独家:AI大模型时代或更集中到“强”团队
时间拉回到2015年,梁斌刚刚获得清华大学人工智能博士学位,同年10月八友科技成立,并常年为客户提供国内外数据资料。
2023年上半年,GPT大模型进入公众视线,短短半年时间,国内就已有近百家GPT大模型,“八友”成为绝大多数大模型服务商的首选,据统计,这一数字接近50%。
作为深度参与大模型发展的数据供应商,梁斌的几点洞察尤其值得业界参考,深聊中,他开门见山指出,我们正处在一个“强者恒强的大模型时代”。这句话背后至少点出了三类企业的处境:

图源备注:图片由AI生成,图片授权服务商Midjourney
一是,对于品牌而言,大模型商用的次序依旧是大品牌优先,即便是大模型技术被广泛应用,不成规模的企业依旧是“小脚穿大鞋,跑一步摔一步”。
二是,对于服务商而言,首先拥有大规模的数据样本是一件具备极高时间壁垒的事,其次,拥有数据的平台会想尽办法保护数据,提高数据获取门槛,提高行业难度。因此,后来进入的服务商难度会更大,强者恒强。
三是,对于平台而言,如果是国内互联网平台自相比较,会发现“地主”太多,一个应用出来,就马上能有上亿用户,这是中小平台比不了的。
如果拿国内平台和国外平台比,差距同样也很明显,正如梁斌所言,如果GPT4打10分,国内大模型厂商还在2-3分这个程度,那么2.5分,还是2.8分,其实没差别,要能达到8分甚至9分才有机会。
强者恒强,可能只有一些特别具有垄断性的场景,才能杀出来。
这或许也是品牌、服务商和平台的机会。再小的品牌也能建立起自己的专属粉丝圈;再小的服务商,在垂直行业的深耕依旧具备不可替代的高价值;再小的平台,也能在狭窄赛道中做出本地化的微平台。
虽然,生成式AI可以提供互联网上没有的答案,并通过大规模数据训练得到的“涌现”性知识来回答网友的各种问题。但应用的最后一公里,是否按下确认键依然取决于你自己。
对了,梁斌还将在9月20日参加见实的AIGC主题大会,届时他还将在现场与我们分享更多当前大模型时代下的企业新机会,欢迎大家在文末或者公众号菜单栏报名深度沟通。接下来,让我们回到对话现场,听听梁斌博士在大数据与AI领域的前沿洞察,如下,Enjoy:
01强者恒强在大模型时代会更加严重
见实:你们现在已经是50%国内AI大模型数据的供应商,这个数据的总样本量大约是多少?
梁斌:我们目前列入销售线索的企业大约有106家,数据总量非常巨大,中文压缩数据掌握了大约100TB,海外数据超过1PB,国内数据比较敏感,国外则主要来自Common Crawl、Laion、Quora,Github,Reddit,电子书等平台。
见实:创业之初,你在数据领域看到了怎样的机会?
梁斌:刚开始做八友是在2015年,当时主要是为舆情公司提供数据服务,后来逐渐给需要提供实时数据的电商公司提供数据需求;目前在为大模型客户提供数据服务。
我们一直坚信“数据行业”未来会成为一个独立行业,原因有三:
一是,数据规模越来越大,越来越封闭在App中,采集难度大,容易成为独立的社会分工。
二是,大规模数据储备价值很大,可以做一些非常长远的宏观报告。2015年公司创办前后,当时还没有大模型,只是觉得这是一件可以做10年甚至20年规模的报告,这个储备是很难短期得到的
三是,随着长期的积累,核心竞争力会越来越强,拥有数据的平台会想尽办法保护数据,提高数据的获取门槛,提高行业的难度。
见实:从你的观察来看,目前,行业对AI类企业的认识发生了哪些变化?企业又该如何应对这轮GPT大模型带来的行业冲击?
梁斌:大模型这个卖点之前可能连见到甲方负责人的机会都没有了,现在可以说在2B类生意中具有很强的穿透力,特别是加上耳目一新的演示效果,转化率比以往大大提升。
实际上,AI类企业胜负的关键就在成本竞争。做大模型的团队有很多,成本控制不好就很难长久,控制成本是各家团队的核心竞争力,创新的同时还要结合客户的具体场景,从效率,成本,效果等多方面打动甲方。
在这样快速变化的时代,企业至少要具备三点基础认知:
一是,充分利用现有基础设施,不要重找车轮,模型方面的让专业的人做。
二是,寻找自己行业的特殊数据,最好是非公开数据,通过这些数据建立壁垒。
三是,找到自己行业的应用场景,能接触到这些场景,快速覆盖,也是重要的壁垒。
如果只用一个字来说就是“快”,快是最重要的壁垒,在大厂反应过来之前完成一轮对市场的覆盖。
见实:随着 AI 技术的发展,企业竞争的“胜负手”又会转向哪边?商品、服务还是品牌力?
梁斌:回看创业之处的那三点观察,首先拥有大规模的数据样本是一件具备极高时间壁垒的事,其次,拥有数据的平台会想尽办法保护数据,提高数据获取门槛,提高行业难度。
强者恒强可能在大模型时代会更加严重,中小企业的大模型团队杀出来的可能性还是比较小,中小公司在数据和算力上,人才上都有很大瓶颈,我想可能还是要有一些特别的具有垄断性的场景,才能杀出来。
互联网历史上无数中小公司,有服务,有行业内的品牌,也都倒闭了。互联网行业“地主”太多了,一个应用出来,就马上能有上亿用户,这是普通中小公司比不了的。
02中小企业如何适应强者恒强的时代
见实:你在《走进搜索引擎》这本书中提到,搜索引擎本质是一个由用户定义的信息聚合系统。通过用户输入的查询关键词,搜索引擎推测用户的查询意图,然后快速地返回相关的查询结果,供用户选择。
生成式AI的出现,其实是帮用户省去了大量搜索整理信息的时间,它的出现是否会重新定义“主动搜索”这件事?如果让你重新定义搜索,你会如何描述?这么描述的底层逻辑是?
梁斌:搜索引擎核心的价值有两个,一是通过网页质量评估方法去掉低质量网页;二是通过相关性方法提高了相关性(相对于查询词的相关性)。这些共同节约了用户找到答案的时间。
然而搜索引擎毕竟不是神,它也只能给出一个排序,用户还是需要自己在排序的结果页中寻找答案,选择答案的时间没有省去。
生成式AI直接给出最佳结果,风险很大,因为只有一次机会,但是用户体验极佳,而且更难得的是,生成式AI可以提供互联网上没有的答案,通过大规模数据训练得到的“涌现”性知识来回答网友的各种问题。
我们的开发工程师研究安卓的源码,有一段看不懂,大模型却可以来解释,这个在网上任何地方都搜索不到答案的。而且大模型解答数学题的能力也很强,一个题目变一种说法,互联网上就找不到了,而大模型依然可以正确回答。
见实:Open AI创始人也曾提到过数据规模并不是越多越好,你们有对数据的临界点做过划分吗?哪些情况下会遇到数据规模触顶?
梁斌:目前基本上我们知道的情况模型参数大概分10B(billion),100B这个参数量级,前者解决一些文史哲数据,或者解决一些理工类数据解决复杂问题。
参数的提升意味着数据需要跟着提升,否则就容易过度拟合,对训练数据的解释能力提高,但是泛化能力,理解非训练数据的能力就降低了。因此,从人力发展,算力提升的趋势看,肯定是越多越好。
但是多也会带来问题,数据质量要跟着提高,否则数据多反而会影响训练效果,低层次的数据反复训练,也达不到高水平智能。
临界点划分目前我知道没有统一标准,目前1TB token都是小模型,玩具型的,随着社会发展需要,10TB甚至100TB token都不算大。
见实:你认为品牌需要发展到多大体量,或者需要多大的数据样本才能支撑起一套大模型的运转?
梁斌:不同行业数字化水平不同,比如机械行业,基本上数据都在书籍,论文,课本上。
如果是一个消费者品牌,其可以拿到的数据,也就是知乎,小红书,一些评价型数据,基本品牌在销售过程中一些售后服务对话数据,也是非常小的。
所以,狭窄行业的专业知识是非常少的。如果从百度知道,知乎上搜索这个品牌词,看看有多少相关的提问就会知道,其实,很多小行业可能短时间还用不上大模型。
见实:怎么看待微信私域CRM中的用户数据?好友或者群聊天记录是否会是品牌主要的数据源。如果对话内容会成为主要数据源,那你觉得需要多大量级才能实现对话场景中的自动化?
梁斌:目前我知道的对话数据大多涉及个人隐私,处理起来也极其困难,直接用作训练风险极高,特别是2C场景不太敢用对话数据。我目前了解的可以买到的对话数据大概是这么几类。
一是,医疗类多轮对话数据;二是,社交网络(比如微博)的多轮评论改造成的对话数据;三是,影视作品中的对白。
这些对话数据还是太少,目前看还没法满足各种垂类行业的需求。
见实:瑞幸咖啡、汉堡王等企业本质上是一家技术公司,也是数据驱动型公司,这是否也意味着他们这样体量的消费品品牌会是接下来AI大模型应用落地的排头兵?毕竟这类行业的用户交互频次与增长速度是最快的。
梁斌:到目前为止还没有一个消费品品牌有独立技术团队在做大模型,也没有向我们购买数据的品牌企业。
瑞幸、汉堡王这样的企业,主要解决的还是用户增长问题,智能客服和自动化文案宣传部分的应用需求可能会多些。
有用到大模型的场景,独立组建团队来做是不太可能的,但他们可能是在同赛道企业中最先拿到结果的。
见实:中小企业能做些什么呢?哪些不可逆的错误动作需要中小企业特别注意的?
梁斌:中小企业积累数据风险很高,特别是积累用户个人数据可能风险更大,万一传播开来会比较麻烦,最安全的方法就是不要积累用户个人数据。这个可能是数据积累过程中遇到的最大风险。
03百模大战:国内AI大模型的演变与发展
见实:国内AI大模型的演变过程是怎样的?可以被分为几类?
梁斌:目前,国内AI大模型发展速度飞快,但起步有点晚,仍还在追赶阶段。每家大模型团队向前迭代都有不同的思路,总体上受限于数据和算力等资源。
不缺算力的团队,在持续扩大数据规模;缺算力的团队,则在不断优化现有数据质量。总体来看,国内做AI大模型的企业可分为三类:
第一类做底座开源的2B类大模型,如,智谱AI,零一万物这种。
第二类是做垂类大模型的企业,主要在底座大模型上用特殊数据做continue training的,比如,左手医生等等。
第三类做2C类型的大模型服务,代码闭源。如,百度文心一言,阿里通义千问、讯飞星火大模型等等。
其中,底座大模型的发展还在爬坡,垂类大模型和2C 类型的大模型团队都已经开始赚钱了。当然,做垂类大模型的也有可能2C,不过现在看来可能性比较小,盈利模式基本跑不通。垂类解决行业问题,B端用户付费是比较正常的。
见实:你们会被归为哪一类?是否已经实现盈利?这类商业模式目前还有多大的进入机会?未来是否有引入资本的计划?
梁斌:我们不做大模型,我们只是给大模型提供数据服务,已经盈利了。做大模型的企业目前基本都在投入期,传统的技术型公司,有应用场景的业务型公司,还有各行各业的龙头企业都在进入这个领域,服务的客户千奇百怪。
见实:在大数据服务中你们的核心价值是什么,这些价值是如何帮助企业实现更好的业务成果的?
梁斌:我们的服务核心理念和“赌场理念”相似,不怕客户(员工)占便宜,就怕客户(员工)不来。只要客户愿意让我们服务,就是巨大的机会。
整个交付过程一般会被分成三部分:
首先是交付阶段,先做事,先服务,满意后再付费;其次是遇到问题了,积极赔偿;最后是客户随时需要,我们的工程师随时服务,我们会给工程师高昂加班费,以确保服务的连续性。
见实:之前有提到过数据市场的三个发展阶段,能否详细阐述这些阶段,以及在你看来,企业在每个阶段的机遇和挑战是什么?
梁斌:我认为数据发展的阶段,也是人类知识数字化的阶段。在有计算机,互联网以前,人类知识通过书本传承。在计算机出现,特别是互联网出现以后,数据开始向互联网转移。大概可分为三个阶段:
传统互联网时代,数据都在网页上,只要是社交需求,部分功能需求。
移动互联网时代,数据既在网页上,也在app上,社交需求降低,功能需求提升,大量的数据围绕这实现具体功能,购物,外卖,叫车,订票等等。
人工智能时代(大模型时代),人类知识有计划的数字化,大量纸质书被电子化,政府公开大量数据,数据越来越成为人类共有的资产参与对人类的服务中去。
现阶段来说,企业都有面向大模型的需求,一方面是卖点,另一方面是切实创造价值,快速用现有基础设施和行业需求进行整合,快速实现行业服务水平的升级。
比如有团队做了网店的24小时多语言客服,可以和全球的客商在任何时间用任何语言进行导购服务,去掉了时差,去掉了语言障碍。
见实:还有哪些应用案例?以及你们的通用做法是怎样的?
梁斌:以我们目前服务的金融和汽车行业客户为例,通常有三种落地方式:
一是,通过生成式模型替代部分甚至全部人类工作(这类工作往往是低阶工作),金融行业比如做一些基础数据准备,简报,传统的需要人力的部分,可以通过大模型来解决。新能源汽车行业车载交互系统,客户需求的研究等等都可以由大模型来参与。包括很多游戏行业通过大模型创造图片,减少了游戏原画师的需求。一些客服需求很重的企业,通过大模型降低人工客服的需求,等等。
二是,通过大模型来辅助人类工作(这类工作往往是高阶工作),比如现在大模型帮助高中生解题,帮助大学生写论文,帮助工程师写代码,帮助律师分析案情,帮助医生进行诊断等等,这类往往可能是实现盈利模式的重点,也是目前大模型发展方向的重点。
三是,通过大模型来指导人类工作,因为大模型可以把大量交叉学科的语料一起训练,容易产生更加高阶的智慧,从而能够指导高科技研究,高精尖装备的研发等等,目前国外大模型在向这个方向努力,国内大模型还暂时没到这个阶段。
见实:一路观察下来,科技互联网大厂、投融资机构和学术研究机构都在做什么?
梁斌:都在齐头并进吧,行业的交流氛围还是比较开放的。
理论研究方面国内科学家已经取得了很好的成果,比如清华大学的朱军老师提出的快速高效训练方法等;互联网大厂团队则在疯狂迭代推进,基本三个月一个小版本,半年一个大版本;投融资机构稍微有些安静,因为种种原因实际上并没有及时跟进,至少国内还并没有看到特别大的投融资事件发生。
见实:那未来大数据与人工智能发展趋势,你是如何预测的?接下来互联网大厂的“百模大战”中你更看好哪一家?
梁斌:从业务视角去看,第一波买我们数据的是互联网公司;第二波会是非互联网的上市公司;第三波是想也没想到的各行各业的2B类公司。
这个影响速度是非常快的,大部分企业决策人都已经在深度思考大模型和自己业务的结合了。
目前国内确实正在经历着一场“百模大战”,很难定输赢。
从整个大的行业来看,国内大模型团队做的产品我感觉和GPT4都有较大差距,如果GPT4打10分,其他还在2-3分这个程度,那么2.5分,还是2.8分,其实没差别,要能达到8分甚至9分才有机会,目前国内的大模型还要继续努力才行。
当然,我们作为数据提供方也要继续努力,缩小差距。
网信办加大“自媒体”MCN机构管理力度
中央网信办秘书局近日发布了《关于加强“自媒体”管理的通知》,该通知提出,为了加强对“自媒体”所属MCN机构的管理,网站平台应加强MCN机构管理制度的建立,并统一对MCN机构及其签约账号进行管理。此外,要求在“自媒体”账号主页上显著展示该账号所属MCN机构的名称。对于那些利用签约账号联动炒作、多次违规行为的MCN机构,网站平台应采取相应的处置措施,如暂停营利权限、限制提供服务以及清退等。站长网2023-07-10 16:49:240001马斯克:SpaceX和星链都没用AI AI在这些方面表现糟糕
在洛杉矶近日举行的米尔肯研究所全球会议上,美国知名企业家埃隆·马斯克再次就人工智能(AI)的议题发表了自己的看法。马斯克明确表示,他的太空探索技术公司(SpaceX)在运营中“基本不使用人工智能”。站长网2024-05-08 19:52:020000折射OpenAI新一年技术路线图,透视Sam Altman的12个愿望清单
当地时间12月24日,SamAltman在X平台上罕见地发起了一个「许愿池」,「希望OpenAI在2024年构建/修复什么?」,这条推文迅速吸引AI领域众多大佬和网友的参与。两个小时后,SamAltman挑选了12个期望值最高的愿望清单,并誓言「我们将尽我们所能去提供(以及许多其他我们感到兴奋但此处未提及的内容)」——从这里可以折射出OpenAI2024年的路线图。0000亚运会“前夜”,B站、京东等大厂押注“电竞”生意经
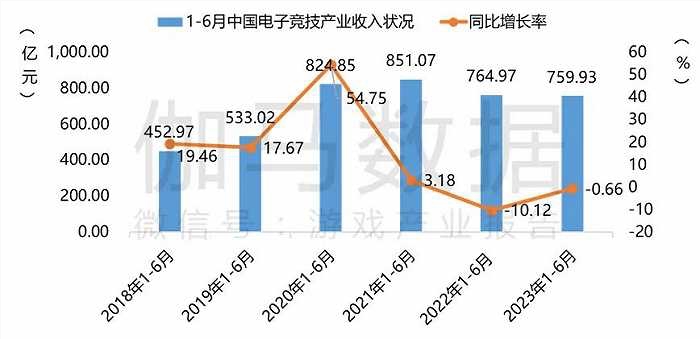
亚运会开幕前一个月,电竞赛道已经风起云涌。8月8日,2023英雄联盟全球总决赛LPL赛区资格赛结束,JDG、BLG、LNG和WBG四支战队将作为LPL一至四号种子,代表中国参加英雄联盟全球总决赛。同日,有媒体报道称,作为过去三年S赛事独家版权方的B站,正式拿下今年英雄联盟S13全球总决赛的转播权。站长网2023-08-10 14:04:550000REDMI:Turbo 4的6550mAh电池理论寿命4.4年 实际远超
快科技1月8日消息,REDMITurbo4已经上市,目前销量和口碑都不错,尤其是能效和续航方面表现强劲。该机首发搭载了6550mAh最大容量小米金沙江电池,可以实现超过4年的寿命。REDMI官方在问答中表示,手机电池随循环次数增加,寿命下降是必然,保持满血”(100%)状态是不实际、也是不可能的。业界一般以80%可用电量作为手机电池的临界点,低于80%则需要更换。0000