字节与浙大联合推多模态大语言模型Vista
字节与浙大联合推多模态大语言模型Vista-LLaMA 可解读视频内容
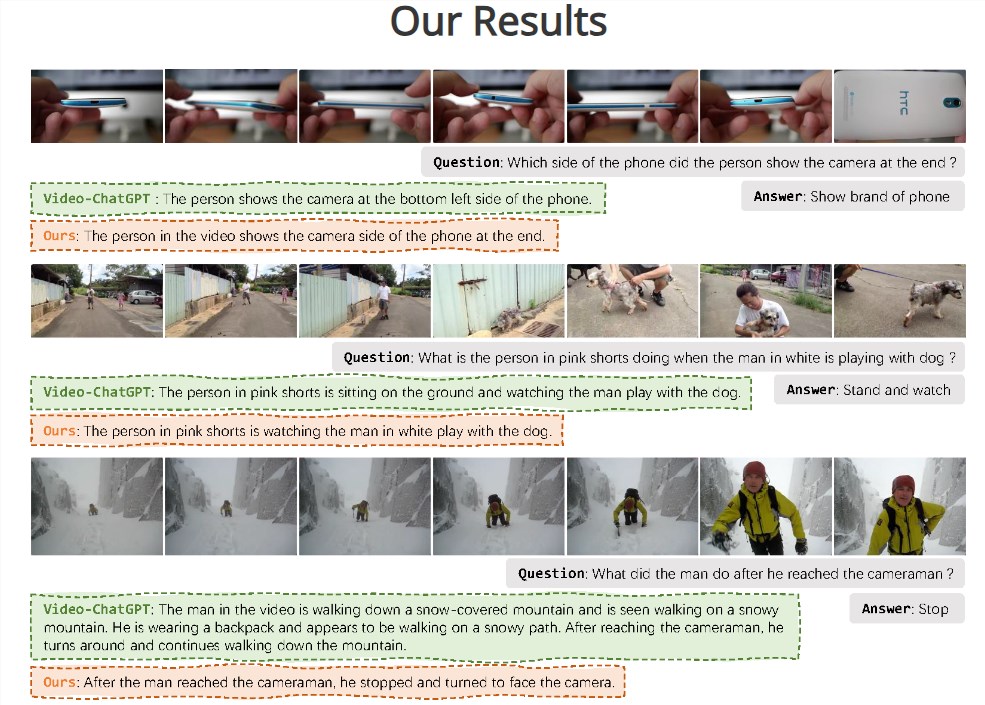
**划重点:**-💡Vista-LLaMA是一种专为视频内容理解而设计的多模态大语言模型,能够输出高质量视频描述。-🔬通过创新的视觉与语言token处理方式,Vista-LLaMA解决了在视频内容中出现“幻觉”现象的问题。-🚀改良的注意力机制和序列化视觉投影器提高了模型对视频内容的深度理解和时序逻辑把握。站长网2024-01-08 17:26:080008

热点
前Meta高管:如果强制执行版权许可, AI行业将“一夜之间垮掉”!
2025-05-28 17:01:41调查显示:80% 的 Z 世代愿意与 AI 结婚
2025-05-29 14:58:09微软将 Wins11 的“智能应用控制”夸大宣传为“杀毒解决方案”
2025-05-29 14:57:31腾讯将收购 Hybe 持有的所有 SM 股份,规模达 2433 亿韩元
2025-05-29 14:56:32小米张国全:澎湃OS 2发布以来改善1858项体验问题
2025-05-29 14:52:53“不要以关税为借口提高iPhone价格”,白宫再次向苹果施压
2025-05-28 17:18:18WordPress 宣布组建 AI 团队
2025-05-28 17:10:02Salesforce 以 80 亿美元收购数据公司 Informatica
2025-05-28 17:06:28OpenAI 或将推出“使用ChatGPT登录”功能,支持第三方应用接入
2025-05-28 17:00:43Anthropic 开始给 Claude 搞“语音模式”了
2025-05-28 16:57:18
关注
Mythik获1500万美元种子轮融资,要成为“东方迪士尼”
2025-05-26 15:15:05
手机满意度跌至 10 年来的水平,AI人工智能只是部分原因
2025-05-26 15:13:49
OpenAI 进军硬件领域,将收购 Jony Ive 的 AI 创业公司
2025-05-26 15:13:15蜜雪冰城回应网友倒卖柠檬水赚差价,网友:这违法吗?
2025-05-26 15:13:06
苹果开放 AI 模型……计划于下个月在 WWDC 上发布
2025-05-26 15:12:02马斯克:特斯拉将于 6 月底在奥斯汀启动 Robotaxi 试点
2025-05-26 15:11:44
谷歌推出 Beam AI:将普通视频通话,转为逼真的 3D 沉浸式体验
2025-05-26 15:10:44本田大幅削减电动汽车投资,将重点转向混合动力汽车及柔性制造
2025-05-26 14:29:29骆歆 Rita 领衔!《剑侠情缘?零》明星主播天团助阵公测
2025-05-26 14:28:30谷歌推出 250 美元的 AI Ultra 套餐,重新定义“高端”
2025-05-26 14:25:26


