提升大语言模型推理速度
开源机器学习库vLLM 提升大语言模型推理速度
要点:1、PagedAttention注意力算法通过采用类似虚拟内存和分页技术,可有效管理LLM推理中的关键值缓存内存。2、vLLM服务系统几乎零浪费关键值缓存内存,内部和请求之间灵活共享缓存,大大提升吞吐量。3、配备PagedAttention的vLLM相比HuggingFaceTransformers提升了24倍吞吐量,无需改变模型架构,重新定义了LLM服务的最佳水准。站长网2023-09-18 11:42:450004Meta 推出 LayerSkip:提升大语言模型推理速度
Meta公司最新发布了LayerSkip,这是一款端到端的解决方案,专门设计用于提升大型语言模型(LLM)的推理速度。这一技术在不同规模的Llama模型上经过了广泛的训练实验,并在多个任务上展现了显著的性能提升。LayerSkip的主要成就包括:CNN/DM文档摘要任务:在这一任务上,LayerSkip将推理速度提升了2.16倍,显著提高了文档处理的效率。站长网2024-04-28 17:54:520001


热点
李彦宏和马化腾,都想通了
2025-02-18 14:54:07新能源汽车开门红:1月销量、渗透率创同期历史新高
2025-02-16 10:48:12马斯克旗下xAI发布Grok3模型 包含mini、Reasoning等版本
2025-02-18 14:10:29春晚才过两周机器人就进化成这了:算法完成升级 能应对任意舞蹈挑战
2025-02-16 10:41:23新势力周销量榜更新:小鹏重回第一、小米排在第三
2025-02-18 14:08:26腾讯回应微信接入DeepSeek:灰度测试 免费使用R1满血模型
2025-02-16 10:38:00接不接DeepSeek?互联网大厂的新天问
2025-02-18 14:03:17百度、OpenAI等大模型免费用 专家:DeepSeek迫使头部玩家打破封闭生态
2025-02-16 10:31:38换个名字获客成本降到不足1美金,“大神”又推火了一个AI App?
2025-02-18 09:52:20Meta 正在大力投资 AI 驱动的类人机器人:希望成为机器人的 Android
2025-02-16 10:22:14
关注
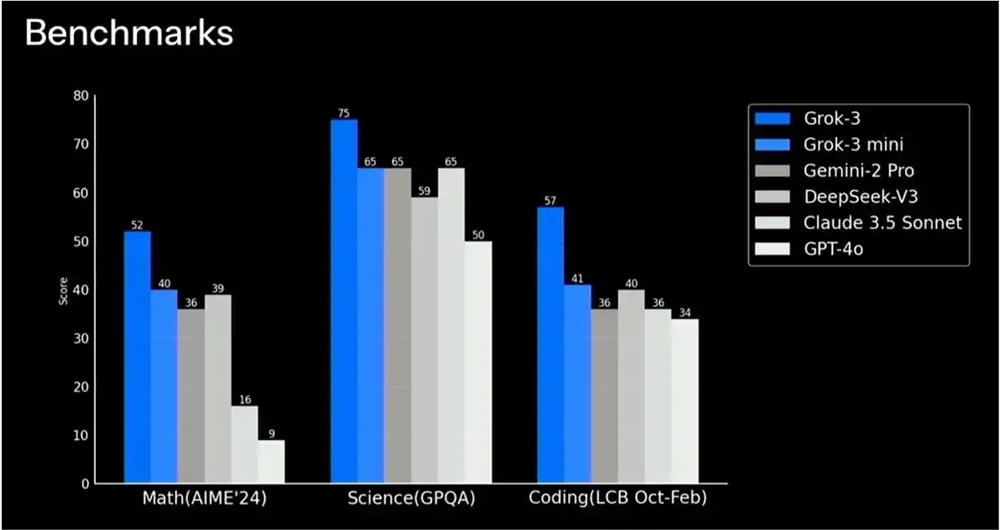
马斯克旗下xAI发布Grok3模型 包含mini、Reasoning等版本
2025-02-18 14:10:29争相拥抱DeepSeek,“学而思们”的野心与忧虑
2025-02-12 18:19:12新势力周销量榜更新:小鹏重回第一、小米排在第三
2025-02-18 14:08:26接入了DeepSeek后的飞书,强大到我有点陌生。
2025-02-12 18:12:58接不接DeepSeek?互联网大厂的新天问
2025-02-18 14:03:17商业导师们全面拥抱DeepSeek
2025-02-12 17:41:51换个名字获客成本降到不足1美金,“大神”又推火了一个AI App?
2025-02-18 09:52:20
千亿美元收购,马斯克是给OpenAI送财还是送灾?
2025-02-12 15:07:25马化腾再次短暂登顶中国富豪榜 腾讯AI、游戏领域表现亮眼
2025-02-18 09:44:50
千万网红鼻祖开播,一小时狂卖5000多单,只赚26元?
2025-02-12 15:05:09