MVDream:轻松实现从文本到3D渲染图像
文章概要:
1. MVDream可以仅从文本描述生成高质量3D图像,实现从文本到3D渲染。
2. 通过使用多视角图像训练,MVDream可以生成连贯一致的3D内容,避免了常见的“两面人”等问题。
3. MVDream的图像分辨率目前较低,仅256x256,需要使用更大模型来提升质量和泛化能力。
近日,字节跳动研究人员推出了名为MVDream的新技术,它可以仅通过文本描述生成高质量的3D图像。这种从文本到图像的生成技术,被称为“文本到3D”技术,是当前计算机视觉领域的热门研究方向。

MVDream的创新之处在于,它可以生成连贯一致的3D图像,而不是仅仅是从不同角度拼凑的2D图像。
这主要得益于MVDream使用的训练方式。具体来说,MVDream不仅使用了常见的文本-图像训练对,还使用了包含同一3D对象的多视角图像进行训练。例如,它会使用一只狗的多视角图像来训练模型,让模型学会从文本描述中生成该狗的3D形状,而不是仅生成狗的单视角图片。
在测试中,MVDream生成的3D图像质量显著优于其他类似技术,基本上避免了“两面人”问题(一个对象具有不协调的多面)以及内容漂移问题(内容随视角改变)等常见问题。这为未来从文本生成连贯、逼真的3D内容打下了坚实的基础。

然而,MVDream目前的图像分辨率仍较低,只有256x256像素。此外,其泛化能力有限,主要依赖特定数据集的训练。
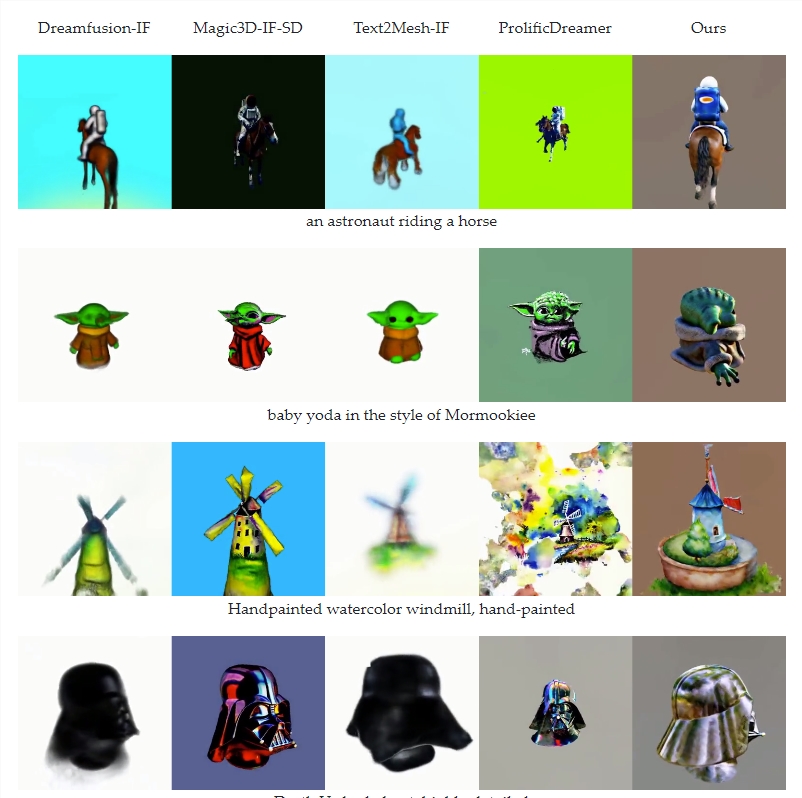
不同模型的对比
不过,字节跳动预计,未来可以通过使用 SDXL 等更大的扩散模型来减少或解决这两个问题。然而,为了显着提高3D 渲染的质量和风格,该团队表示可能需要使用新数据集进行广泛的培训。
MVDream模型的核心特色功能如下:
- 利用预训练的图像扩散模型进行多视图生成,实现2D扩散的泛化性和3D数据的一致性。
- 通过分数蒸馏采样作为3D生成的多视图先验,极大提高了现有2D方法的稳定性。
- ,通过解决3D一致性问题提升下游任务的性能。
- 可以进行个性化的多视图生成,使用少量数据进行精调。
- 生成的多视图图像在不同视角具有几何一致性。
- 可以根据文本提示语生成对象和场景的多视图图像。
总结而言,该模型的创新点在于融合了2D图像生成与3D数据一致性,通过多视图先验指导3D生成,既保留了2D生成的泛化性又提升了3D任务的性能。
项目网址:https://mv-dream.github.io/
直接抄Character.AI作业?Meta发布虚拟聊天机器人 Gen AI Personas
Meta计划推出名为「GenAIPersonas」的AI聊天机器人服务,旨在挽回社交媒体平台的用户流失问题。这款AI聊天机器人将具备个人助理功能,不同性格的聊天机器人选择以及帮助用户更好表达自己的能力。站长网2023-09-25 14:52:520000教授用ChatGPT写推荐信,帮助学生获得剑桥大学奖学金
ChatGPT生成能力有多强?最近,一名加拿大的大学教授通过使用ChatGPT写推荐信,帮助学生获得剑桥大学奖学金。大多数大学的推荐信都是公式化的,没有个性。而加拿大维多利亚大学教授MattHuculak先是使用ChatGPT写了一封“优秀”的推荐信,并将其作为模板,写了一封“反公式化”、并且十分真诚的推荐信。站长网2023-04-25 10:01:0800021场直播卖货320万,中小企业应该这么做
│前言│最近小红书直播出现了各种风格“脱口秀”“英语直播”“小说剧场”“闲聊”的风格,给人感觉就是很松弛,直播间互动效果不要太好,甚至连转化也还不错。说到直播,大家脑海中可能会联想“321上链接”,但其实,现在的直播风格与一年前大不相同,往常我们看直播都是硬推产品,很生硬,我一般看到这种都直接划走,除非看到我比较感兴趣的品,或者是直播间很有趣。站长网2024-10-18 23:56:360000“顶流”完颜慧德靠造梗获粉百万,流量新势力是如何诞生的?
近期,年轻人话题里津津乐道的都是上海万圣节,一个西方的节日却处处透露着本土文化的趣味,有人说这是一场cosplay的狂欢,但更多的人认为,这是一场玩梗的盛宴,甚至有人把此次万圣节,称之为“万梗节”。从唐僧、安陵容、向太、吴京到乙方、鲁迅的“不干了”、李佳琦的“哪里贵了”……互联网上的热梗,都从线上来到了线下,梗,似乎在成为一种新的语言,也在成为新的流量势力。站长网2023-11-07 15:57:080000支付宝推出“12.12支付宝生活节” 准备派发12亿红包
近日,支付宝推出12.12生活节促销活动,从12月1日起至12月12日,在支付宝平台线上线下实现“消费省钱”。用户可通过扫描商家“赚钱红包”二维码领取现金红包,还可在支付宝App上领取更多购物和生活福利。0000