字节与浙大联合推多模态大语言模型Vista-LLaMA 可解读视频内容
**划重点:**
- 💡 Vista-LLaMA是一种专为视频内容理解而设计的多模态大语言模型,能够输出高质量视频描述。
- 🔬 通过创新的视觉与语言token处理方式,Vista-LLaMA解决了在视频内容中出现“幻觉”现象的问题。
- 🚀 改良的注意力机制和序列化视觉投影器提高了模型对视频内容的深度理解和时序逻辑把握。
在自然语言处理领域,大型语言模型如GPT、GLM和LLaMA等的成功应用已经取得了显著的进展。然而,将这些技术扩展到视频内容理解领域则是一项全新的挑战。字节跳动与浙江大学合作推出的Vista-LLaMA多模态大语言模型旨在解决这一问题,实现对视频的深度理解和准确描述。
技术创新路径:
在处理视频内容时,传统模型存在一个问题,随着生成文本长度的增加,视频内容的影响逐渐减弱,产生了“幻觉”现象。为解决这一问题,Vista-LLaMA通过独特的视觉与语言token处理方式,维持视觉和语言token之间的均等距离,避免了文本生成中的偏差。该模型还采用改良的注意力机制和序列化视觉投影器,提高了模型对视频内容的深度理解和时序逻辑把握。
基准测试结果:
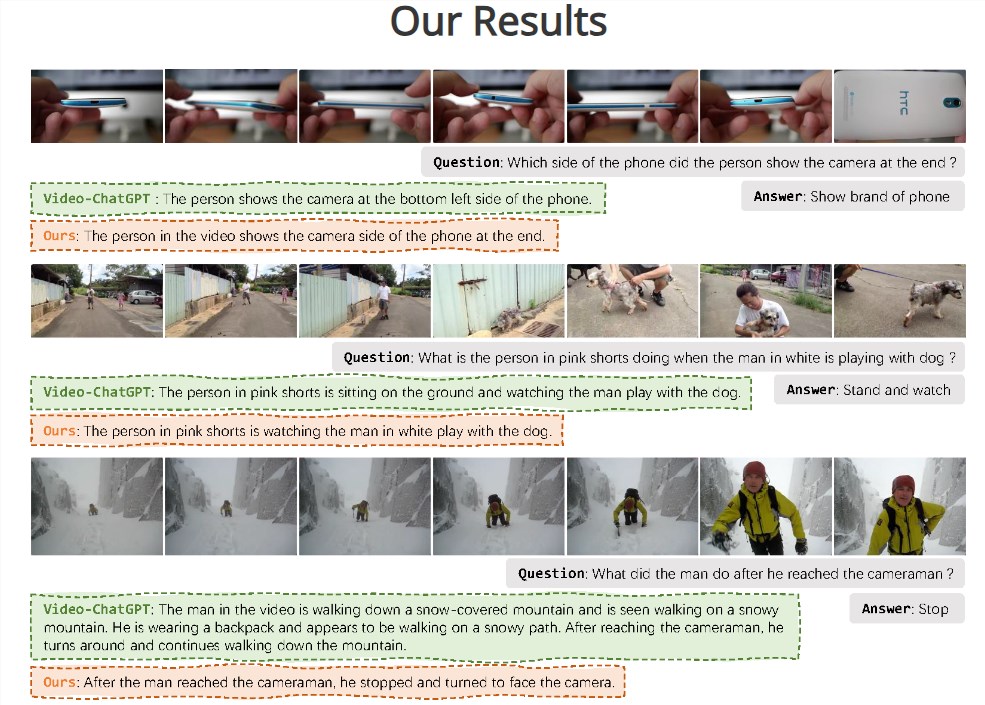
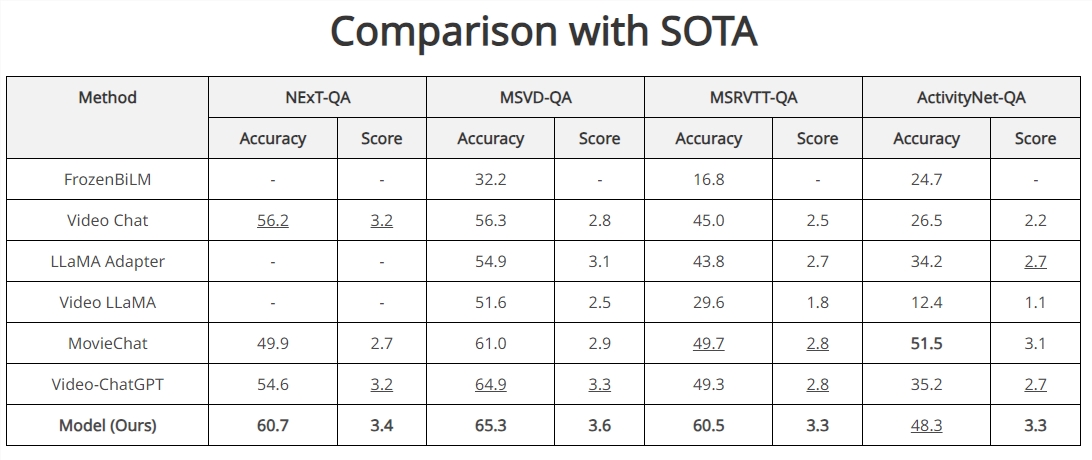
Vista-LLaMA在多个开放式视频问答基准测试中表现卓越,尤其在NExT-QA和MSRVTT-QA测试中取得了突破性成绩。其在零样本NExT-QA测试中实现了60.7%的准确率,在MSRVTT-QA测试中达到了60.5%的准确率,超过了目前所有的SOTA方法。这些结果证明了Vista-LLaMA在视频内容理解和描述生成方面的高效性和精准性。
CineClipQA新数据集:
Vista-LLaMA的提出伴随着CineClipQA新数据集的发布,该数据集包含了来自五部电影的153个视频片段,每个片段附有16个定制问题,共计2448个问题。这一数据集为多模态语言模型的发展提供了更丰富的训练和测试资源。
Vista-LLaMA的出现为视频内容理解和生成领域带来了新的解决框架,推动了人工智能在视频处理和内容创作方面的发展。其在长视频内容方面的显著优势为未来多模态交互和自动化内容生成领域提供了广泛的机遇。
B站发布2024年Q1财报:月活用户、日均使用时长双双再创新高
快科技5月23日消息,B站公布截至2024年3月31日的第一季度未经审计的财务报告。财报显示,第一季度,B站总营收同比增长12%,达56.6亿元人民币,其中广告业务同比增长31%。一季度B站毛利润同比提升45%,毛利率则连续7个季度环比提升至28.3%。减亏方面,公司调整后运营亏损和净亏损分别同比大幅收窄52%和56%,并连续3个季度实现正向经营现金流。0000印度塔塔试图利用微软人工智能合作伙伴关系来提高利润率
站长之家(ChinaZ.com)10月16日消息:塔塔咨询服务有限公司正押注与微软公司的合作伙伴关系,开发基于人工智能的软件服务,以寻求更高的利润率来推动增长。站长网2023-10-16 08:56:390004字节PICO辟谣裁员80% 称系优化组织架构
站长之家(ChinaZ.com)11月9日消息:PICO微博日前辟谣关于“业务关停”、“裁员80%”、“裁员上千人”等不实传闻。PICO称为更专注于硬件和核心技术创新,公司将调整组织架构,相关部门和团队规模将有所缩减。PICO表示,这次调整涉及员工约300余人,占公司总员工的23%。调整后的组织架构将更聚焦硬件研发和核心技术创新。站长网2023-11-09 16:08:470000两张图百万GMV,6800元收徒培训,图文带货是真风口还是割韭菜?
王磊的暴富梦变得更加遥远。在图文带货的风口之下,他报名参与多个直播间的培训课程,结果却是两个月零订单。最后他尝试花钱在平台投放流量,一个月终于卖出20单,按照10%佣金计算,月收入只有200元。0001盘点最值得入手的三款“16 512”的大内存手机,性能高配置强!
如果您喜欢我的文章,欢迎您点击左上角的“关注”后续将第一时间为您带来最新手机资讯!现在随着各种手机软件厂商的不断更新换代,各种各样的手机软件也是变得越来越臃肿。而之前的8128等配置的内存已经明显变得不够用了,那么接下来我就来为大家推荐16512的大内存手机。足够让大家不会为手机存储不够,而陷入烦恼。参考价格:3299(16512)站长网2023-05-23 19:19:180001