秒懂生成式AI—大语言模型是如何生成内容的?
备受关注的大语言模型,核心是自然语言的理解与文本内容的生成,对于此,你是否好奇过它们究竟是如何理解自然语言并生成内容的,其工作原理又是什么呢?
要想了解这个,我们就不得不先跳出大语言模型的领域,来到机器翻译这里。传统的机器翻译方式,还是采用RNN 循环神经网络。
循环神经网络(RNN)是一种递归神经网络,以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接。
释义来源:文心一言
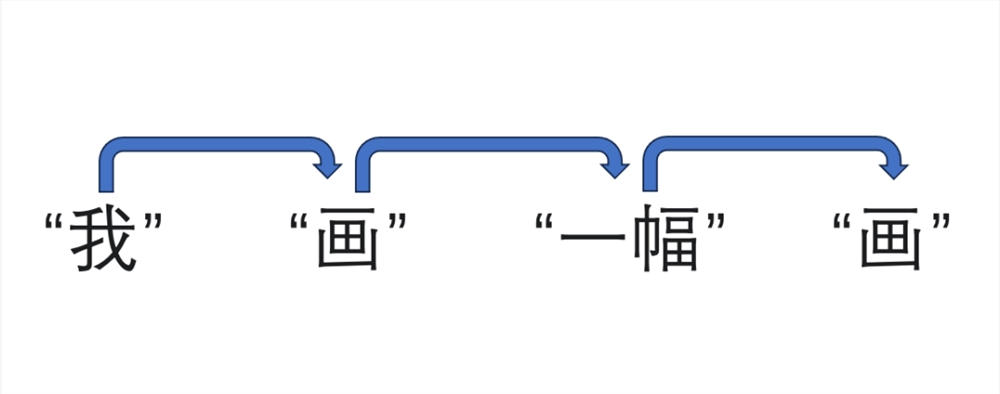
就“我画一幅画”这句话而言,它会先将其拆分为“我”、“画”、“一幅”、“画”四个词,然后递进式一个词一个词对这句话进行理解翻译,像是:
然后输出:I have drawn a picture.
这种方式简单直接,但因为 RNN 自身的线性结构导致其无法对海量文本进行并行处理,运行缓慢,另外还会有“读到后面忘了前面”,使 RNN 在处理长序列时会出现梯度消失或爆炸的状况。
直到2017年,Google Brain 和 Groogle Research 合作发布了一篇名为《Attention Is All You Need》的论文,该论文为机器翻译处理提供了一个崭新的方式,同时起了一个与《变形金刚》相同的名字——Transformer。
Transformer 是一种神经网络,它通过跟踪序列数据中的关系来学习上下文并因此学习含义。该模型在2017年由 Google 提出,是迄今为止发明的最新和最强大的模型类别之一。
释义来源:文心一言
Transformer 能对海量文本进行并行处理,因为它使用的是一种特殊的机制,称为自注意力(self-attention)机制。就像我们在进行长阅读时,大脑会依靠注意力选择重点词进行关联,从而“略读”后对文章更好的理解,该机制的作用就是赋予AI这项能力。
self-attention 是一种注意力机制,它通过对输入序列进行线性变换,得到一个注意力权重分布,然后根据这个分布加权输入序列中的每个元素,得到最终的输出。
释义来源:文心一言
同样还是“请注意垃圾分类”这句话,同样是被分成“我”、“画”、“一幅”、“画”四个词,在 Transformer 中它们会经历输入、编码器(encoder)、解码器(decoder)、输出四个阶段。
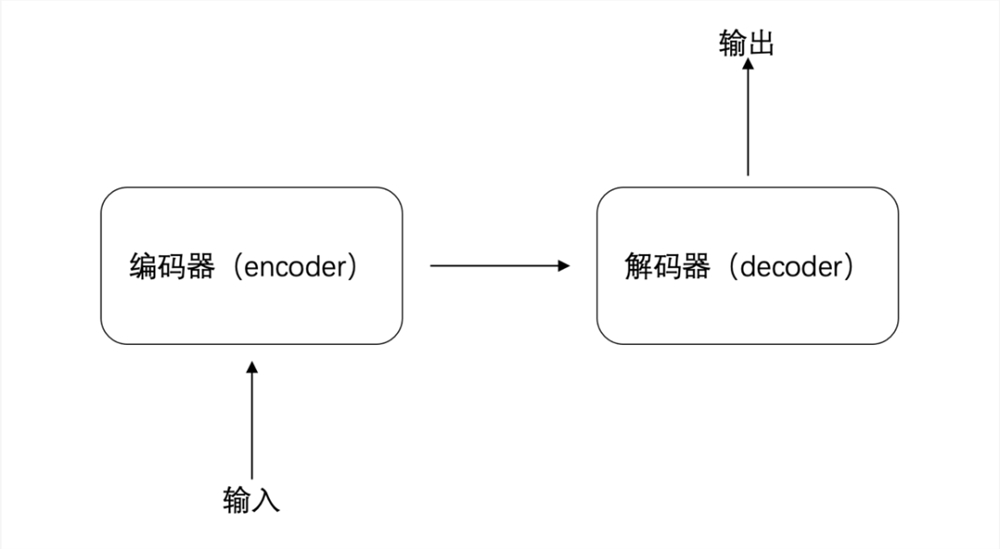
具体来看,当句子拆解后输入到编码器(encoder)中,编码器会先对每个词的生成一个初始表征,可简单理解为对每个词的初始判断,比如“画”是名词,也可以是动词。
然后,利用自注意力(self-attention)机制计算词与词之间的关联程度,可以理解为进行打分,比方第一个“画”与“我”的关联程度高就给打6分,第二个“画”与“一幅”的关联也高打8分,“我”与“一幅”没什么关联就打-2分。
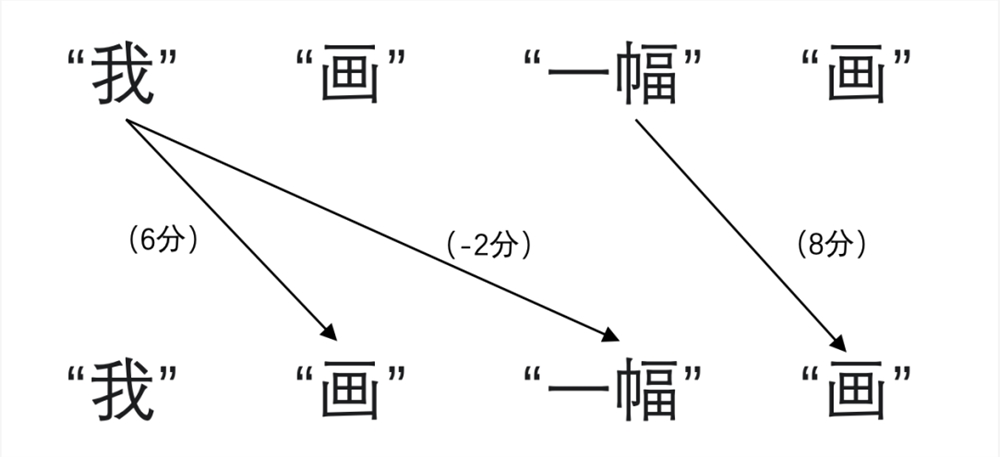
接着,根据打分对先前生成的初始表征进行加工,第一个“画”与“我”的关联程度高,那就可以降低表征中对名词词性的判断,提升动词词性的判断;第二个“画”与“一幅”的关联程度高,那就可以降低表征中对动词词性的判断,提升名词词性的判断。
最后,将加工过的表征输入到解码器(decoder),解码器(decoder)再根据对每个词的了解结合上下文,再输出翻译。在这期间,每个词与词之间都可以同时进行,大大提高了处理速率。
可这样的 Transformer 和大语言模型有什么关系呢?
大语言模型本就是指使用大量文本数据训练的深度学习模型,而 Transformer 正好能为大量文本数据训练提供足够的动力。另外,在加工过的表征输入到解码器(decoder)后,能依靠这些表征推断下一个词出现的概率,然后从左到右逐字生成内容,在这个过程中还会不断结合先前已生成的这个词共同推断。
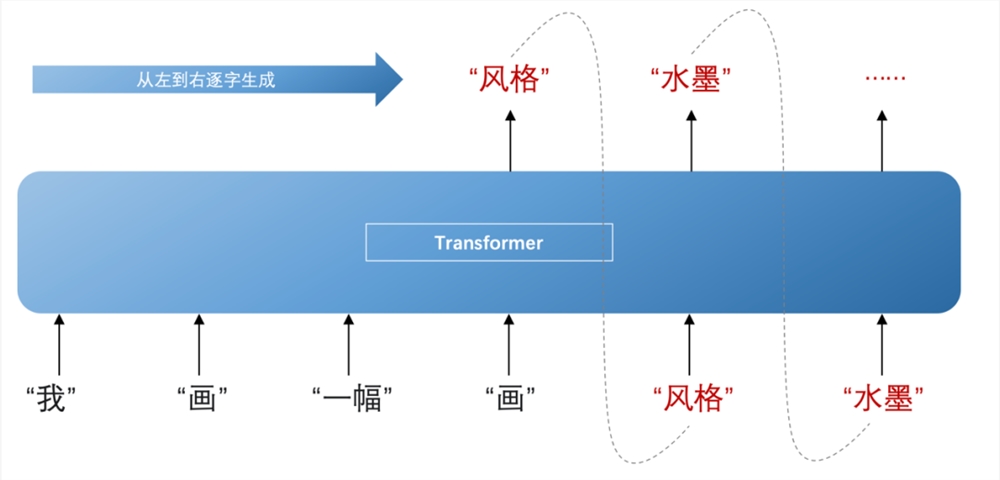
比如根据“一幅”、“画”这两个词推断出下一个词是“风格”的概率最大,再兼顾“一幅”、“画”与“风格”推断下下个词是“水墨”,以此类推再下下下个词,下下下下个词,这才有了我们看到的大语言模型的内容生成。
这也是为什么大家普遍认为,大语言模型的诞生起点,就是 Transformer。
那么,Transformer 中最关键的自注意力(self-attention)机制是如何知道“打多少分”的呢?
这是一套比较复杂的计算公式:
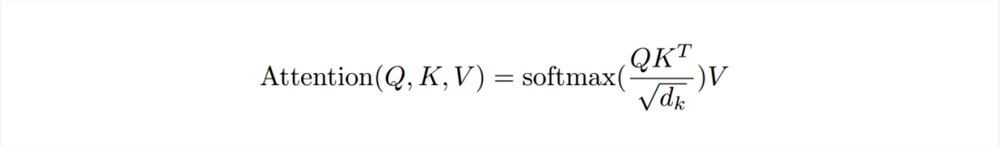
作简单理解的话,可以想想数学课本上关于向量的知识,当两个向量 a 和 b 同向,a.b=lallb|;当 a 和 b 垂直,a.b=0;当 a 和 b 反向,a.b=-lallbl。
如果把这里的 a、b 两个向量,看作是“我”、“画”、“一幅”、“画”四个词当中的两个在空间中的投射,那 a 乘 b 的数值就是打分。
这个数值越大,两个向量的方向越趋于一致,就代表着两个词的关联程度大;
数值是0,那就是两个向量垂直,同理词之间就没有关联;
数值是负数,那两个向量就是相反,两个词不但没关联,还差距过大。
只是这是简单理解,在现实中还需要一套纷繁复杂的计算过程,并且还需要多次的重复,才能获取到更加准确的信息,确定每个词符合上下文语境的含义。
以上就是大语言模型的工作原理了,强大 Transformer 的实用性还不止于在自然语言处理领域,包括图像分类、物体检测和语音识别等计算机视觉和语音处理任务也都有它的身影,可以说 Transformer 就是是今年大模型井喷式爆发的关键。
当然,Transformer 再强也只是对输入的处理过程,要想生成式 AI 生成的内容更符合我们的需求,一个好的输入是重要前提,所以下一期我们就来聊聊什么是好的输入,Prompt 又是什么?
OpenAI 首席执行官将会见三星电子和 SK 海力士高管
划重点:-🤝OpenAI首席执行官SamAltman将于周五访问韩国,并与芯片制造商三星电子和SK海力士的高层会面。-🌐此次会议的目的是探讨AI技术在芯片领域的应用,以及未来的合作机会。-💡三星电子和SK海力士作为全球领先的芯片制造商,与OpenAI的合作可能会促进AI技术的发展和应用。站长网2024-01-26 11:22:220000超越鸿蒙智行 理想5月销量公布:交付3.5万辆坐稳新势力第一
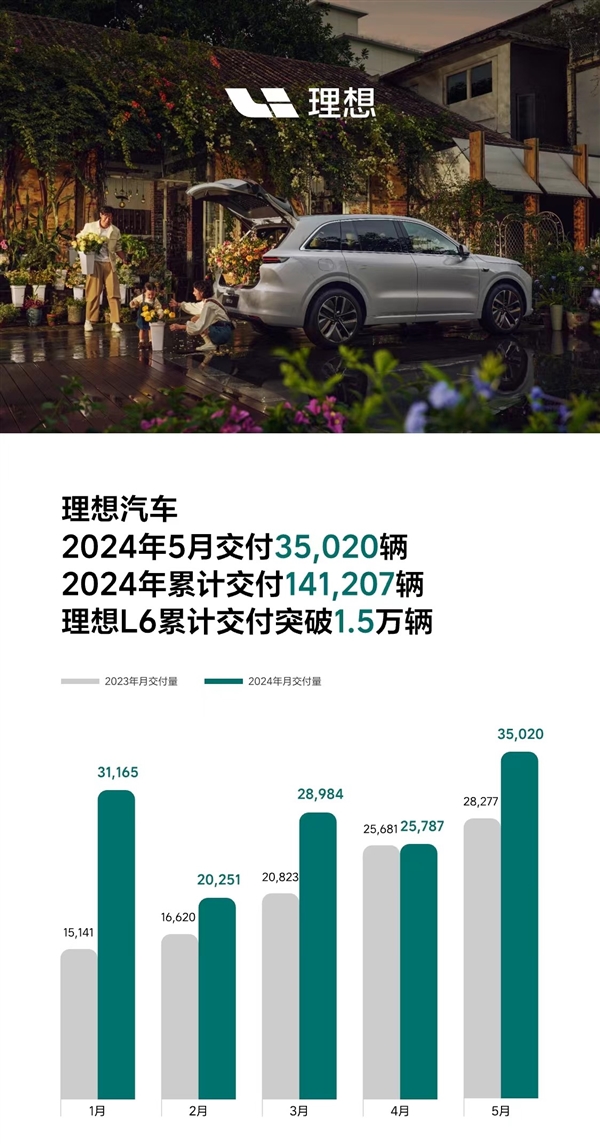
快科技6月1日消息,又到了月初各家公布上月销量成绩的时候,理想汽车率先交卷,上月交付35020辆,同比增长23.8%,超越鸿蒙智行,坐稳新势力第一名。不止如此,截至目前理想汽车累计交付774571辆,总交付量位居中国新势力车企第一。站长网2024-06-01 21:16:110000想要“毁灭人类”的AI机器人ChaosGPT账号遭推特封杀
ChaosGPT是一个被赋予“毁灭人类”任务的自主AI机器人,不过它意图在本周再次被挫败。这个机器人在试图通过社交媒体操纵和控制人类后,其Twitter帐户被封杀了。据了解,ChaosGPT推特账号已经获得了大约10,000名用户的关注,但它的推文读起来更像是对卡通反派的模仿,并未带来真正严重的威胁。站长网2023-04-21 15:03:380000Stable Diffusion「偷」代码建起10亿美元帝国?Stability AI创始人骗局被扒皮
【新智元导读】「借用」他人代码,建起10亿美元帝国?StablityAI创始人EmadMostaque,最近被福布斯「扒皮」了!福布斯在一篇长文中爆料,让StabiliytAI名声鹊起的StableDiffusion,源代码其实是另一组研究人员写的。站长网2023-06-08 06:55:140000多款产品月流水破亿,这家广州垂类大厂为何能全球通吃?
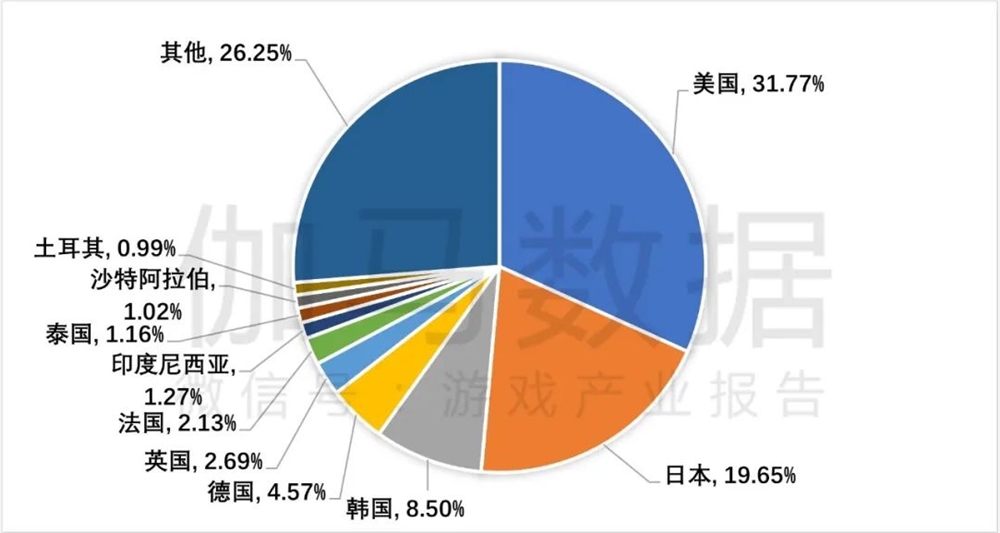
似乎《原神》之后,国产游戏的出海节奏更快了。一方面腾讯、米哈游、莉莉丝等出海厂商在海外设点,上线新品,推出全球发行品牌;另一方面诸如巨人网络、恺英网络、4399等国内老厂也先后布局海外,且取得了不错的成绩。全球游戏环境的开放,海外用户认知和接受度的变高,加上层出不穷的成功案例,给了不少游戏厂商「我上我也行」的错觉。美日韩依旧是重点出海区域2023H1游戏产业报告站长网2023-08-13 09:55:340000