中国研究团队发布多视角数据集“FreeMan” 解决3D人体姿势估计局限性
文章概要:
- “FreeMan”是一份大规模多视角数据集,旨在解决现有3D人体姿态估计数据集的局限性。
- 数据集包含来自8台同步智能手机的1100万帧,跨足了室内和室外环境,具备不同光照条件,提供了更真实的场景多样性。
- 研究者通过自动化的标注流程,包括人体检测、2D关键点检测、3D姿态估计和网格标注,生成了精确的3D标注,可用于多种任务,如单2D到3D转换、多视角3D估计和神经渲染。
从真实场景中估计人体的三维结构是一项具有挑战性的任务,对于人工智能、图形学和人机交互等领域具有重要意义。然而,现有的3D人体姿态估计数据集通常在受控条件下收集,具有静态背景,无法代表真实世界场景的多样性,从而限制了用于真实应用的准确模型的开发。
在这方面,类似于Human3.6M和HuMMan的现有数据集广泛用于3D人体姿态估计,但它们是在受控的实验室环境中收集的,无法充分捕捉真实世界环境的复杂性。这些数据集在场景多样性、人体动作和可扩展性方面存在局限。研究人员提出了各种模型用于3D人体姿态估计,但由于现有数据集的局限性,它们的效果通常在应用于真实场景时受到阻碍。
中国的一支研究团队推出了“FreeMan”,这个由来自香港中文大学(深圳)和腾讯等机构的团队共同合作开发的项目,被誉为革新性的多视角数据集,旨在为3D人体姿势估计领域带来新的突破。
FreeMan是一个新颖的大规模多视角数据集,旨在解决现有数据集在真实场景中3D人体姿态估计方面的局限性。FreeMan是一项重要的贡献,旨在促进更准确和稳健模型的开发。
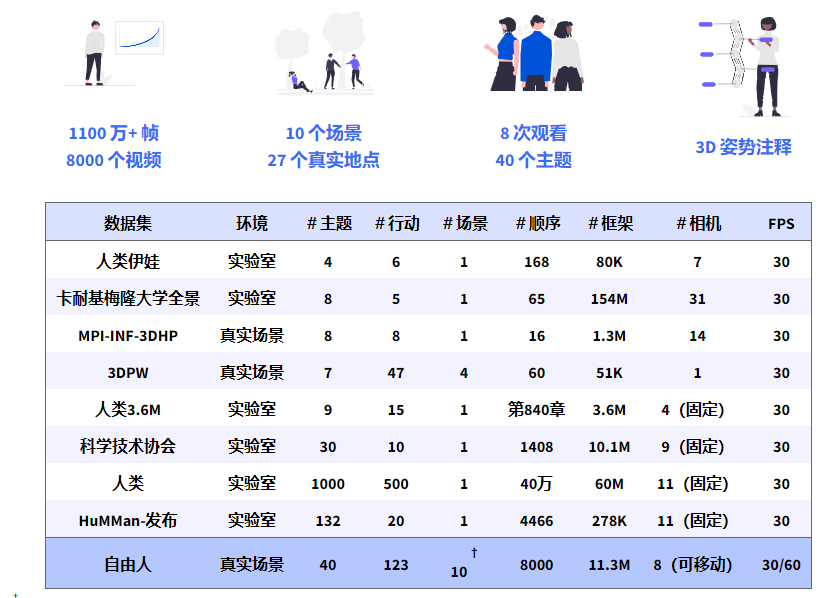
FreeMan项目的特点之一是其数据集的规模和多样性。该数据集由8部智能手机在不同场景下的同步录制组成,包括10个不同场景、27个真实场地,总计包含了超过1100万帧的视频。每个场景都涵盖了不同的照明条件,使得这个数据集成为一个独一无二的资源。
FreeMan数据集的开源是为了促进大规模预训练数据集的发展,同时也为户外3D人体姿势估计提供了全新的基准。这一数据集不仅包括视频,还提供了丰富的注解信息,包括2D和3D人体关键点、SMPL参数、边界框等,为研究人员提供了丰富的资源以推动相关领域的研究。
值得注意的是,FreeMan引入了相机参数和人体尺度的变化,使其更具代表性。研究团队开发了自动化的标注流程,以从收集的数据中高效生成精确的3D标注。这一流程包括人体检测、2D关键点检测、3D姿态估计和网格标注。由此产生的数据集对于多种任务都非常有价值,包括单目3D估计、2D到3D转换、多视角3D估计和人体主体的神经渲染。
研究人员提供了对FreeMan进行各种任务的全面评估基线。他们将在FreeMan上训练的模型与在Human3.6M和HuMMan上训练的模型的性能进行了比较。值得注意的是,在3DPW数据集上测试时,训练在FreeMan上的模型表现出显著更好的性能,突显了FreeMan在真实场景中的卓越泛化能力。

在多视角3D人体姿态估计实验中,与在Human3.6M上训练的模型相比,在跨领域数据集上测试时,训练在FreeMan上的模型表现出更好的泛化能力。结果一致显示了FreeMan多样性和规模的优势。
在2D到3D姿态转换实验中,FreeMan的挑战显而易见,因为在这个数据集上训练的模型面临更大的难度。然而,当模型在整个FreeMan训练集上进行训练时,其性能得到改善,显示出该数据集提高模型性能的潜力。
FreeMan的可用性预计将推动人体建模、计算机视觉和人机交互领域的进步,弥合了受控实验室条件与真实场景之间的差距。
项目网址:https://wangjiongw.github.io/freeman/
百度文心一言上线搜索、文生视频、图表制作等5大插件
在昨日的WAVESUMMIT深度学习开发者大会上,百度首席技术官王海峰表示,文心一言已上线百度搜索、览卷文档、E言易图、说图解画、一镜流影五大插件,使模型具备生成实时准确信息、长文本摘要和问答、数据洞察和图表制作、基于图片的创作和问答、文生视频等能力。王海峰表示,未来百度将与开发者共建插件生态,共享技术创新成果。站长网2023-08-17 08:31:000002AMD推出最新图形增强技术AMD FSR 3
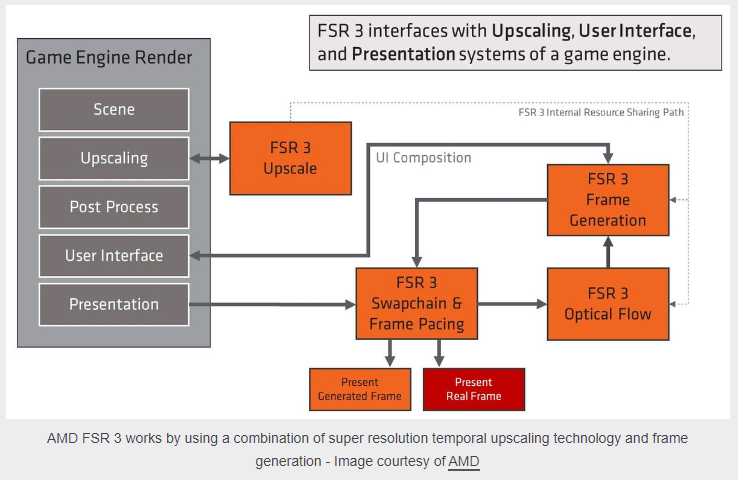
要点:AMDFSR3是AMD最新推出的图形增强技术,采用超分辨率时域上采样和帧生成相结合的方式提升游戏图形细节和性能。与NvidiaDLSS技术不同,AMDFSR3主要依赖上采样和帧生成技术,兼容AMD显卡,目前已支持《女武神》和《阿温诸神》两款游戏,后续将支持更多游戏。启用AMDFSR3非常简单,更新AMD显卡驱动,在游戏设置中启用AMDFSR3选项,即可获得更流畅的游戏体验。站长网2023-10-09 18:00:550000ChatGPT遭遇故障,数千名Open AI用户遭遇严重中断
划重点:⭐数千名ChatGPT用户因网站和应用遭遇重大故障而感到愤怒。⭐OpenAI确认正在调查故障,数千用户全球范围内受影响。⭐用户在社交媒体上纷纷发声,表达对ChatGPT故障的不满。数千名ChatGPT用户在今天早上因网站和应用遭遇严重故障而感到愤怒。站长网2024-06-05 12:31:140000Midjourney V6动漫微调模型Nijijourney V6正式上线
终于,MidjourneyV6的动漫微调模型NijijourneyV6正式上线了!这个新版本对提示词的响应更加出色,同时还能识别更多的风格。现在,用户可以通过在/settings中选择NijijourneyV6版本,或者使用Niji的discord机器人来体验这一全新的功能。站长网2024-01-30 10:24:510002报道:美国政府将就对微软、OpenAI 和英伟达展开反垄断调查
划重点:-🧐美国FTC和DOJ据报道将分工负责,分别对微软、OpenAI和英伟达展开反垄断调查-🤝FTC将调查OpenAI与其最大投资者微软之间的交易,而DOJ将主导对英伟达的调查-💼报道指出,此举并不代表拜登政府对这三家公司展开案件,但2019年的类似合作导致政府对谷歌、苹果、亚马逊和Meta提起了诉讼站长网2024-06-08 09:51:470000