开源大模型训练框架Megatron-LLaMA来了 32卡训练可加速176%
要点:
淘天集团联合爱橙科技正式对外开源大模型训练框架Megatron-LLaMA,以提高大语言模型训练性能,降低训练成本。
测试显示,相比HuggingFace代码,Megatron-LLaMA在32卡训练上获得176%的加速;在大规模训练上表现出几乎线性的扩展性。
Megatron-LLaMA已在GitHub开源,将持续关注社区发展,与开发者共同推进自适应配置、更多模型支持等方向。
9月12日,淘天集团联合爱橙科技正式对外开源大模型训练框架Megatron-LLaMA,以让技术开发者们更方便地提升大语言模型训练性能,降低训练成本。
据悉,Megatron-LLaMA是一个基于Megatron-LM的分布式深度学习训练框架,专门用于大规模语言模型LLaMA的训练。LLaMA已经成为开源社区中最杰出的大规模语言模型之一,它集成了BPE词元化、预规范化、旋转嵌入、SwiGLU激活函数、RMSNorm和非绑定嵌入等多项优化技术,在客观和主观评价中都展现出卓越的结果。
项目地址:https://github.com/alibaba/Megatron-LLaMA
LLaMA开发了7B、13B、30B和65B/70B多个模型规模的版本。在开源社区中,也出现了许多基于LLaMA的成功变体,无论是通过连续训练/监督微调还是从零开始训练,都进一步证明了LLaMA在长上下文理解、长上下文生成、代码编写、数学问题求解、工具使用等任务上的卓越能力。
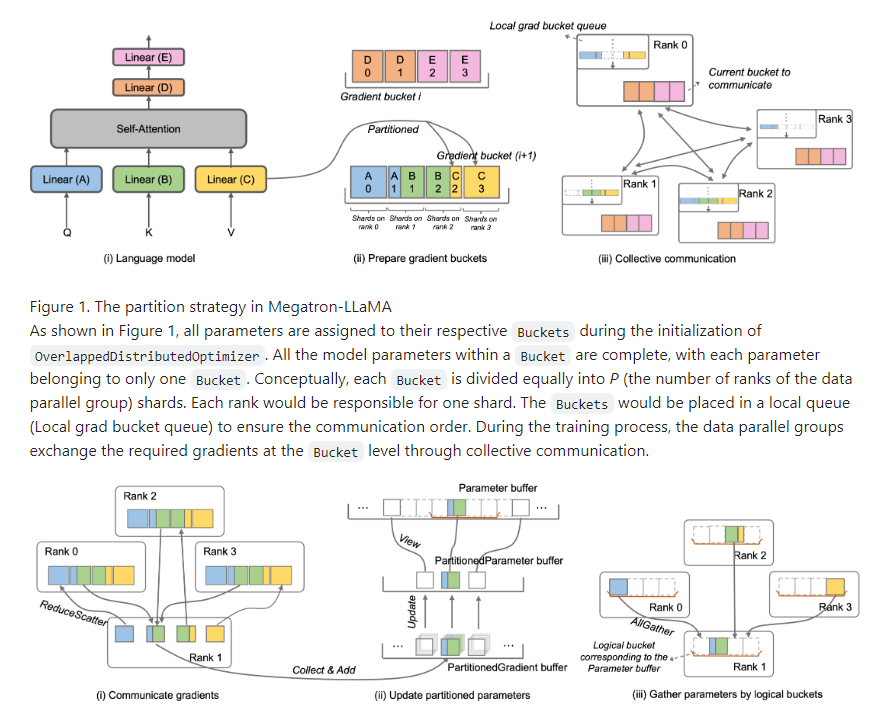
然而,由于大规模语言模型的训练或微调都需要强大的计算资源,开发者自己尝试在LLaMA上实现新的设计往往非常昂贵。Megatron-LM是一个集成了张量并行、流水线并行和序列并行的分布式训练解决方案,可以在训练具有数百亿参数的模型时充分利用硬件资源,使资源利用率远高于基于Huggingface和DeepSpeed实现的公开版LLaMA。但是,原生的Megatron-LM在极大规模下会遭受分布式优化器的通信瓶颈。
测试显示,相比HuggingFace直接获得的代码,Megatron-LLaMA在32卡训练上获得176%的加速效果。在大规模训练上,Megatron-LLaMA相对原生Megatron-LM有几乎线性的扩展性,且对网络稳定性表现出高容忍度。
Megatron-LLaMA改进了DistributedOptimizer的梯度聚合机制,实现梯度通信与计算的并行,从而优化了反向传播流程。
当前Megatron-LLaMA已在GitHub上开源,淘天集团和爱橙科技将共同维护,并积极关注社区发展,与开发者们在自适应配置选择、模型支持等方面进行合作,以推动Megatron和LLaMA生态建设。
Megatron-LLaMA的主要特点如下:
在Megatron-LM中实现了标准的LLaMA,可以按需配置其中的优化技术。未来还将支持Alibi和FlashAttention2等特性。
通过实现高度重叠的通信和计算,提升了通信计算并行性,与DeepSpeed ZeRO Stage2类似,大大减少了GPU内存占用,提高了吞吐量。
提供了分布式检查点保存/恢复等实用工具,加速了训练过程,支持与HDFS等分布式文件系统集成;支持与HuggingFace transformers库的tokenizer集成,方便下游任务迁移。
Megatron-LLaMA使LLaMA模型的大规模训练变得快速、经济高效且具备可扩展性。它降低了训练大模型的门槛,是开源社区一个重要的贡献。
淘天AI打算让吴泳铭等多久?
“大家都在说我们‘含AI量’下降,我觉得比例是上升的,从淘天消耗的服务器显卡规模就能看得出来。”面对外界对淘天AI电商进展温吞的评价,阿里巴巴集团副总裁、淘天用户平台事业部总裁、阿里妈妈负责人吴嘉在双11前曾进行了一番回应。针对吴嘉提到的显卡规模问题,据一位知情人士透露,今年以来,淘天正在完成供应商替换,引入平头哥与A卡,以实现国产替代。0000微软、亚马逊等公司正在制定 AI 辅助招聘政策
站长之家(ChinaZ.com)10月12日消息:虽然进一步在招聘实践中引入AI可能解决一些问题,但专家表示,不应期望技术能够完全改变公司招聘新员工的方式。站长网2023-10-12 10:02:020000腾讯高管:竞技对战类游戏是基本盘 不能被二次元等所动摇
快科技1月30日消息,在腾讯的公司年会上,腾讯COO、IEG(互动娱乐事业群)总裁任宇昕称,竞技对战类游戏是我们的基本盘,不能被当下热门的MMO、二次元所动摇。任宇昕表示,关于IEG能不能打”的问题,外部有文章提到IEG收入下降或者上升,大家不要太多在意外部的信息,还是要从内部看。站长网2024-01-30 10:39:510000免费写真 人人都能用!腾讯元宝AI跨年美照上线:大片一键生成
快科技12月30日消息,明天就是跨年夜了,如果你拍摄技术堪忧,跨年大片可以交给腾讯混元AI了,直接一键生成绝美大片。腾讯元宝AI美照”功能已经上线了跨年专区,可以免费制作预制写真,通过各种模版来生成自己的跨年大片。整体来说流程还是非常简单的,整体逻辑有些类似去年爆火的妙鸭相机”,通过AI来美化修图。站长网2024-12-30 21:15:000000李国庆淘宝直播卖酒,一场卖了1个亿
李国庆重回淘宝直播间“士别三日,当刮目相看。”这句话如今正契合了当当网创始人李国庆的现状。李国庆三年后再回淘宝,际遇已大不相同。11月3日晚上6点半,李国庆开启了淘宝直播首秀。开播时间比计划的整整提早了1个小时,仅一小时销售额就突破3000万元。最终整场直播销售额突破1亿元。站长网2023-11-07 11:54:280000