全新推理时Scaling论文联手清华震撼发布

热点
2个百度T11推出智能体火爆硅谷!免费使用无需邀请码,靠AI搜索功底估值已破38亿
2025-04-06 10:16:23小红书拟支持平台关闭“非正常购买”订单
2025-04-06 10:09:56Windows 11愈发受游戏玩家欢迎!Steam占比已达55.34%
2025-04-06 10:09:28全球市场遭遇黑色星期五!美股三大指数大跌 油价重挫
2025-04-06 09:13:51特朗普关税重创全球前500名富豪:马斯克最惨 身家暴跌千亿
2025-04-06 09:13:50注意听语音提醒!美团、叮咚买菜等平台上线反诈提示
2025-04-06 09:13:50美图云修7.0版本上线:修图效率提升79%
2025-04-06 09:13:49OpenAI的吉卜力,撞车了被字节起诉“投毒AI”的前实习生?
2025-04-04 09:29:42啊?小红书水下笔记能投聚光了?
2025-04-04 09:28:44YY正式并入百度后“首秀”:坚守直播阵地,加速布局短剧
2025-04-04 09:24:13
关注
网上晒图要当心!AI六成可能知道你在哪儿
2025-03-31 14:59:17
圣剑出鞘!任天堂真人《塞尔达传说》定档,情报竟藏App深处!
2025-03-31 12:48:52Claude深度“开盒”,看大模型的“大脑”到底如何运作?
2025-03-31 14:04:31苹果前首席工程师孔龙加盟复旦大学微电子学院
2025-03-31 12:48:44AIGC第一股年报详解:AIGC业务暴涨88.5%营收2.2亿,95%智能硬件交付出海,跑通规模化「软件订阅+出海」
2025-03-31 13:59:28库克现身杭州,探访中国AI重镇并会晤浙大学子
2025-03-31 12:48:15马斯克xAI蛇吞𝕏:资本有了,数据有了,商业模式也有了
2025-03-31 13:55:20微信聊天消息自动翻译功能上线 支持18种语言
2025-03-31 12:43:22
信息差小生意:用1块钱赚到20万(附教程)
2025-03-31 13:50:16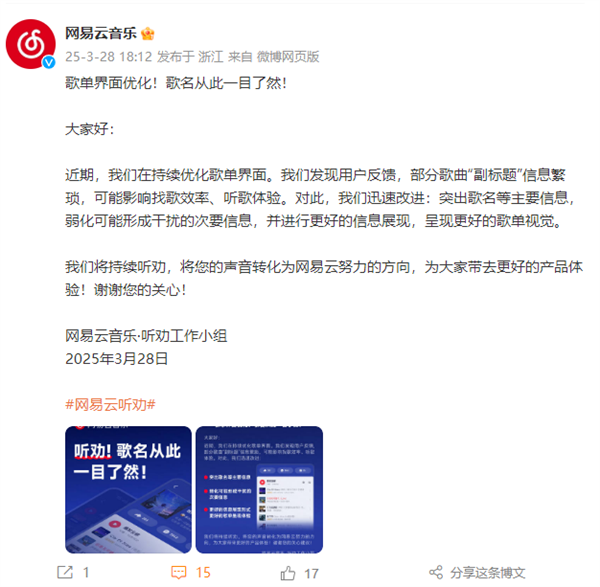
网易云音乐听劝了:优化了歌单界面 歌名一目了然
2025-03-31 12:42:53
推荐
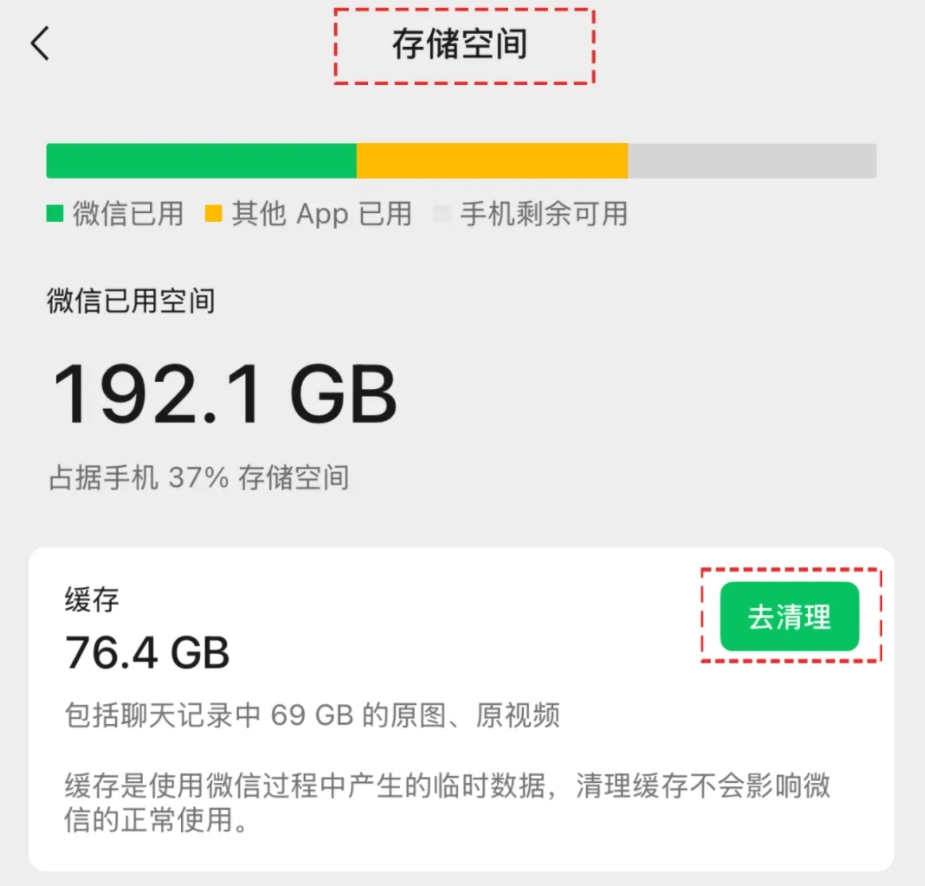
微信官宣瘦身!微信批量清理原图新功能来了
网上晒图要当心!AI六成可能知道你在哪儿

Manus回应邀请码:称将逐步有序释放 从未开设任何付费渠道
Claude深度“开盒”,看大模型的“大脑”到底如何运作?
小米15Ultra获MWC大奖 海外售价1.1万元起超iPhone
AIGC第一股年报详解:AIGC业务暴涨88.5%营收2.2亿,95%智能硬件交付出海,跑通规模化「软件订阅+出海」

全球通用AI助手发布 中国AI产品Manus一夜刷屏
马斯克xAI蛇吞𝕏:资本有了,数据有了,商业模式也有了

苹果全新iPad Air发布:搭载M3芯片 售价4799元起
信息差小生意:用1块钱赚到20万(附教程)