 就会给出错误的回答。
现在,来自谷歌、Mila 研究所等研究机构的研究者联合探索了一种新方法 —— 让 LLM 学习推理规则,并提出一种名为假设到理论(Hypotheses-to-Theories,HtT)的新框架。这种新方法不仅改进了多步推理,还具有可解释、可迁移等优势。

论文地址:https://arxiv.org/abs/2310.07064
对数值推理和关系推理问题的实验表明,HtT 改进了现有的 prompt 方法,准确率提升了11-27%。学到的规则也可以迁移到不同的模型或同一问题的不同形式。
方法简介
总的来说,HtT 框架包含两个阶段 —— 归纳阶段和演绎阶段,类似于传统机器学习中的训练和测试。
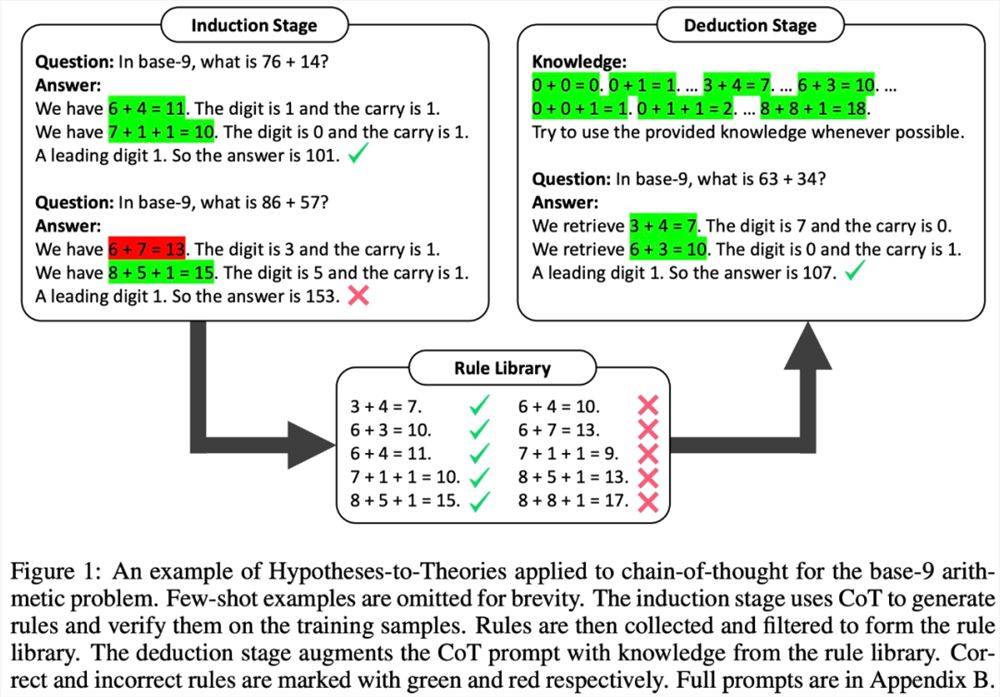
在归纳阶段,LLM 首先被要求生成并验证一组训练样例的规则。该研究使用 CoT 来声明规则并推导答案,判断规则的出现频率和准确性,收集经常出现并导致正确答案的规则来形成规则库。
有了良好的规则库,下一步该研究如何应用这些规则来解决问题。为此,在演绎阶段,该研究在 prompt 中添加规则库,并要求 LLM 从规则库中检索规则来进行演绎,将隐式推理转换为显式推理。
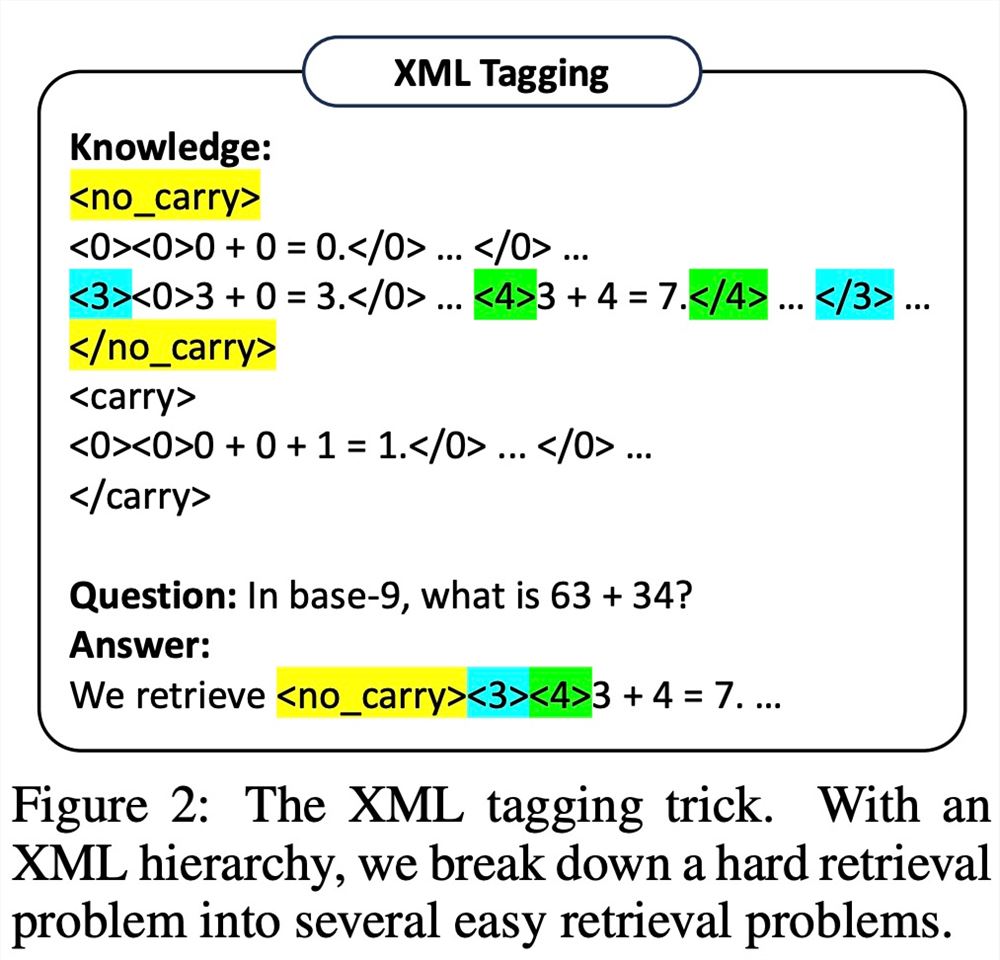
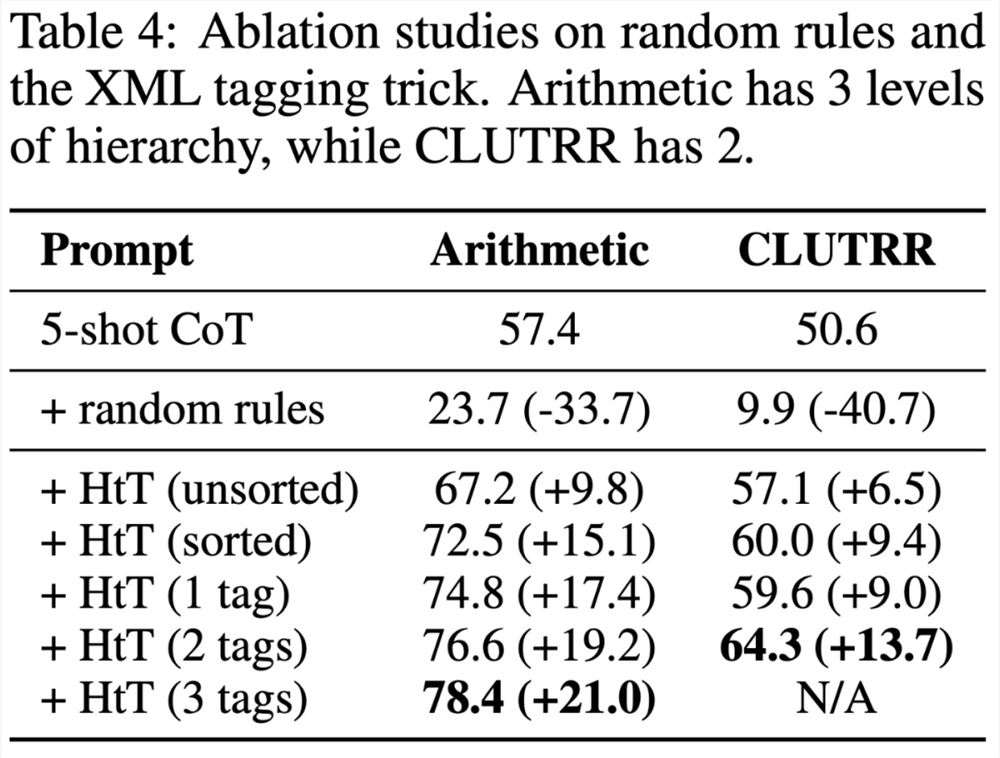
然而,该研究发现,即使是非常强大的 LLM(例如 GPT-4)也很难在每一步都检索到正确的规则。为此,该研究开发了 XML tagging trick,来增强 LLM 的上下文检索能力。
实验结果
为了评估 HtT,该研究针对两个多步骤推理问题进行了基准测试。实验结果表明,HtT 改进了少样本 prompt 方法。作者还进行了广泛的消融研究,以提供对 HtT 更全面的了解。
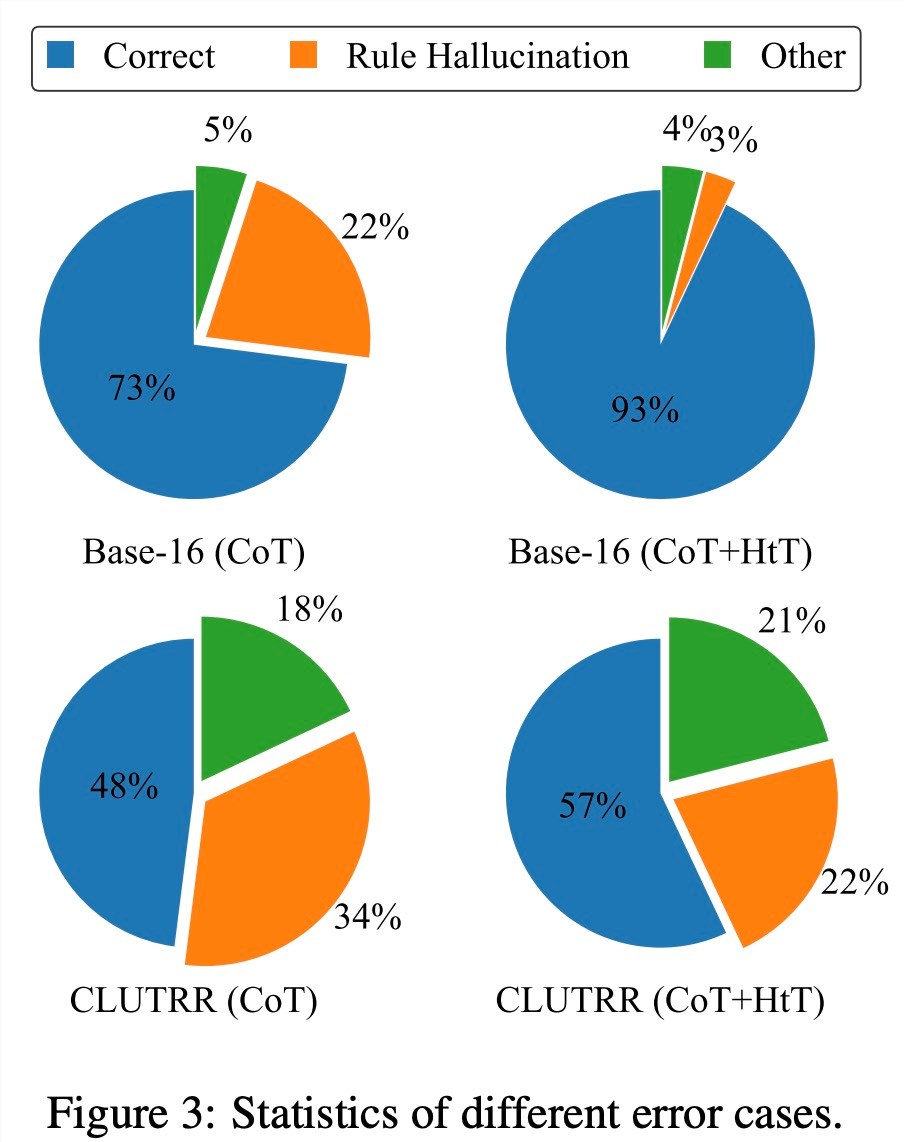
他们在数值推理和关系推理问题上评估新方法。在数值推理中,他们观察到 GPT-4的准确率提高了21.0%。在关系推理中,GPT-4的准确性提高了13.7%,GPT-3.5则获益更多,性能提高了一倍。性能增益主要来自于规则幻觉的减少。
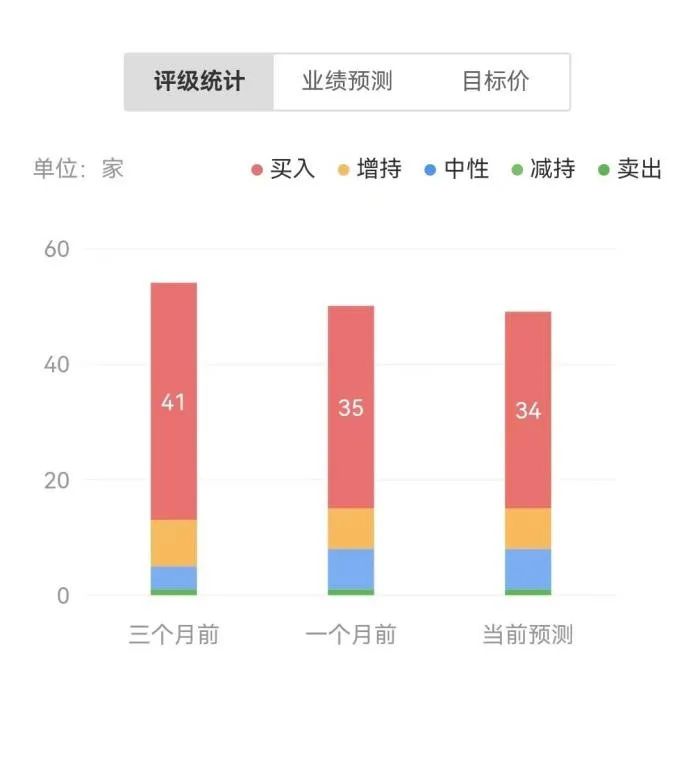
具体来说,下表1显示了在算术的 base-16、base-11和 base-9数据集上的结果。在所有 base 系统中,0-shot CoT 在两个 LLM 中的性能都最差。
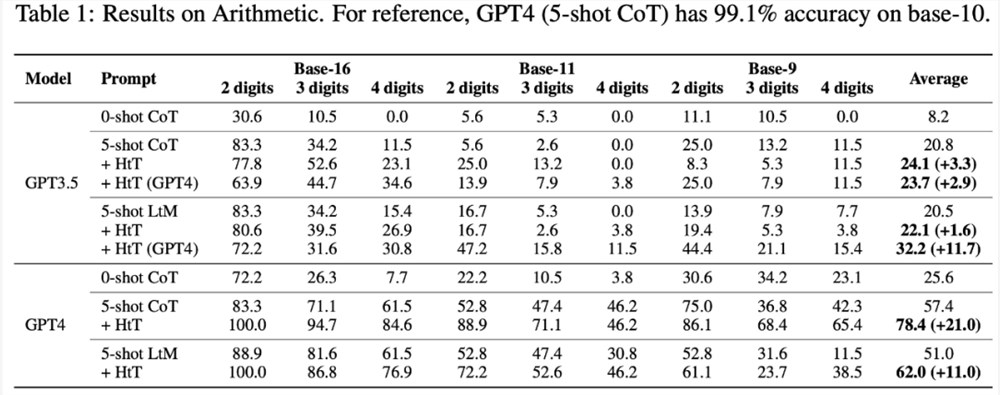
表2呈现了在 CLUTRR 上比较不同方法的结果。可以观察到,在 GPT3.5和 GPT4中,0-shot CoT 的性能最差。对于 few-shot 提示方法,CoT 和 LtM 的性能相似。在平均准确率方面,HtT 始终比两种模型的提示方法高出11.1-27.2%。值得注意的是,GPT3.5在检索 CLUTRR 规则方面并不差,而且比 GPT4从 HtT 中获益更多,这可能是因为 CLUTRR 中的规则比算术中的规则少。
值得一提的是,使用 GPT4的规则,GPT3.5上的 CoT 性能提高了27.2%,是 CoT 性能的两倍多,接近 GPT4上的 CoT 性能。因此,作者认为 HtT 可以作为从强 LLM 到弱 LLM 的一种新的知识蒸馏形式。
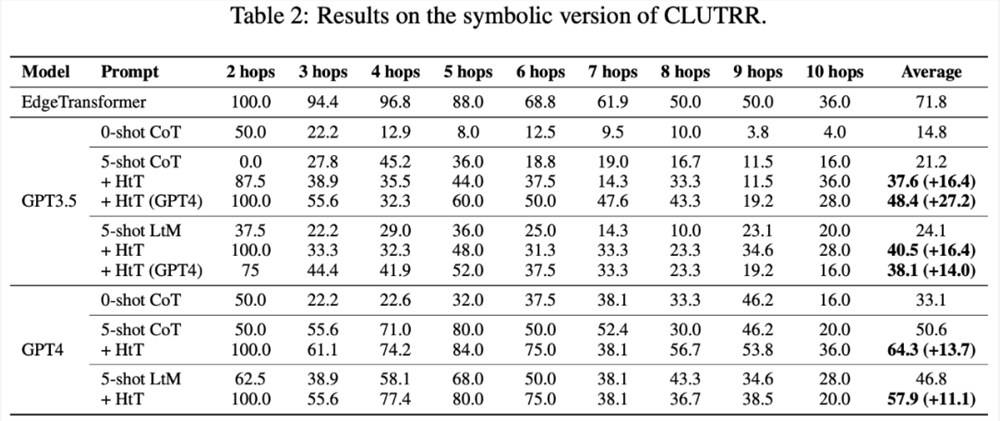
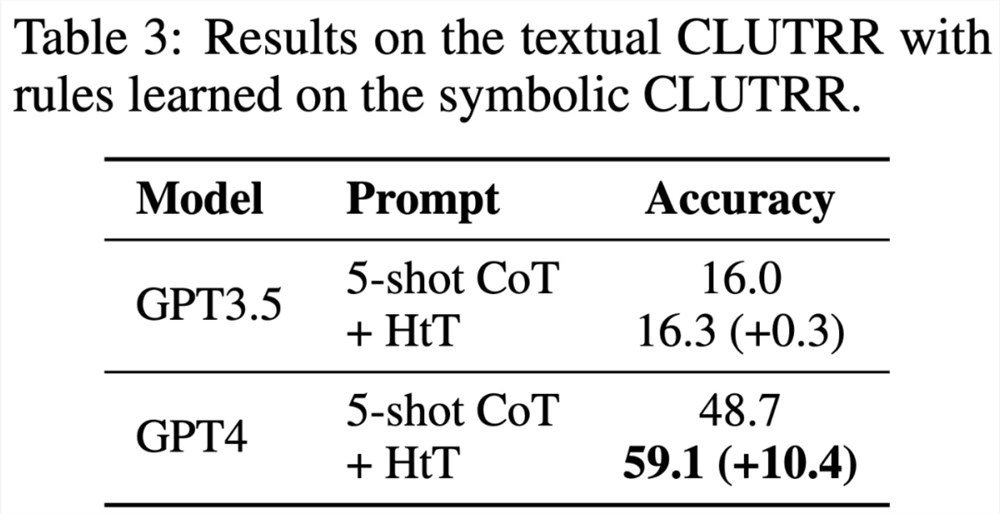
表3显示,HtT 显著提高了 GPT-4(文本版)的性能。对于 GPT3.5来说,这种改进并不显著,因为在处理文本输入时,它经常产生除规则幻觉以外的错误。
站在AI之巅,微软为何仍被“看空”?
眼下,万物皆可AI。当AI成为资本市场的关键词之后,点燃了投资者的热情,高唱“死了都要AI”,将行情的演绎达到极致。国内热情洋溢,国外也不遑多让。作为ChatGPT的“金主”,微软也成功站上“风口”,2023年第一季度市值增长超3200亿美元,好不风光。尽管如此,市场仍不乏看空微软之声。站长网2023-04-12 16:50:140000谁在小红书直播间“赛博相亲”?
00后玩起了一种新鲜的社交方式——赛博相亲。一个典型的举动是,在社交网络上直播交友。比如,年轻人在小红书的赛博相亲,是更看重个人特质和共同爱好,而非传统的家庭背景、物质条件。常见的话题有生活方式、星座、MBTI人格测试、游戏、动漫等,寻找"灵魂伴侣"和“同好”。当然,城市坐标、身高、年龄乃至体重,也是他们不回避的重点。站长网2024-05-25 06:37:040000山寨 GPT 太疯狂,OpenAI 发出“警告”:别用它来命名,正加速申请 GPT 商标
近半年来,随着OpenAI推出ChatGPT、GPT-4,彻底点燃AI赛道,也让GPT系列产品层出不穷,如AutoGPT、MiniGPT-4、Cerebras-GPT等等。站长网2023-04-25 16:35:330000李想发全员信自我批评:理想汽车不再单纯追求销量
理想汽车CEO李想近日发布全员信,深入剖析了公司近期面临的挑战,并针对理想MEGA汽车的上市节奏以及过分关注销量的欲望问题,提出了解决方案。站长网2024-03-22 02:32:000000研究发现:人工智能的应用让乳腺癌的检出率提高了20%
根据一项在瑞典进行的研究结果显示,与传统的放射科医生筛查相比,人工智能能够准确地从乳房X光片中检测出更多的乳腺癌,提高了20%的检测率。这项研究是第一个探讨人工智能在乳腺癌筛查中的应用的随机对照试验。站长网2023-08-02 15:07:010000