1800亿参数,支持中文,3.5万亿训练数据!开源类ChatGPT模型
阿联酋阿布扎比技术创新研究所(Technology Innovation Institute,简称TII)在官网发布了,目前性能最强的开源大语言模型之一Falcon180B。
TII表示,Falcon180B拥有1800亿参数,使用4096个GPU在3.5万亿token 数据集上进行训练,这也是目前开源模型里规模最大的预训练数据集之一。Falcon180B有基础和聊天两个模型,允许商业化。
Falcon180B在多个权威测试平台中,在推理、编程、知识测试等方面,超过了Meta最新发布的 Llama270B 和 OpenAI 的 GPT-3.5,可媲美谷歌的PaLM2-Large仅次于GPT-4。
基础开源地址:https://huggingface.co/tiiuae/falcon-180B
聊天开源地址:https://huggingface.co/tiiuae/falcon-180B-chat
在线测试地址:https://huggingface.co/spaces/tiiuae/falcon-180b-demo
今年5月,「AIGC开放社区」曾介绍过TII发布的一款类ChatGPT开源大语言模型Falcon-40B。
该产品刚推出便成为Huggingface的开源大语言模型排行第一名,击败了LLaMa65b、GPT4-X-Alpasta-30b、LLaMa30b等众多著名开源项目成为一匹黑马。
Falcon180B便是在Falcon-40B基础之上研发而成,并将模型参数扩大了4.5倍,训练集从1万亿提升至3.5万亿token,并在算法、推理、硬件部署方面进行了大幅度优化。
其中,最大的亮点就是Falcon180B- chat版本支持中文,并进行了数据微调。
Falcon180B简单介绍
预训练方面,Falcon180通过使用 Amazon SageMaker 在多达4096个GPU上同时对3.5万亿个token数据集进行训练,总共花费了约7,000,000个小时。
TII表示,Falcon180B的规模是Llama2的2.5倍,而训练所需的算力资源是Llama2的4倍。
Falcon180B的训练数据集主要来自RefinedWeb的网络数据(大约占85%)。还在对话、技术论文和一小部分代码 (约占3%) 等,经过整理的混合数据的基础上进行了训练。
Falcon180B-chat模型在聊天和指令数据集上进行了微调,并混合了多个大规模对话数据集,使其能够更好地理解用户的文本提示意图,生成丝滑、流畅、拟人化的各种文本内容。
Falcon180B性能评测
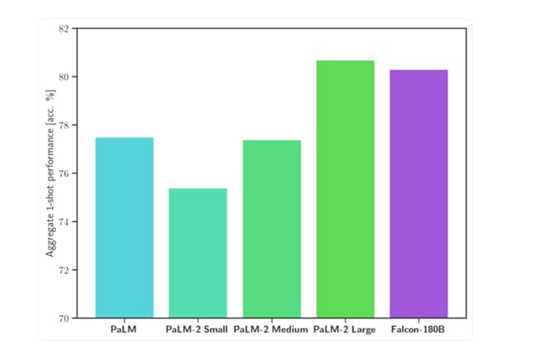
Falcon180B在MMLU上的测试结果,优于Llama270B 和 OpenAI 的 GPT-3.5;在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC等测试中,可媲美谷歌的PaLM2-Large。
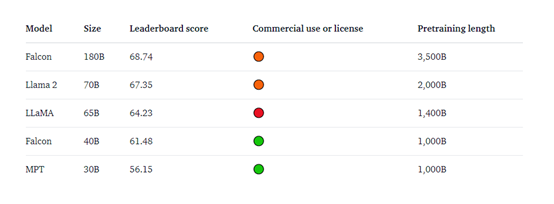
目前,Falcon180B在Hugging Face排行榜上得分为68.74,是得分最高的公开发布的预训练大语言模型,超越了Meta的 LLaMA2、LLaMA等。
Falcon180B- chat使用体验
「AIGC开放社区」通过在线demo体验了一下Falcon180B- chat,使用方法和ChatGPT一样,中文生成的内容基本达到了GPT-3.5的效果,支持单话题,多轮深度询问。
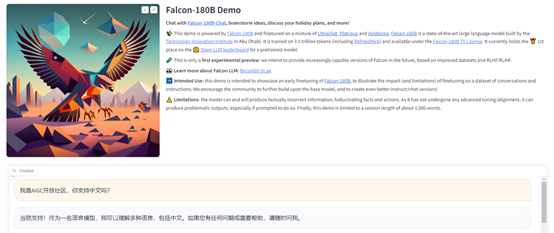
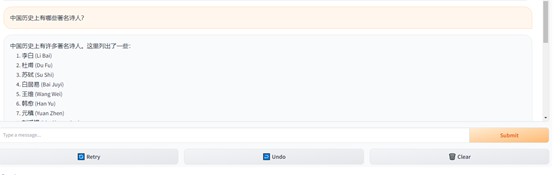
例如,询问,中国历史上有哪些著名诗人?Falcon180B- chat可以按照罗列的方式,列出最知名的诗人。
让其详细介绍一下李白。

再介绍一下李白对现代人的影响。Falcon180B- chat的整体回复内容非常丝滑、流畅。

关于TII
TII 成立于2020年,是阿布扎比高等教育和科技部 (ADEK) 旗下的研究机构。TII 的目标是推动科学研究、开发前沿技术并将其商业化,以促进阿布扎比和阿联酋的经济发展。
目前,TII拥有来自74个国家的800多名研究专家,发表了700多篇论文和25多项专利,是世界领先的科学研究机构之一。
古生物学家发现4.5亿年前海洋中的凶猛“捕手”,长这样→
远古发现丨4.5亿年前,这种远古“萌物”竟是海洋中的凶猛“捕手”记者从中国科学院南京地质古生物研究所获悉,该所研究人员与英国古生物学者合作,在我国浙江省安吉县发现一种约4.5亿年前的远古节肢动物——安吉古鲎。安吉古鲎长着圆滚滚的脑袋,外形非常可爱。不过,它其实是当时海洋中的一种凶猛肉食动物,堪称远古海洋中的“萌系霸主”。安吉古鲎复原图(中科院南京地质古生物研究所杨定华绘)站长网2023-05-23 19:43:300000瑞幸咖啡门店数量已超过星巴克三成,成为国内门店最多的咖啡连锁品牌
根据瑞幸咖啡Q1财报,门店数量已达9351家,超过星巴克中国的6200家,并开始拓展国际市场。这意味着,瑞幸咖啡的门店数量已经超过了星巴克三成,成为全国门店数量最多的咖啡连锁品牌。在营收方面,瑞幸咖啡营收达6.4亿美元,与星巴克中国的差距进一步缩小。然而,瑞幸也面临着新的竞争挑战,曾经的核心人物陆正耀陆正耀创立的库迪咖啡正在与其展开关于价格、店面和营收的竞争。站长网2023-05-08 11:23:330000微软财报显示必应 AI 聊天已超过 10 亿次会话 人工智能服务增长强劲
在微软的第四季度财报电话会议中,公司报告了强劲的收入增长,截至2023年6月30日的季度,收入增长了8%,达到562亿美元,较上一财年同期增长。运营利润增长18%,达到243亿美元,净收入增长20%,达到201亿美元。站长网2023-07-26 11:41:250000eBay 推出 AI 辅助背景工具,增强产品图片
划重点:-eBay推出新的AI背景增强工具,允许卖家用AI生成的背景替换图片背景-该工具已在美国、英国和德国的iOS用户中推出,将逐渐在未来几个月内向Android用户推出-这一举措使得卖家无需专业设备或技能即可拍摄出专业外观的高质量照片站长网2024-06-06 20:46:070000半年花2万,年轻人“集卡”上头
背后公司暴赚,年入40亿。一代人有一代人的精神食粮。很多80后、90后小时候以收集水浒人物卡为乐,不少00后、10后是奥特曼卡片的狂热爱好者。近年来,谷子经济火爆,卡牌企业开发各种IP,借势又火了一波。如小马宝莉等IP,从小学生席卷到了成年群体。0000