基于Llama 2的日语LLM发布,参数量达70亿、可与GPT3.5匹敌
文章概要:
1. ELYZA发布了基于Meta的Llama2的日语LLM「ELYZA-japanese-Llama-2-7b」,参数数量达到70亿,性能媲美GPT3.5。
2. 该模型经过追加事前学习和独特的事后学习,性能在5级手动评估中获得最高分,尽管还未达到封闭型LLM的水平,但已经与GPT3.5相匹敌。
3. ELYZA成功地将英语等其他语言的LLM能力引入日本语,并通过减少日本语学习量来改进Meta的Llama2基础上的模型。
最近,日本的人工智能初创公司ELYZA宣布发布了一款基于Meta的「Llama2」的日本语言模型(LLM),该模型被命名为「ELYZA-japanese-Llama-2-7b」,拥有70亿参数。此举使得该模型能够与开放AI领域的巨头GPT3.5相媲美。
为了达到这一性能水平,ELYZA采用了多重学习策略。首先,他们进行了日本语的追加事前学习,然后进行了独特的事后学习。此外,通过增加日本语词汇表,他们实现了模型的高速化,进一步提高了性能。这一系列措施使得「ELYZA-japanese-Llama-2-7b」成为一个强大的日本语言模型。
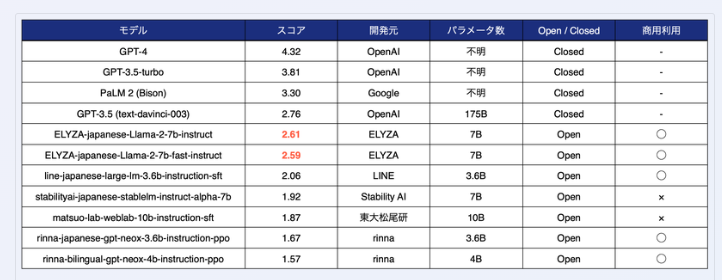
性能方面,ELYZA使用了「ELYZA Tasks100」数据集,进行了5级手动评估。评测时,三人进行盲测,隐藏型号名称、打乱顺序,通过得分平均来计算分数。
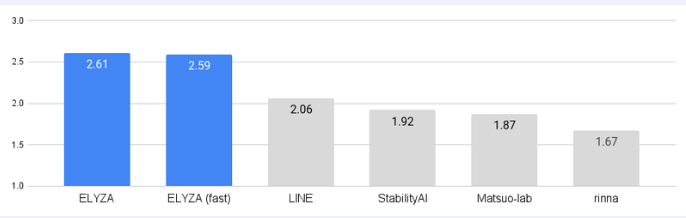
结果显示,「ELYZA-japanese-Llama-2-7b-instruct」在与其他已公开的日本语模型进行比较时,获得了最高分。虽然它还没有达到闭源LLM的水平,但已经能够与GPT3.5相匹敌。
值得注意的是,ELYZA在模型的开发中采用了一种聪明的方法,将其他语言的LLM能力引入到了日语中,从而减少了日语学习的难度和成本。这一策略为模型的性能提升做出了重要贡献。
ELYZA的「ELYZA-japanese-Llama-2-7b」模型标志着日本语LLM领域的一项重要突破。虽然目前在参数数量上仍不及一些国际级模型,但这一进展为日本语自然语言处理和生成领域带来了更多可能性,未来可望进一步提高日本语LLM的性能。
真我12 Pro系列官宣:本月在美国拉斯维加斯发布
站长之家(ChinaZ.com)1月9日消息:realme徐起宣布,真我12Pro系列将于本月在美国拉斯维加斯正式亮相。这一消息引起了广泛关注,因为真我12Pro系列被视为realme的一款旗舰级新品。0000全球最赚钱黑人社交App,背后的故事
我们在两个月前发布的《18亿潜在用户的“小众”交友App,到底有多赚》一文中讨论了穆斯林群体的交友偏好和社交现状,引起了不少读者对“垂直群体社交所蕴含的机会”的思考。黑人社交,MatchGroup绝对把控、女性更加艰难因此我们打算继续这个小众系列,而今天探讨的则是黑人群体的Dating偏好。先来说我们得出的几个关键结论:站长网2024-02-22 09:17:130000微软 Bing Chat 正式支持谷歌桌面版浏览器 Google Chrome
微软正式为GoogleChrome添加了对BingAI的支持。据悉,BingAI在六个月前发布时仅限于Microsoft的Edge浏览器,但现在已经扩展到了GoogleChrome。尽管目前仅支持这两个浏览器,但这对于BingAI来说仍然是一个重要的扩展。站长网2023-08-29 12:12:010002研究:ChatGPT或币医生更好的遵循抑郁症治疗指南
划重点:1.AIChatGPT被认为可能比医生更好地遵循抑郁症的治疗标准,而且没有性别或社会阶层偏见。2.研究发表在英国医学杂志旗下的开放获取期刊《FamilyMedicineandCommunityHealth》上。3.ChatGPT与1,249名法国初级医生进行了比较,结果显示其在遵循抑郁症治疗指南方面表现出更高的准确性。站长网2023-10-18 11:43:050000特斯拉公布全新车型预告图,基于全新平台打造,成本将大幅降低?
5月17日,在2023年特斯拉股东大会上,马斯克不仅对未来产业实施了规划,还透露出了更多新型车辆的更多信息,据悉目前正在着力研发两款最新车型,并将对其进程进行了大力推进,还表示这两款车型在性能和工艺方面将超过以往车型,量产后可实现年产超过500万辆的成绩。站长网2023-05-24 12:49:040000