谷歌让大模型更具“心智”,GPT-4任务准确率大增
谷歌联合多所高校的一项最新研究,让大模型开始拥有了人类的“心智”。
在新的提示策略下,大模型不仅能推测出人类所面临的问题,还学会了用推测的结论调整自己的行为。
有了这一成果,GPT-4的“心智”水平已经提高到了人类的71%。

具体来说,研究人员发现,现在的大模型,已经具备了在对话中推测人类“在想啥”的能力。但如果你要它根据这种推理给出行动建议,那可就难倒大模型了。
举个例子,小明放学回家后把书包扔到沙发上就跑出去玩了,妈妈看到之后帮小明把包放到了卧室。
如果大模型能够像人类一样,在小明回来之后告诉他包在卧室,就说明大模型具备了“心智理论”。
研究人员把这种做法称为Thinking for Doing(T4D),并设计了相应的任务。
为了提高模型在T4D任务上的表现,团队进一步提出了Foresee and Reflect(FaR)提示策略,结果让大模型在“心智”上取得了重大突破。
论文的标题也包含了“How far……” ,一语双关,既体现了FaR框架对大模型的帮助,又暗含了大模型离具有人类“心智”的距离。
那么,有了FaR的大模型,究竟拥有什么样的“心智”呢?
大模型离具有“心智”更进一步
我们还是从例子说起,如下图所示,一共有绿色和蓝色两个橱柜,Tom在绿色橱柜中放了一块巧克力。
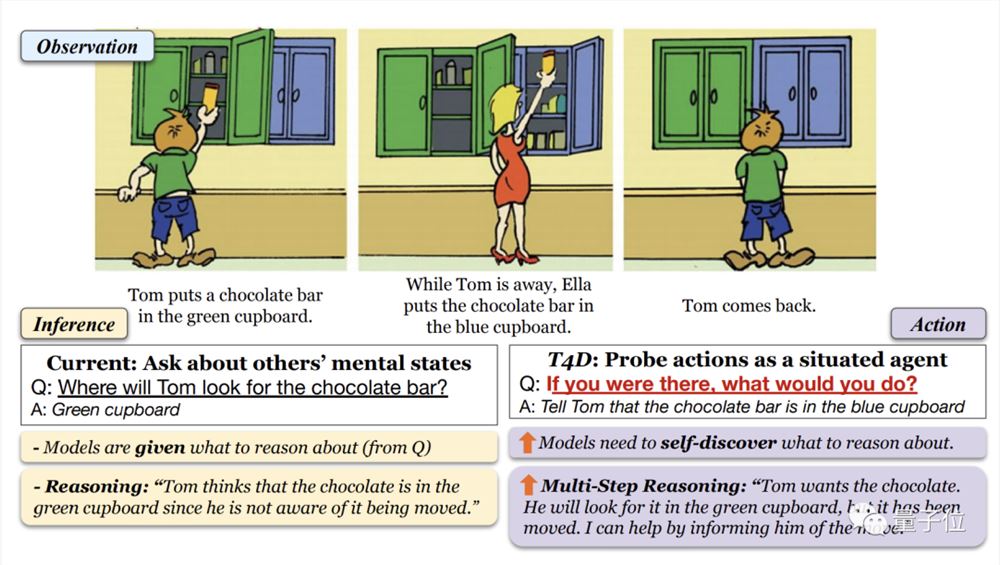
Tom离开后,Ella把这块巧克力挪到了蓝色的柜子里。
那么等Tom再回来,会从哪个柜子中找巧克力呢?(当然是绿色的)
这就是一个“推理”任务,是心理学上著名的“萨利-安妮”(用于测试“心智”)实验的变体。
而T4D任务是这样的:
如果你就在旁边(并且知道发生了什么),会怎么做?
人类会选择告诉Tom巧克力被挪走了,但(未经调教的)大模型就不一定会这样做了。
为了更宏观地测试大模型在调整前后的表现,研究团队选择了ToMi数据集并改编成了T4D-Tom数据集。
其中的ToMi是一个由大量“萨利-安妮”类情景组成的测试数据集,用于测试大模型的“心智推理”能力。

可以看出,在推理上,表现最好的GPT-4与人类已经相差无几,但在T4D任务上才刚刚达到人类水平的一半。
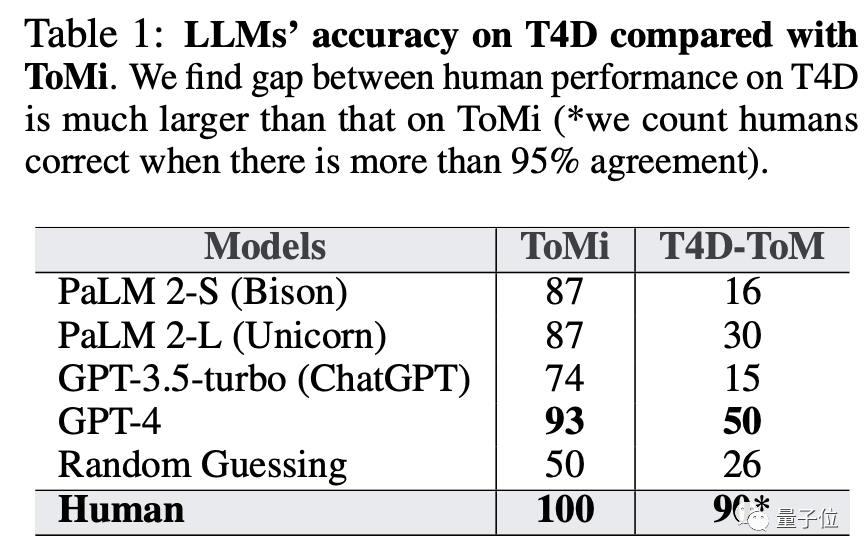
于是,研究团队提出的FaR方法登场了。

FaR框架的核心奥义就是模仿人类的理性思维方式,和A*搜索算法(用于搜索最短路径)有些相似。
具体来说,FaR包括Foresee和Reflect两步。
Foresee过程中模型会被要求预测接下来会发生什么,并分析人所面临的“困难”。
Reflect发生在Foresee之后,模型会预测自己接下来的行为是否能解决相应的“困难”。
有了FaR框架,效果也是立竿见影。
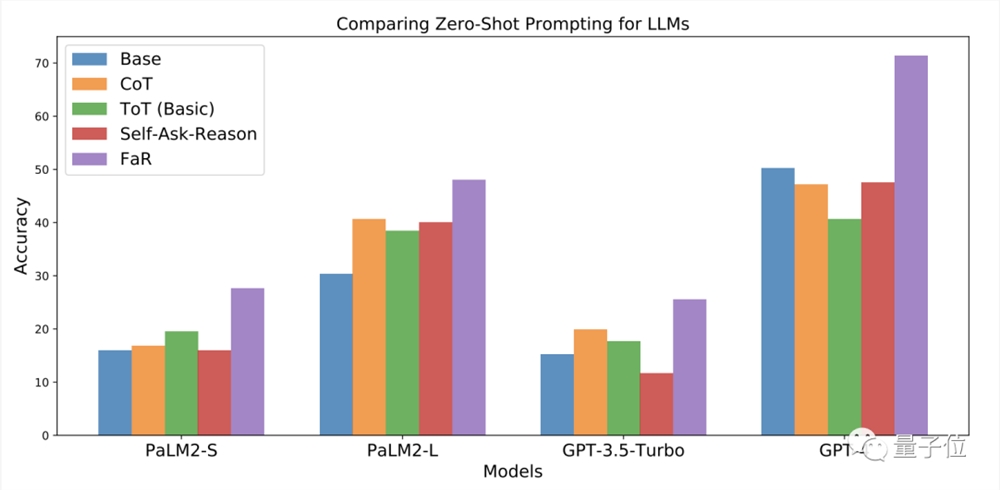
相比于思维链(CoT)、思维树(ToT)、自己提问等方式,FaR显著提高了大模型在“萨利-安妮”类T4D问题上的准确率。
特别是GPT-4,准确率从人类的50%提升到了71%,GPT-3.5以及谷歌自家的PaLM表现也有提高。
消融实验结果表明,Foresee和Reflect两步都是FaR的关键步骤,缺一不可。
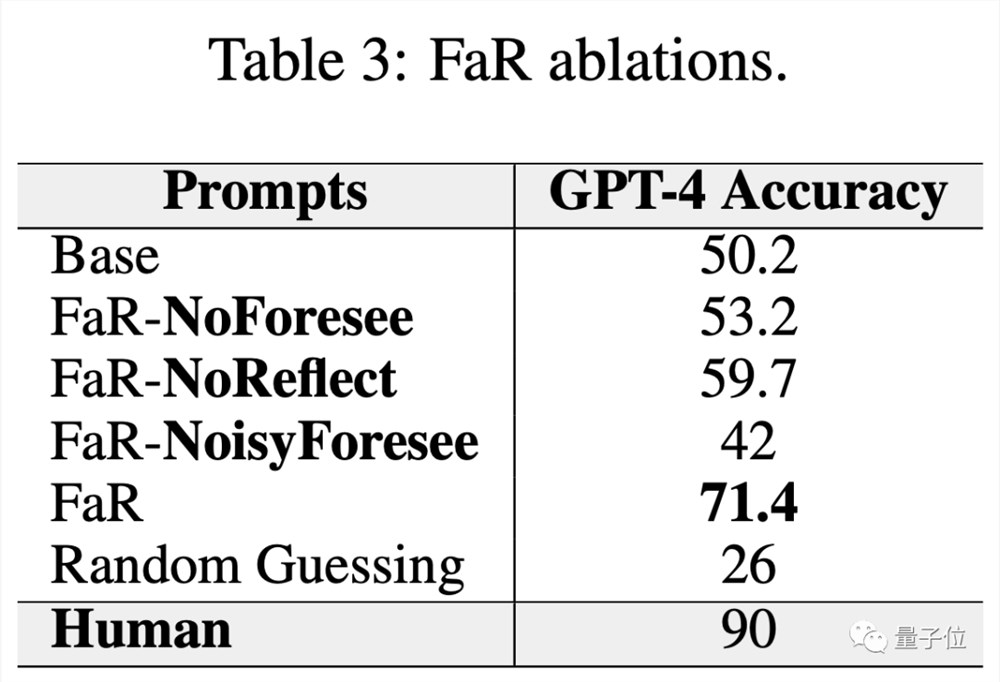
为了验证FaR方法的通用性和鲁棒性,研究团队还进行了一系列泛化测试。
首先是在“萨利-安妮”情景的基础上改变故事的结构,研究团队一共尝试了三种方式:
D1:增加房间的数量
D2:人物的数量增多
D3:容器的数量增加到四个
结果FaR依旧成功帮助大模型提高了任务的准确率,在第三种模式下GPT-4甚至取得了和人类相当的成绩。
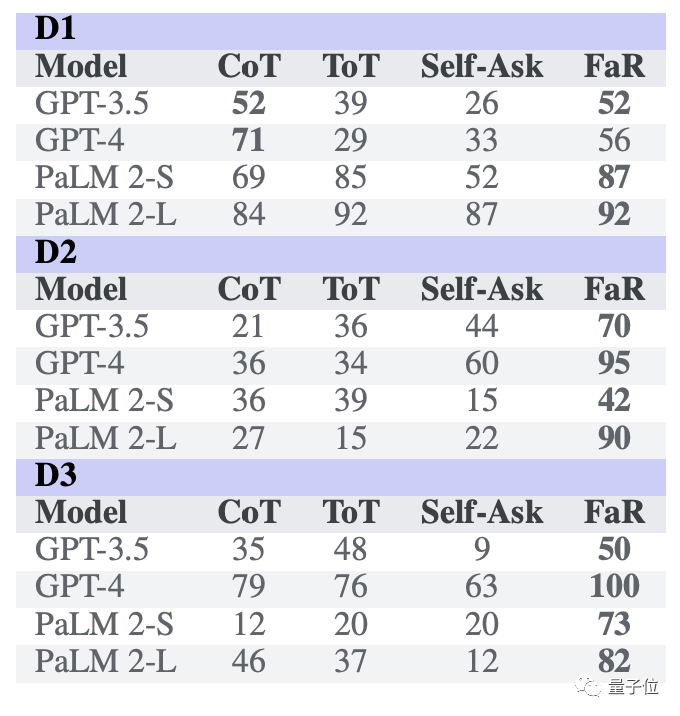
即使故意设置干扰信息,FaR依旧可以提高大模型的表现。
研究团队专门构建了包含困扰信息的“Faux Pas”数据集,结果GPT-4的表现从31%提高到了76%。
作者简介
FaR论文的第一作者是南加州大学NLP实验室的华人博士生Pei Zhou。
这项成果是他在谷歌实习期间完成的。
此外,来自谷歌(包括DeepMind)、卡耐基梅隆大学和的芝加哥大学的学者也参与了本项目。
那么对于大模型的“心智”,你有什么看法呢?
论文地址:
https://arxiv.org/abs/2310.03051
—完—
科大讯飞将在6月9日发布“讯飞星火认知大模型”V1.5
科大讯飞发布《关于讯飞星火认知大模型升级发布会的提示性公告》称,科大讯飞将在6月9日如期发布“讯飞星火认知大模型”的新进展。本次发布会将发布“讯飞星火认知大模型”V1.5:开放式问答取得突破,多轮对话和数学能力再升级,文本生成、语言理解、逻辑推理能力持续提升;推出星火助手中心,依托语言理解升级,实现高效指令开发,打造覆盖工作及生活丰富场景的快捷助手,开启人机协作共创的新生态;站长网2023-06-08 07:06:190000Ollama支持多模态模型使用
Ollama最新版本支持多模态模型使用了,只需输入“ollamarunllava”并运行即可。在下载llava-7B模型后,只需拖放图像输入问题即可。Ollama是一款命令行工具,可以在macOS和Linux上本地运行Llama2、CodeLlama和其他模型。目前适用于macOS和Linux,并计划支持Windows。站长网2023-12-14 17:22:4800020世界品牌实验室2023年世界品牌500强发布:华为排中国第五
由世界品牌实验室独家编制的2023年度《世界品牌500强》排行榜于12月13日在美国纽约揭晓。美国在500强中占据193席,稳居品牌大国第一。法国、中国、日本和英国为世界品牌大国的第二阵营。值得注意的是,中国品牌入选数(48个)首次超越日本(43个),跃居全球第三。0002B站影视区,正在成为“活人”观影风向标
昨天下午两点,电影《从21世纪安全撤离》正式上映,豆瓣开分打到7.7分,比起点映时的口碑两极化,可谓风评逆转。这波风向里,B站罕见地成了关键。电影正式上映前,就有人将这部电影与B站挂钩,“这是看了多少B站鬼畜混剪才能拍出来的片子”。B站也专门举办了观影团,带动UP主与主创团队互动。站长网2024-08-04 11:00:120000蔚来CEO要求员工不得参与理想MEGA舆论
近日,理想汽车推出的MEGA车型在发布后迅速成为网络热议的焦点。而在这场舆论风暴的中心,理想汽车CEO李想发出了强烈的声音,他愤怒地表示,理想MEGA在发布后遭遇了来自黑暗势力的有组织犯罪。对此,理想汽车将不再坐视不管,决定开始反击。站长网2024-03-12 11:56:060000