视觉Transformer中ReLU替代softmax,DeepMind新招让成本速降
Transformer 架构已经在现代机器学习领域得到了广泛的应用。注意力是 transformer 的一大核心组件,其中包含了一个 softmax,作用是产生 token 的一个概率分布。softmax 有较高的成本,因为其会执行指数计算和对序列长度求和,这会使得并行化难以执行。
Google DeepMind 想到了一个新思路:用某种不一定会输出概率分布的新方法替代 softmax 运算。他们还观察到:在用于视觉 Transformer 时,使用 ReLU 除以序列长度的注意力可以接近或匹敌传统的 softmax 注意力。

论文:https://arxiv.org/abs/2309.08586
这一结果为并行化带来了新方案,因为 ReLU 注意力可以在序列长度维度上并行化,其所需的 gather 运算少于传统的注意力。
方法
注意力
注意力的作用是通过一个两步式流程对 d 维的查询、键和值 {q_i, k_i, v_i} 进行变换。
在第一步,通过下式得到注意力权重
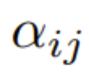
:
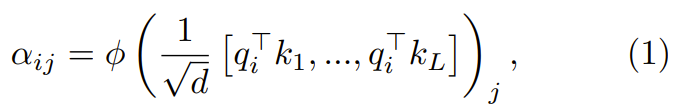
其中 ϕ 通常是 softmax。
下一步,使用这个注意力权重来计算输出
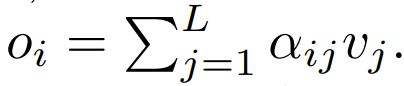
这篇论文探索了使用逐点式计算的方案来替代 ϕ。
ReLU 注意力
DeepMind 观察到,对于1式中的 ϕ = softmax,
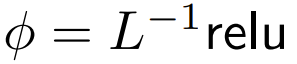
是一个较好的替代方案。他们将使用
的注意力称为 ReLU 注意力。
已扩展的逐点式注意力
研究者也通过实验探索了更广泛的

选择,其中 α ∈ [0,1] 且 h ∈ {relu,relu² , gelu,softplus, identity,relu6,sigmoid}。
序列长度扩展
他们还观察到,如果使用一个涉及序列长度 L 的项进行扩展,有助于实现高准确度。之前试图去除 softmax 的研究工作并未使用这种扩展方案。
在目前使用 softmax 注意力设计的 Transformer 中,有

,这意味着

尽管这不太可能是一个必要条件,但
能确保在初始化时
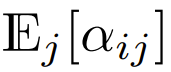
的复杂度是

,保留此条件可能会减少替换 softmax 时对更改其它超参数的需求。
在初始化的时候,q 和 k 的元素为 O (1),因此

也将为 O (1)。ReLU 这样的激活函数维持在 O (1),因此需要因子

才能使
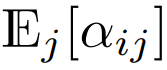
的复杂度为
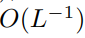
。
实验与结果
主要结果
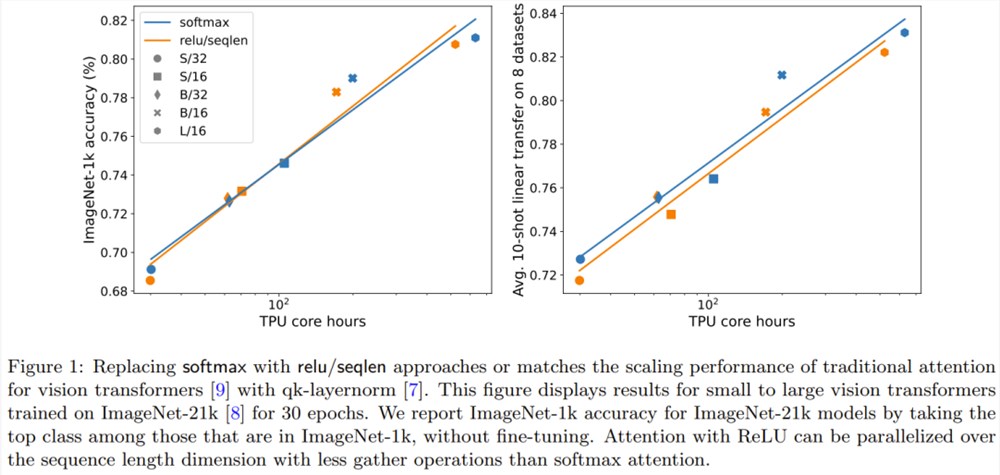
图1说明在 ImageNet-21k 训练方面,ReLU 注意力与 softmax 注意力的扩展趋势相当。X 轴展示了实验所需的内核计算总时间(小时)。ReLU 注意力的一大优势是能在序列长度维度上实现并行化,其所需的 gather 操作比 softmax 注意力更少。
序列长度扩展的效果
图2对比了序列长度扩展方法与其它多种替代 softmax 的逐点式方案的结果。具体来说,就是用 relu、relu²、gelu、softplus、identity 等方法替代 softmax。X 轴是 α。Y 轴则是 S/32、S/16和 S/8视觉 Transformer 模型的准确度。最佳结果通常是在 α 接近1时得到。由于没有明确的最佳非线性,所以他们在主要实验中使用了 ReLU,因为它速度更快。

qk-layernorm 的效果
主要实验中使用了 qk-layernorm,在这其中查询和键会在计算注意力权重前被传递通过 LayerNorm。DeepMind 表示,默认使用 qk-layernorm 的原因是在扩展模型大小时有必要防止不稳定情况发生。图3展示了移除 qk-layernorm 的影响。这一结果表明 qk-layernorm 对这些模型的影响不大,但当模型规模变大时,情况可能会不一样。

添加门的效果
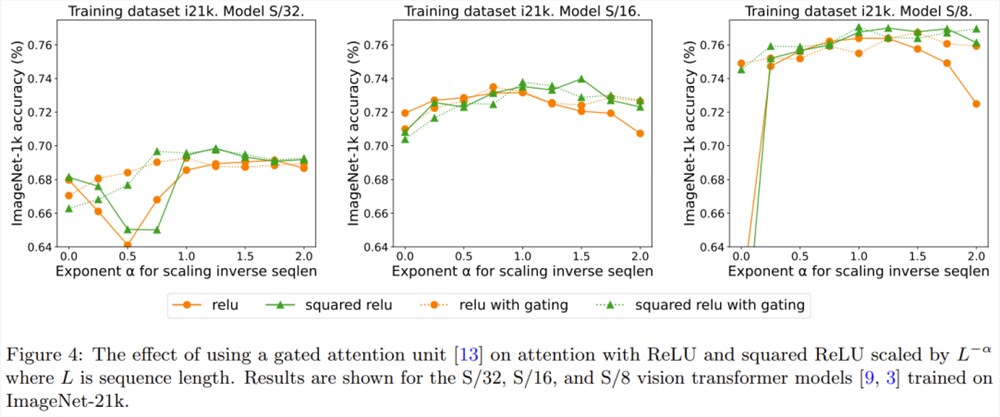
先前有移除 softmax 的研究采用了添加一个门控单元的做法,但这种方法无法随序列长度而扩展。具体来说,在门控注意力单元中,会有一个额外的投影产生输出,该输出是在输出投影之前通过逐元素的乘法组合得到的。图4探究了门的存在是否可消除对序列长度扩展的需求。总体而言,DeepMind 观察到,不管有没有门,通过序列长度扩展都可以得到最佳准确度。也要注意,对于使用 ReLU 的 S/8模型,这种门控机制会将实验所需的核心时间增多大约9.3%。
LG集团推出AI产品Exaone 2.0 将用于药物及新材料研发
韩国第四大财团LG集团,周三推出了一款升级版的超大规模人工智能Exaone2.0,用于其未来的增长引擎,如新药和新材料。LG集团控股公司LGCorp.的研究机构LGAIResearch展示了Exaone2.0,一款改进版的超巨型人工智能,该集团计划在今年将其应用于其旗下各个单位。其早期版本于2021年12月推出。站长网2023-07-20 15:37:060000谷歌让大模型更具“心智”,GPT-4任务准确率大增
谷歌联合多所高校的一项最新研究,让大模型开始拥有了人类的“心智”。在新的提示策略下,大模型不仅能推测出人类所面临的问题,还学会了用推测的结论调整自己的行为。有了这一成果,GPT-4的“心智”水平已经提高到了人类的71%。具体来说,研究人员发现,现在的大模型,已经具备了在对话中推测人类“在想啥”的能力。但如果你要它根据这种推理给出行动建议,那可就难倒大模型了。站长网2023-10-15 15:19:200000首发新款麒麟5G芯片!华为nova 12 Ultra入网
华为nova12Ultra正式通过国家质量认证,预示着其即将上市。该机型型号为ADA-AL00U,支持5G,并将搭载新款麒麟5G芯片。据爆料,这款麒麟芯片可能是降频版的麒麟9000S,其主频略有降低,但整体使用体验差距不会太大。华为nova12Ultra作为nova系列的旗舰机型,其性能和功能将进一步升级,可能会支持Mate60Pro的卫星通话功能,为用户提供更加便捷的通讯体验。站长网2023-11-30 10:28:510000南开山大等开发trRosettaRNA 一种基于深度学习的自动化RNA 3D结构预测方法
要点:南开大学、山东大学以及北京理工大学联合团队研发了trRosettaRNA,一种基于深度学习的自动化RNA3D结构预测方法,通过Transformer网络实现1D和2D几何形状预测,再通过能量最小化进行3D结构折叠。站长网2023-11-27 09:36:590000上热搜了!网友盘点iPhone羡慕安卓的功能:一只手都数不过来
快科技7月21日消息,微博话题iPhone羡慕安卓的功能”上了热搜榜。有网友盘点了国产安卓手机已有、iPhone却不具备的功能,轻松一盘点就多达十几项,具体如下:1、高频PWM调光/类DC调光;2、1英寸大底主摄;3、全功能NFC;4、红外遥控;5、快充;6、散热;7、USB3.2Gen1;8、应用多开;9、高刷策略;10、右侧返回;11、信号;12、长截屏;站长网2023-07-22 16:45:150000