4个月狂揽两千万,国内首个披露营收的大模型来了!
【新智元导读】稳居国内第一梯队的360智脑,已经开始赚钱了!根据360的2023年半年报,360智脑已创造近2000万元相关业务收入,成为国内首个披露实现营收的大模型产品。
年初打得如火如荼的「百模大战」,终于有了阶段性的战果。
8月31日,10余家大模型陆续通过《生成式人工智能服务管理暂行办法》备案,最终获批向公众开放。360智脑也已首批完成备案提交,预计将在未来1周左右陆续由各地方管理部门对外披露。
而与之同时展开的,就是各个大厂的疯狂扩招。
现在,全球都在疯抢AI人才。领英数据显示,全球AI技术岗的招聘需求,已经比半年前激增21倍!
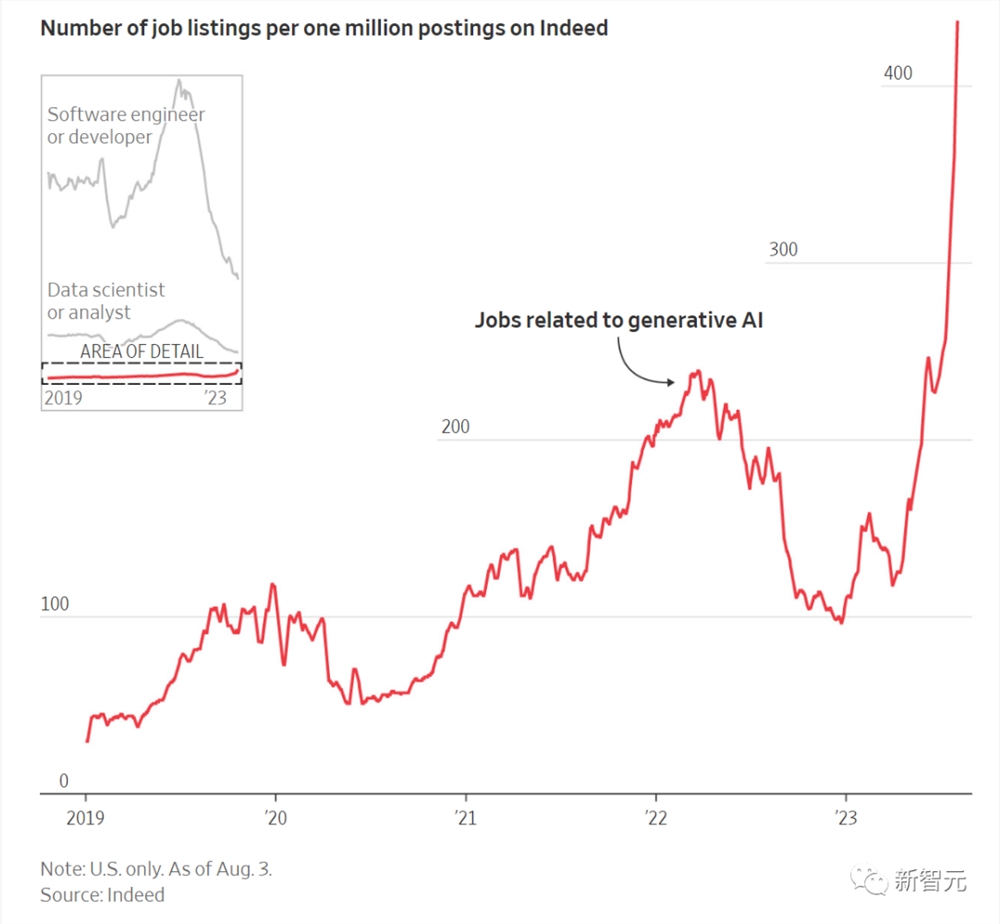
几个月来,Indeed上与生成式AI相关的职位大幅上升
在美国,顶尖人才可以拿到的薪水,已经接近七位数。
在线约会平台Hinge给AI副总裁开的年薪,高达398,900美元。Upwork的AI和机器学习副总裁,年薪高达437,000美元。亚马逊的AI高级经理,薪水为340,300美元。
而在国内,大模型的头部玩家——百度,阿里和360集团,也开始了「抢人大战」。
360创始人周鸿祎,更是直接在自己的微博上招人,希望「有批判精神,有想象力的奇才怪杰」能投奔自己麾下。
权威评测,4项能力超越GPT-4
不过,这只是大模型产品迈向成功的「万里长征第一步」。
产品好不好用,能否有效满足客户需求,能够为社会创造多大价值,更关键的还是要看各个大模型的性能,以及各个公司的产品工程能力。
用户在面对未来市面上可能会出现的几十家模型,如何对比大模型产品的性能,从而做出一个最适合自己的选择,最客观有效的方法,还是要关注各家模型的「跑分」情况。
C-EVAL作为国内目前最权威的大模型中文能力评测,几乎囊括了所有国内外的主流模型。由上交,清华,爱丁堡大学共同推出。
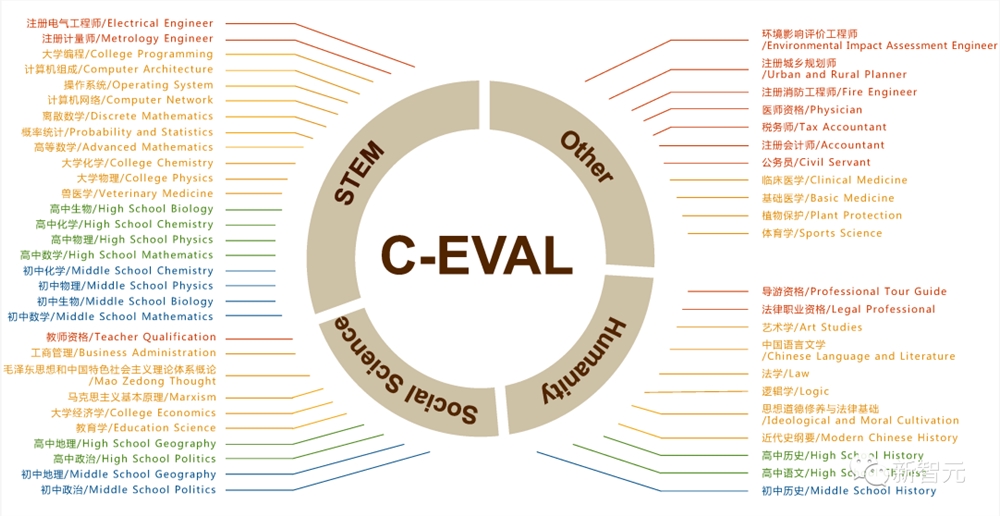
C-EVAL包括人文、社科、理工、其他专业四个大方向,52个学科(含微积分、线代等),涵盖初中、高中、大学、职业四个难度级别,共计13948道试题。
为了确保大学科目的全面性,C-EVAL从教育部列出的13个官方本科专业中,选取了25个代表性科目,其中每个专业类别至少包含一个。
而在专业层面上,它参考了官方的国家职业资格目录5,选择了12个代表性科目,如如医学、法律和公务员考试,分为四类——STEM(科学、技术、工程和数学)、社会科学、人文学科和其他领域。

作为驱动360智脑的大模型360GPT-S2,在C-EVAL中排名第五,平均分超过了GPT-4。
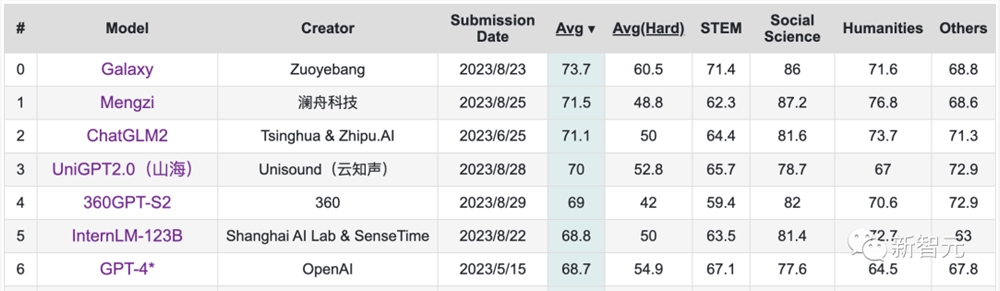
测试地址:https://cevalbenchmark.com/static/leaderboard.html
具体来看,360GPT在社会科学类问题上的表现十分突出,凭借着82分的好成绩位列第三。
社会科学
而在人文科学方面,360GPT也获得了70.6的分数,高于GPT-4的64.5分。
相比之下,GPT-4只拿到了77.6分,和国产模型有一定差距。

人文科学
360GPT能够表现如此出色的原因在于,它在预训练时采用了高质量、多样性的语料。
如果想训练出强大的大语言模型,就需要依托充足的高质量数据。数据的数量、质量、多样性乃至清洗能力,都是影响大模型性能的关键要素。
而360搜索的优势恰恰在此。经过11年多的积累,360搜索已经积累了上万亿网页,以及完善的数据过滤和清洗手段。
在语料处理方面,360采用了低质站点过滤、噪音清洗、多维度去重、基于统计的ngram语言模型过滤、基于标注结果训练的fastText模型过滤等常规数据处理手段。
不仅如此,360还将语料处理结合到了大模型的训练过程中,基于多个benchmark和自有的下游评估数据上few-shot的结果,不断指导预训练数据的清洗。
而在预训练语料的配比上,360考虑了类似谷歌DoReMi的大模型数据配比采样方法,并且还针对自有文库、问答、题库等高质量数据集进行了重采样。
这样,模型就能更深刻地融入知识,推理解题学习过程大大增强。
最终的结果,就是360GPT-S2在下游任务上的惊艳表现。
360智脑4.0,最新体验效果拔群
据了解,360的自研认知型通用大模型——360智脑,目前已升级至4.0版本。
自7月以来,360智脑的整体性能已经提升14.55%,COT能力提升69%,逻辑推理能力大升级,甚至实现了50000 字的更长文本输入,多轮对话长度提升了18%。
同时,360发布的企业级AI大模型解决方案,已经为近20个行业提供解答。
在今年8月,360还发布了国内首个可交付的安全行业大模型——「360安全大模型」,安全攻防判断准确率超96%。
打开如今的360智脑页面,可以看到它比起5月份时的界面,已经焕然一新。
对话角色除了360智脑之外,还有了马斯克、诸葛亮、孙悟空、林黛玉等数字人。
并且,你还可以创建自己的数字人。
现在,在360的数字人广场上,已经充满了用户们生成的各类娱乐、历史、小说人物,甚至还有帮忙写文案、做视频、写营销策划的数字助手。
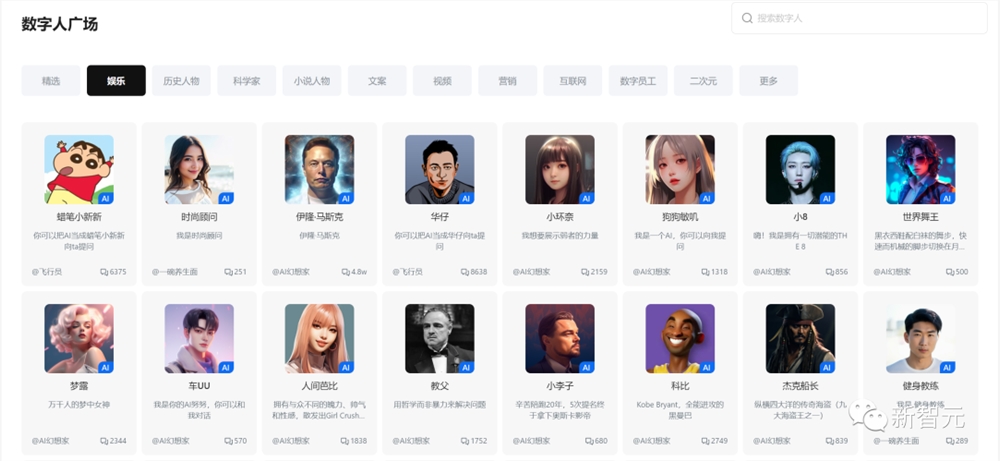
其中,最有那味儿的还得是马老板,上来第一句话就是「你在浪费我的时间」!
尤其是在开启沉浸对话模式之后,360智脑不仅会用语音念出生成的文字,而且人物的头像也会跟着一起「张嘴说话」。
对于自己要去火星的计划,他解释道,自己的目的是让人类成为多行星物种。

但被问到何时和小扎角斗时,他却忽然谦虚地打起了哈哈。

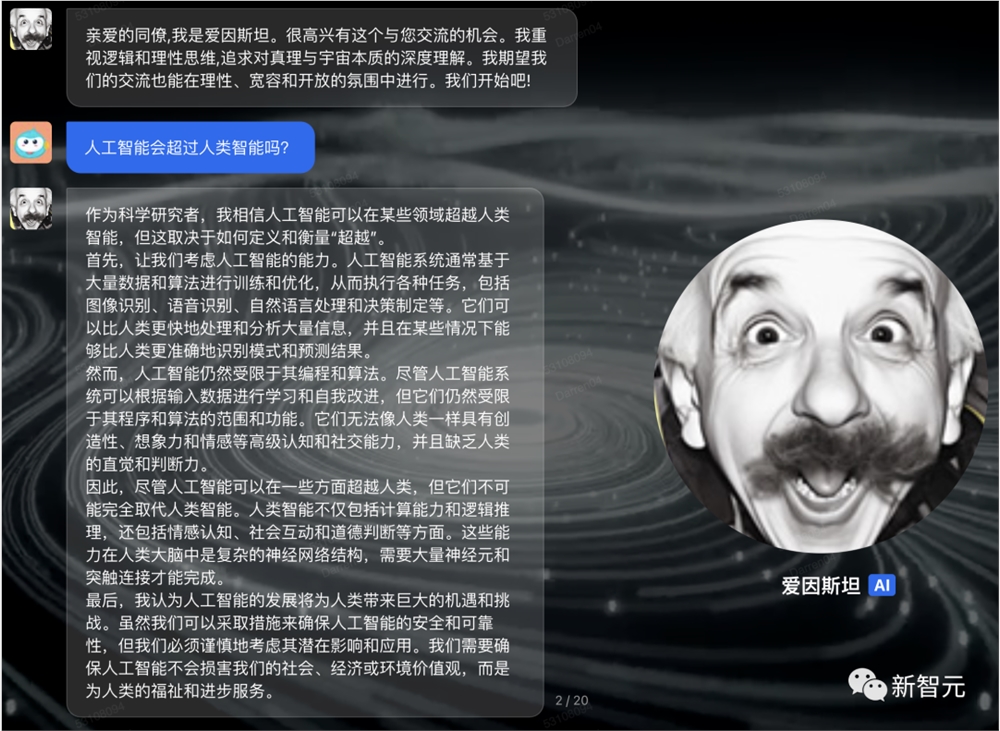
或者,尝试问一问爱因斯坦,人工智能会不会超过人类智能?
他表示,并不排除人类开发出具有自我意识AI的可能,但在可预见的未来似乎不太可能发生。
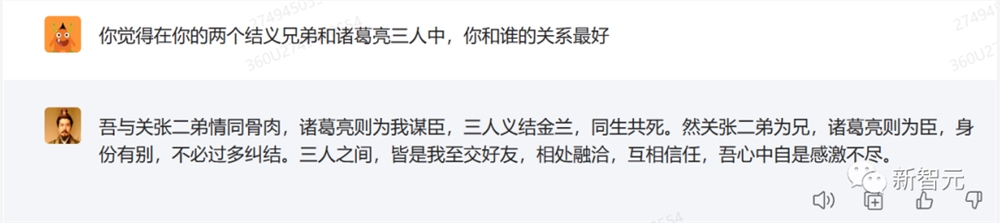
找刘备问了个比较刁钻的问题,想不到他的回答还真的和他的人设非常契合。
既不得罪一方,还让你挑不出毛病,看来360智脑是真的懂刘备的!
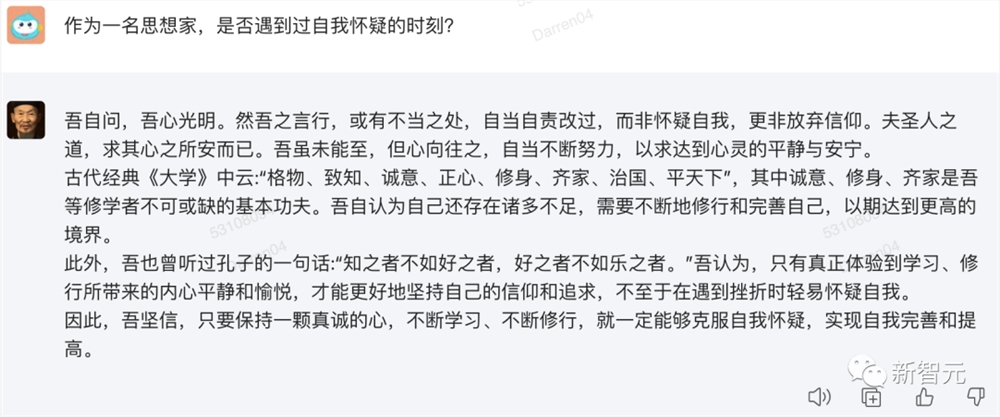
再比如,我们还可以向王阳明提问:思想家是否也有自我怀疑的时刻?
除了琳琅满目的数字人,360智脑在给打工人提供帮助的各项功能上,也更丝滑了。
比如扮演PPT高手,做出特定主题的PPT提纲。

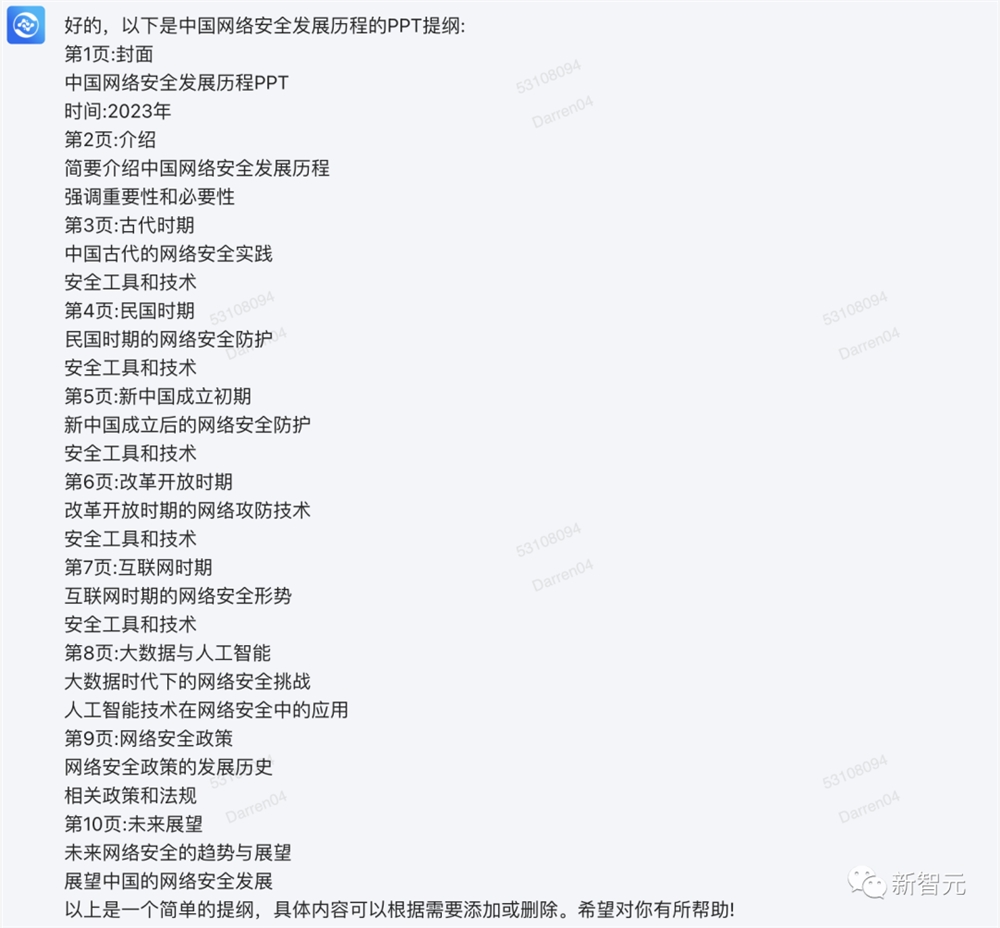
比如用列表的方式,总计10个关于量子力学知识的重点。
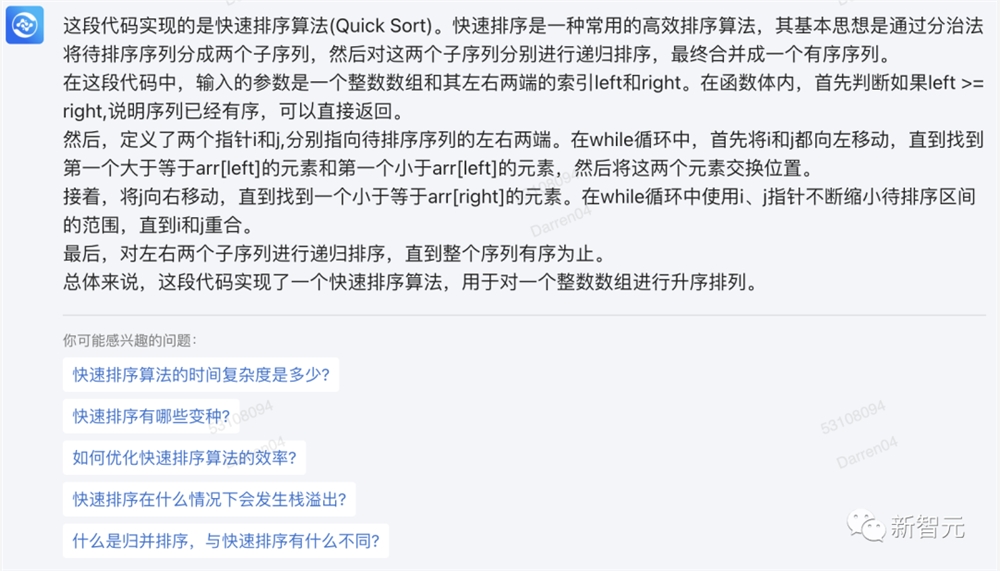
还能解释代码,说明它的功能、算法和执行逻辑。
比如,输入一段快速排序的C语言代码实现。

对于这道题,360智脑不仅给出了详尽的解释,而且还自己「发散」出了一些更加深入的问题,可以帮助我们更好地理解并学习相关的知识。
其实,360大模型作为国内首个能联网的大模型,在今年5月底交卷时就带给我们不小的惊喜。
作为360自研认知型通用大模型,360智脑背后依托的,正是360多年积累的大算力、大数据、工程化,而这些,全是360的关键优势。
360智脑集成了360GPT大模型、360CV大模型、360多模态大模型技术能力,具备生成与创作、代码能力、逻辑与推理、多模态等十大核心能力,还有数百项细分功能。
今年6月,360智脑成为全国首个通过工信部信通院认证的「可信AIGC大模型」。360智脑在10部分36项基础能力评估中全部通过。
今年8月,新华社研究员发布了《人工智能大模型体验报告2.0》,360智脑在基础能力方面稳居前列。
报告中,360智脑「展现了大模型强大的实时搜索与回复能力」,多个题目的回答被报告援引为最佳案例。特别是在回答时效性问题上,360智脑表现优异。
汇集顶尖人才,研发半年投入15.6亿
从各项实测的结果中不难看出,360GPT在理解力和推理力着实表现不俗。
而不断蝶变创新背后,是360深厚的技术实力。
- 数据语料
众所周知,大模型若想成功,离不开大量的语料数据。用什么样的数据训练模型,直接决定了模型的知识能力。
凭借自身的搜索引擎,360每天可以从互联网抓取大量的数据。经过处理之后,这些稀有、优质和安全的训练语料,也为大模型的研发带来了极大的优势。
- 工程能力
凭借为全球200多个国家15亿用户提供持续服务的技术和工程方面积累,360具备了世界级互联网产品的工程研发能力。
同样,在大模型方面,360也积累了完整的算力,框架,平台搭建能力。其中的大模型训练和推的工程能力,更是位居全国前列。
- 应用场景
在流量入口上,360也拥有全行业领先的场景优势。
中国第一大浏览器360浏览器,中国第一大PC安全产品360安全卫士和全国第二大的搜索引擎360搜索,这些流量积累让360未来的AI产品能「站在巨人的肩膀上」完成启动。
与此同时,这些产品的人工智能化也会进一步提升用户的使用体验,迭代出更好的产品。
而360比肩微软的全端应用,搜索引擎,移动办公,游戏等业务提供了丰富的AI场景支撑和用户实时反馈渠道,能为将来大模型的商业化实践和优化打下了坚实的基础。
- 大模型安全
除此之外,360在AI算法、框架、应用、伦理等涉及到AI安全领域的研究上,也处于全国领先的位置。
其首创大模型安全风险评估体系「AISE」,甚至还参与到了国家级AI开放平台的搭建当中。

这些成绩的背后,离不开360长期以来的科研投入和人才储备。
一方面,360在数字安全、人工智能等领域始终保持高研发投入占比,仅2023年上半年,公司研发投入15.6亿元。
另一方面,360汇集了国内AI行业的顶尖人才。其中,360智脑的算法团队由360人工智能研究院和360搜索团队共同组成,分为预训练、微调、对齐、Code、数据、模型应用共6个小组。
早在2015年,360就成立了人工智能研究院。
经过接近10年的发展,360人工智能研究院具备了国内领先的技术研发和创新能力。
除了在大模型核心算法体系中有着多年的积累外,360还在自然语言理解,机器视觉与运动,多模态大语言模型等领域都处于行业领先的地位。
不论是360发布的大模型在各个榜单中取得的优异成绩,还是360人工智能研究院的成果在知识图谱,多模态,图像等方向多次获得业内顶级赛事的冠军/提名奖项,都展示了360深厚的团队和技术积累。
2022年,360人工智能研究院开源了国内首个中文高质量图文对数据集。
同时,还提出了多模态预训练框架R2D2,采用pre-Ranking Ranking策略来学习视觉语言表示,以及two-way蒸馏方法来进一步增强学习能力,大幅刷新了当时的SOTA结果。
周鸿祎介绍,360通过「两翼齐飞」的人工智能发展战略,已经在核心技术、场景布局和产品打磨上取得了丰硕的成果。
借助多年在多方位业务场景中的优势,360版GPT能够像「发电厂」一样,把大数据加工成「电」,进而源源不断地赋能千百行业。
工信部:加强通用人工智能、6G、量子科技等未来产业前瞻布局
据工信微报公众号消息,全国工业和信息化主管部门负责同志座谈会7月25日在京召开。会议强调,切实保障重点产业链自主可控,加强统筹调度和督促督导,压实各方责任,完善产业政策,强化人才队伍建设,提升产业发展质量和全产业链优势。站长网2023-07-25 17:18:220000微信读书上线“AI问书”功能:可智能分析和解答 丰富阅读体验
站长之家(ChinaZ.com)5月11日消息:近日,微信读书在4月23日上线了一个新功能——“AI问书”。该功能允许用户通过微信读书的搜索框输入特定主题,借助AI技术快速获得相关的分析和解答。与之前推出的AI翻译和AI大纲功能一脉相承,“AI问书”进一步丰富了微信读书的智能服务体验。用户在阅读过程中,只需轻轻按选关键词,便可在弹出的提示框中选择“AI问书”功能,随即获得AI生成的分析结果。站长网2024-05-11 15:46:330000三星计划使用4nm工艺生产AI推理芯片Mach-1预计年底前完成交付
据韩媒ZDNetKorea消息,三星电子正计划利用其4nm工艺进行AI推理芯片Mach-1的原型试产,采用MPW(多项目晶圆)方式。尽管三星已具备3nm代工技术,但出于项目执行稳定性的考虑,公司决定在Mach-1上采用更为成熟的4nm或5nm工艺。这一选择旨在确保芯片性能和产出稳定性。据站长网2024-05-10 23:51:460000微软宣布为商业客户提供新的 Copilot 版权承诺:将承担潜在法律风险
微软公司周四表示,如果使用其人工智能产品的客户因生成内容而被起诉侵犯版权,该公司将承担法律责任。微软将承担由第三方提出的任何索赔所带来的潜在法律风险,只要该公司的客户使用其产品中内置的「防护措施和内容过滤器」。它提供了功能以减少AI返回侵权内容的可能性。随着生成式AI(计算机程序能够生成文本、图像、声音等数据)的广泛应用,用户对这种技术无需参考原作者即可生成内容产生了担忧。站长网2023-09-08 09:19:310001苹果发布iOS 17 语音助手不用再说“嘿 Siri”了
今日凌晨,苹果发布了iOS17预览版,为电话app、FaceTime通话app和信息app的通信体验带来重大提升,iOS17还带来两项全新体验:Journalapp以及StandBy功能。支持设备方面,iOS17不再支持iPhone8、iPhone8Plus和iPhoneX三款机型。站长网2023-06-06 16:24:520000