文本直接生成20多种背景音乐,免费版Stable Audio来了!
9月14日,著名开源平台Stability AI在官网发布了,音频生成式AI产品Stable Audio。(免费使用地址:https://www.stableaudio.com/generate)
用户通过文本提示就能直接生成摇滚、爵士、电子、嘻哈、重金属、民谣、流行、朋克、乡村等20多种类型背景音乐。
例如,输入迪斯科、鼓机、合成器、贝司、钢琴、吉他、欢快、115BPM等关键词,就能生成背景音乐。
Disco,DrivingDrumMachine,Synthesizer,Bass,Piano,Guit,AIGC开放社区,47秒
目前,Stable Audio有免费和付费两个版本:免费版,每月可生成20个音乐,最大时长45秒,不能用于商业;付费版,每月11.99美元(约87元),可生成500个音乐,最大时长90秒,可用于商业。
如果你不想付费可以多注册几个账号,可以通过AU(一种音频编辑器)或PR将生成的音乐拼接起来可达到同样效果。
Stable Audio简单介绍
在过去几年,扩散模型在图像、视频、音频等领域获得了飞速发展,可显著提升训练和推理效率。但音频领域的扩散模型存在一个问题,通常会生成固定大小的内容。
例如,音频扩散模型可能在30秒的音频片段上进行训练,并且只能生成30秒的音频片段。为了打破这个技术瓶颈Stable Audio使用了一种更先进的模型。
这是一种基于文本元数据以及音频文件持续时间,和开始时间调整的音频潜在扩散模型,允许对生成音频的内容和长度进行控制。这种额外的时间条件使用户能够生成指定长度的音频。
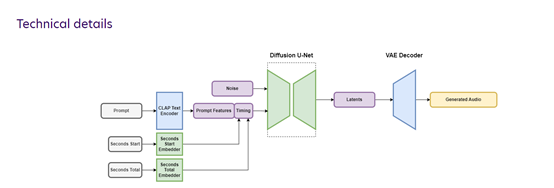
与原始音频相比,使用大幅度下采样的音频潜在表示可以实现更快的推理效率。通过最新稳定音频模型,Stable Audio能在不到一秒的时间内,使用NVIDIA A100GPU渲染出95秒的立体声音频,采样率为44.1kHz。
训练数据方面,Stable Audio使用了一个超过80万个音频文件组成的数据集,包含音乐、音效以及各种乐器。
该数据集总计超过1.95万小时的音频,同时与音乐服务商AudioSparx进行合作,所以,生成的音乐可以用于商业化。
潜在扩散模型
Stable Audio所使用的潜在扩散模型(Latent Diffusion Models)是一种基于扩散的生成模型,主要在预训练的自动编码器的潜在编码空间中使用。这是一种结合了自动编码器和扩散模型的方法。
自动编码器首先被用来学习输入数据(例如图像或音频)的低维潜在表示。这个潜在表示捕捉了输入数据的重要特征,并且可以被用来重构原始数据。
然后,扩散模型在这个潜在空间中进行训练,逐步改变潜在变量,从而生成新的数据。
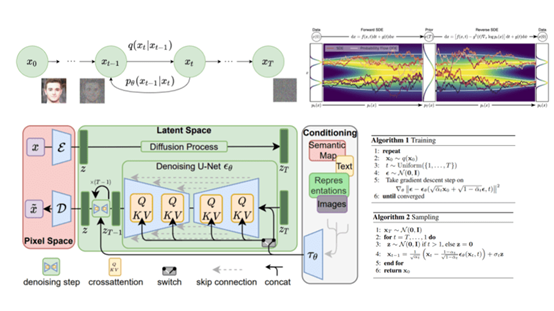
这种方法的主要优点是可以显著提高扩散模型的训练和推理速度。因为扩散过程在一个相对较小的潜在空间中进行,而不是在原始数据空间中进行,因此可以更高效地生成新的数据。
此外,通过在潜在空间中进行操作,这种模型还可以提供对生成数据的更好控制。例如,可以通过操纵潜在变量来改变生成数据的某些特性,或者通过对潜在变量施加约束来引导数据生成过程。
Stable Audio使用和案例展示
「AIGC开放社区」体验了一下免费版Stable Audio,使用方法与ChatGPT差不多直接输入文本提示即可。提示内容包括细节、心态、乐器和节拍四大类。
需要注意的是,如果想生成的音乐更细腻、有律动性和节奏,输入的文本也需要更细化。也就是说,你输入的文本提示越多,那么生成的效果就约好。

Stable Audio使用界面
AI前哨|揭开元宇宙惨死之谜:扎克伯格、AI都是“凶手”!
凤凰网科技讯《AI前哨》北京时间5月9日消息,短短三年时间,元宇宙就从科技界的一个火热概念销声匿迹。外媒发表观点文章称,生成式人工智能(AI)的爆红和扎克伯格不切实际的痴迷扼杀了元宇宙。0000百度文心一言软件著作权获批
中国版权保护中心显示,9月13日,北京百度网讯科技有限公司“文心一言软件”著作权获登记批准,当前版本号为V1.0.0。8月31日,百度「文心一言APP」宣布向全社会全面开放。广大用户可以在应用商店下载“文心一言APP”或登陆“文心一言官网”(https://yiyan.baidu.com)体验。站长网2023-09-18 10:37:310003快手投入了一个600亿的大项目
哪里是电商的最后一片蓝海?无论是国货大佬安踏,还是行业新贵蕉下、追觅,大家都在寻找能带来交易增量的运营阵地。面对即将到来的电商旺季,户外生活方式品牌蕉下成为在快手平台上较早尝到甜头的商家。今年4月,蕉下通过川流计划,实现品牌的曝光环比增长65%,当月GMV增长20%,早布局、提前锁住流量和用户,蕉下成功为即将到来的年中大促蓄水。站长网2023-05-13 09:41:440000AI风投基金OpenAI Startup Fund额外筹集500万美元资金
划重点:⭐️OpenAIStartupFund融资额外5百万美元⭐️资金来自两位投资者,转入特殊目的实体OpenAIStartupFundSPVIII,L.P.⭐️OpenAIStartupFund已向至少16家初创公司投资,包括Harvey、AmbianceHealthcare和人形机器人公司FigureAI。站长网2024-05-14 10:19:550000小米汽车答网友100问:没有Redmi汽车 SU7不会是19.9万
站长之家(ChinaZ.com)1月8日消息:近期,小米汽车针对网友们最关心、最典型的100个问题进行了详细回应。其中涉及到价格、配色、技术细节等多个方面。关于定价问题,小米汽车表示尚未最终确定。雷军在小米汽车技术发布会上提到过价格可能会稍高,但会“贵得有理由”。对于网传的9.9万、14.9万、19.9万等价格,小米汽车予以否认。最终定价将在小米SU7正式发布会上公布。0000









