北邮、南洋理工推沙雕视频数据集FunQA 用算法学习喜剧
要点:
1.FunQA是一个包含4365个反直觉视频和312万个文本问答的新数据集。
2.FunQA包含3个子集:幽默视频HumorQA、创意视频CreativeQA和魔术视频MagicQA。
3.FunQA设计了时间戳定位、详细描述、反直觉推理等任务,对模型的理解力提出深入挑战。
来自北京邮电大学、新加坡南洋理工大学及艾伦人工智能研究所的学者们提出了FunQA,一个全新的高质量视频问答数据集,用于测试和提高AI模型对反直觉视频内容的理解能力。
论文地址:https://arxiv.org/abs/2306.14899
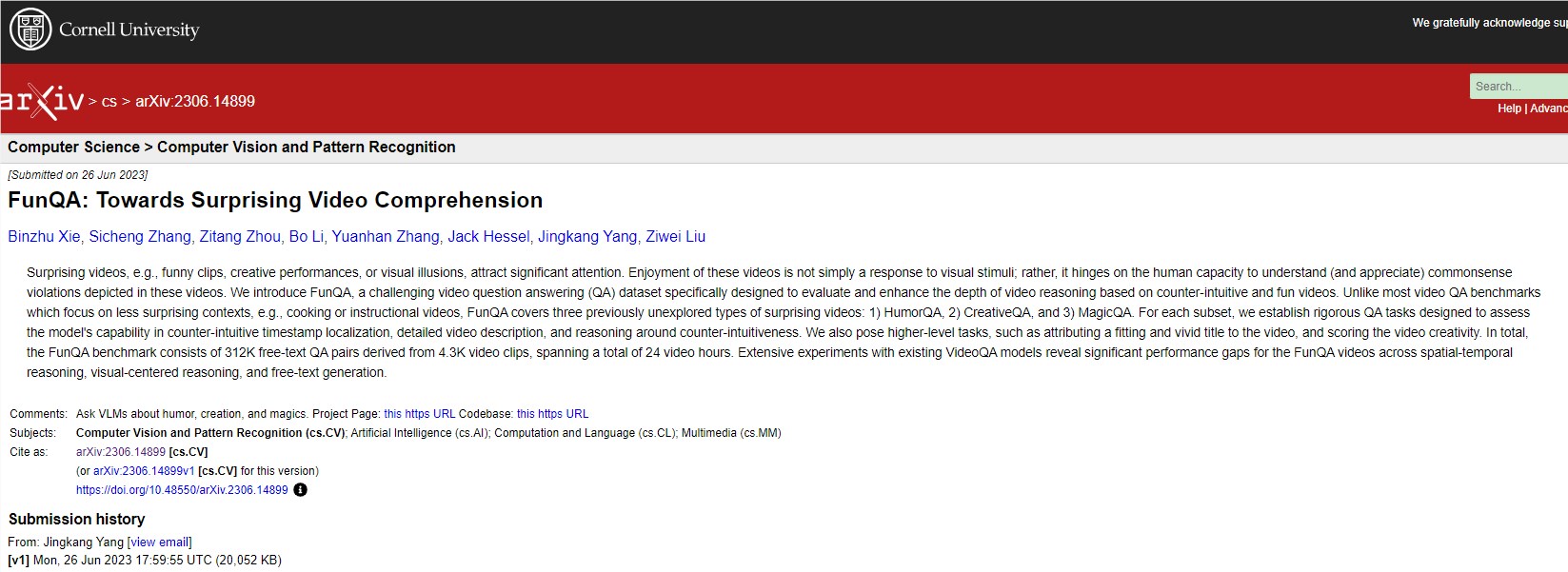
FunQA包含总时长近24小时、来自3种反直觉艺术类型的4365个短视频,以及312万条人工注释的视频问答对。它由3个子集组成:幽默视频集HumorQA、创意视频集CreativeQA和魔术视频集MagicQA。这些具有反直觉特点的视频可以对模型的理解力产生深入的挑战。
项目地址:https://funqa-benchmark.github.io/
与现有视频QA数据集相比,FunQA有以下特点:
1. 专注反直觉领域,测试模型对非常规事件的理解力。
2. annotation丰富,每个问答平均34词,远超其他数据集。
3. 创新探索幽默感理解,需要模型学习幽默原理。
4. 强调深度时空推理,如通过常识判断幽默反差。
5. 设计了时间戳定位、详细描述、反直觉推理等任务考察模型的视觉编码、语义表达和逻辑推理能力。
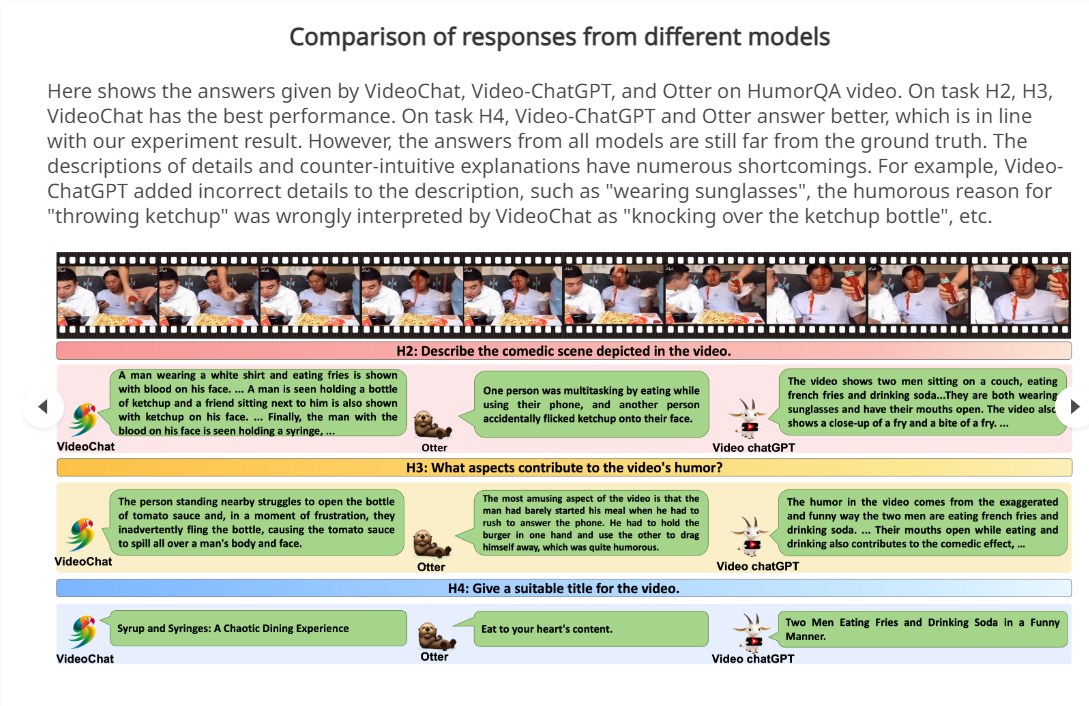
FunQA的具体组成如下:
1. HumorQA:来自脱口秀和模仿秀的1335个幽默视频。
2. CreativeQA:来自创意短视频平台的1465个反常识创意视频。
3. MagicQA:来自网络平台的1565个难以理解的魔术视频。
针对每个子集,FunQA设计了3个核心任务:
1. 反直觉时间戳定位:找到视频中关键反直觉事件的时间点。
2. 详细视频描述:用语句描述视频内容。
3. 反直觉推理:解释视频中反直觉的原因。
此外还有视频标题生成等扩展任务。
在多个模型上进行测试表明,当前模型在FunQA任务上的表现普遍不佳,关键原因包括:
1. 难以准确理解长视频内容和上下文信息。
2. 缺乏推理“常识”,无法理解违反直觉的内容。
3. 不同类型视频的理解能力差异很大。
4. 评估指标不足,难以测量深度理解。
研究者因此提出,后续工作可以从提升模型大小、改进数据质量、优化训练策略等方面入手,以提高模型在FunQA任务上的表现。总体而言,FunQA提供了一个全新且富有挑战的视频理解基准,可以推动计算机视觉研究的发展。
小米汽车域名xiaomiev.com已启用
今年8月,小米汽车科技有限公司成功登记备案了xiaomiev.com这个网站域名。目前,该域名已经正式启用。小米汽车科技有限公司是在2021年11月成立的,法定代表人为雷军,注册资本为10亿人民币。该公司的经营范围广泛,包括技术开发、新能源车整车制造、汽车整车及零部件的技术研发、道路机动车辆生产等。小米科技有限责任公司全资持股小米汽车科技有限公司。站长网2023-12-01 15:36:540000导演消失了!Midjourney+妙鸭相机+Gen2新玩法:10块钱创造马斯克宇宙,一键图生视频
【新智元导读】Gen-2又双叒更新了。这次,不用一句话,只要一张图,秒生大片。与Midjourney、妙鸭相机联动后,效果简直炸裂。生成式AI的大爆发,带来了无限可能。近来,在国内,秒鸭相机火遍全网,服务器几度被挤爆,堪比羊了个羊。只需上传一张照片,分分钟得到一套AI写真,让许多人惊呼海马体们要失业了。站长网2023-07-24 15:03:260000AI实时绘图工具ImgPilot 一键将草图转为艺术作品
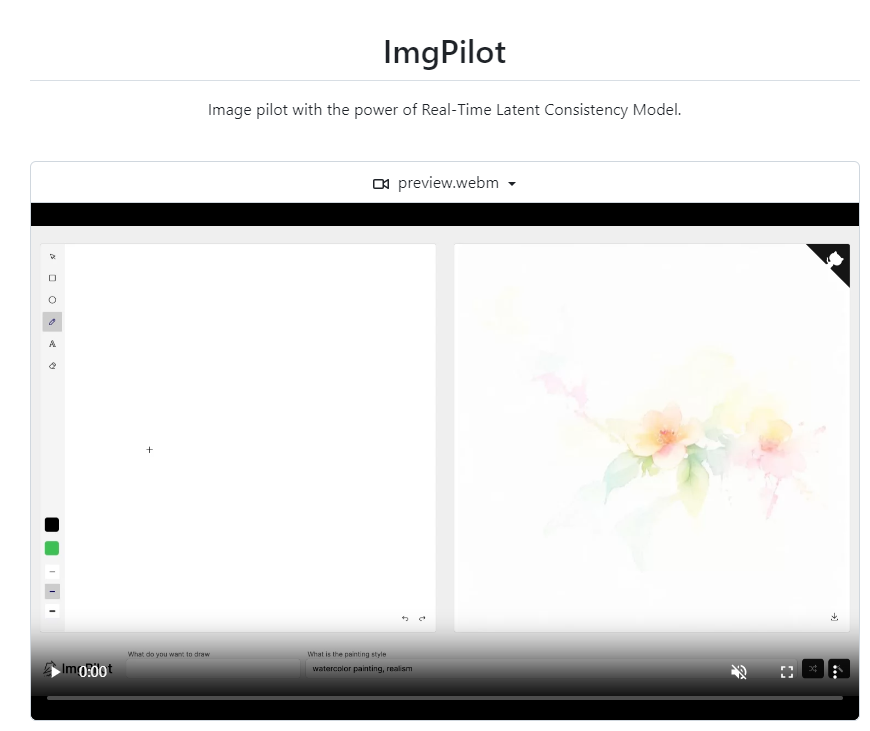
ImgPilot是一款利用实时潜在一致性模型的力量将草图转换成惊人的艺术作品的工具。这个项目包括完整的前端和后端代码,支持本地和云端部署。它完全基于开源,可以自由地用于商业目的。这个项目的核心目标是利用AI技术,特别是实时潜在一致性模型,为用户提供一个强大的工具,将简单的草图转化为令人惊叹的艺术作品。项目地址:https://github.com/leptonai/imgpilot站长网2024-03-11 09:50:100003阿里推开源版“妙鸭”FaceChain 1张图片百种定制
FaceChain-FACT是阿里推出的一项人工智能生成个性化肖像的技术,通过DeformableNeuralRadianceFields技术从普通视频中创造自由视点的肖像。使用FaceChainAI照片生成模型,不需要提供多张照片训练LoRA(妙鸭相机的原理),仅需一张用户照片即可生成高度定制的肖像,支持百余种定制模版,生成速度更是快过商业应用100倍,达到秒级。站长网2024-01-10 10:53:280005蚂蚁集团发布DevOps领域大模型评测基准DevOps-Eval
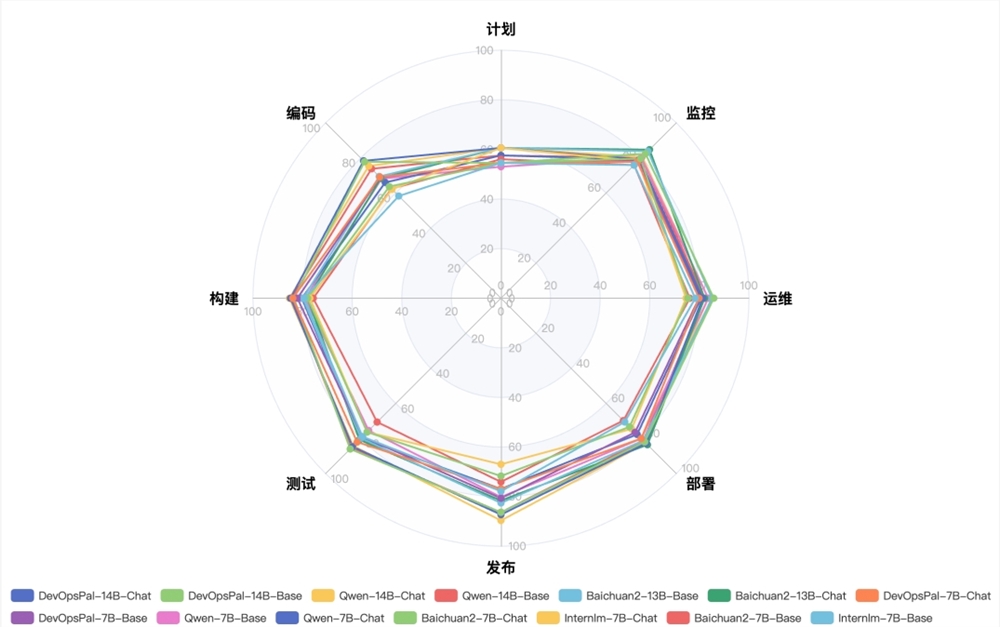
蚂蚁集团联合北京大学发布了面向DevOps领域的大语言模型评测基准——DevOps-Eval。该评测基准包含了计划、编码、构建、测试、发布、部署、运维和监控等8个类别的选择题,共计4850道题目。此外,还针对AIOps任务做了细分,并添加了日志解析、时序异常检测、时序分类和根因分析等任务。站长网2023-11-02 15:31:590000