开源大模型代码短板补上了!新羊驼Python赛过ChatGPT,10万上下文免费可商用
Llama2系列又上新,这回是Meta官方出品的开源编程大模型Code Llama。
模型一发布,官方直接给贴了个“最强”标签,还强调了一把“免费可商用”。
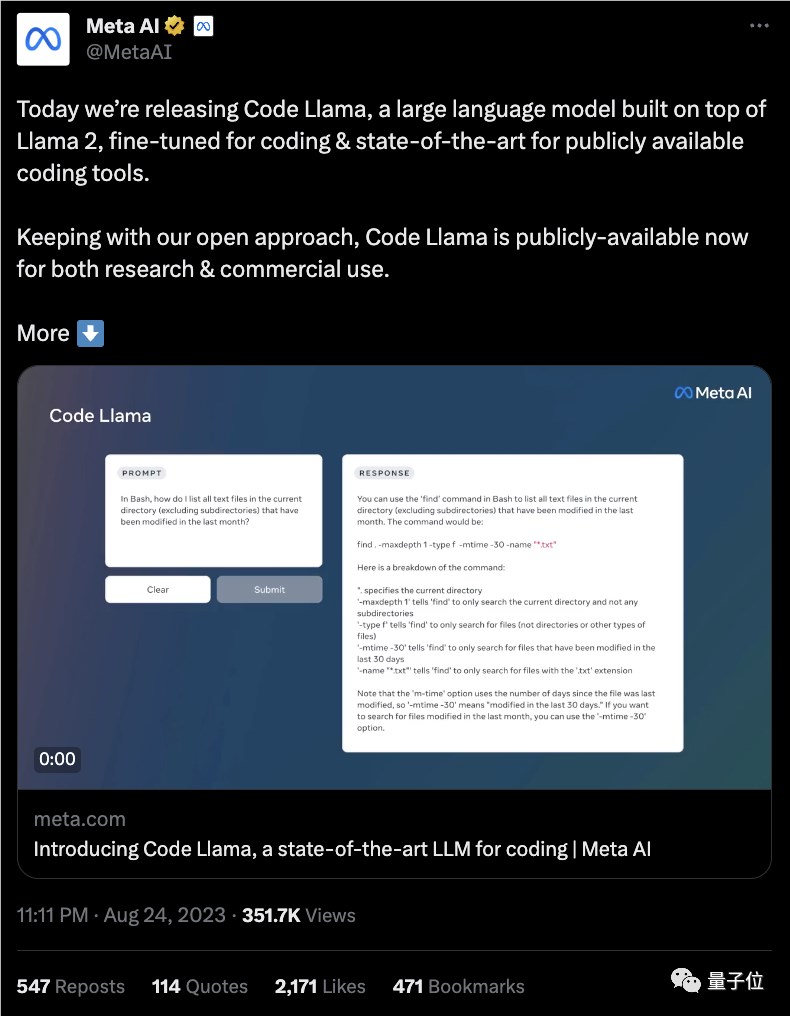
关键是,Code Llama支持10万token上下文,这可把网友们乐坏了:这是一口气读6000行Python代码不费劲的节奏啊。
OpenAI创始成员Karpathy也闻讯前来围观,还指出了隐藏在论文中的“华点”:Code Llama没有公布的一个“unnatural”版本,性能已经超过ChatGPT,逼近GPT-4。
支持10万token上下文
具体而言,Code Llama可以说是Llama2的代码专用版,你既可以通过聊天的方式让它生成代码、解决编程问题,也可以用它来调试代码。
支持的语言包括Python、C 、Java、PHP、Typescript(Javascript)、C#和Bash等。

Meta提供了Code Llama的三个不同版本:
Code Llama,基础代码模型;
Code Llama-Python,Python微调版;
Code Llama-Instruct,自然语言指令微调版。
其中,Python微调版是在1000亿token的Python代码数据上进行微调的。
而Instruct版则能够更好地理解自然语言提示。
和Llama2一样,Code Llama的3个版本各有3种不同尺寸的模型可供选择,分别是7B、13B和34B。
每个模型都被喂进了5000亿token的代码及代码相关数据。

Meta提到,其中7B模型可以在单个GPU上运行。
另外,7B和13B的基础模型和Instruct版模型都有FIM(fill-in-the-middle)功能。也就是说,它们具备代码填充的能力,可以被用到IDE的代码自动补全场景中。

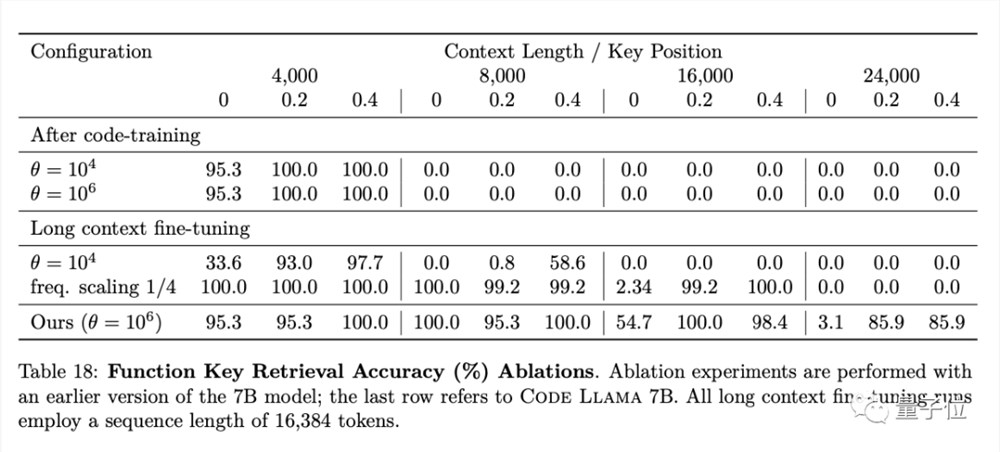
而最受网友关注的一个功能亮点是,Code Llama的全系列模型都进行了长序列上下文微调,最长支持10万token上下文。
这就意味着,你可以把整个代码库直接塞给Code Llama,再也不用担心大模型帮你调代码的时候根本不理解你想要啥。
有网友就提到,目前GPT-4、GitHub Copliot在实际使用中的一大问题,就是上下文窗口太短,理解不了项目的整体需求。

不过,论文提到,当提示长度超过1.6万token时,Code Llama全系列模型的检索准确性(retrieval accuracy)都有所下降。
最强开源编程大模型
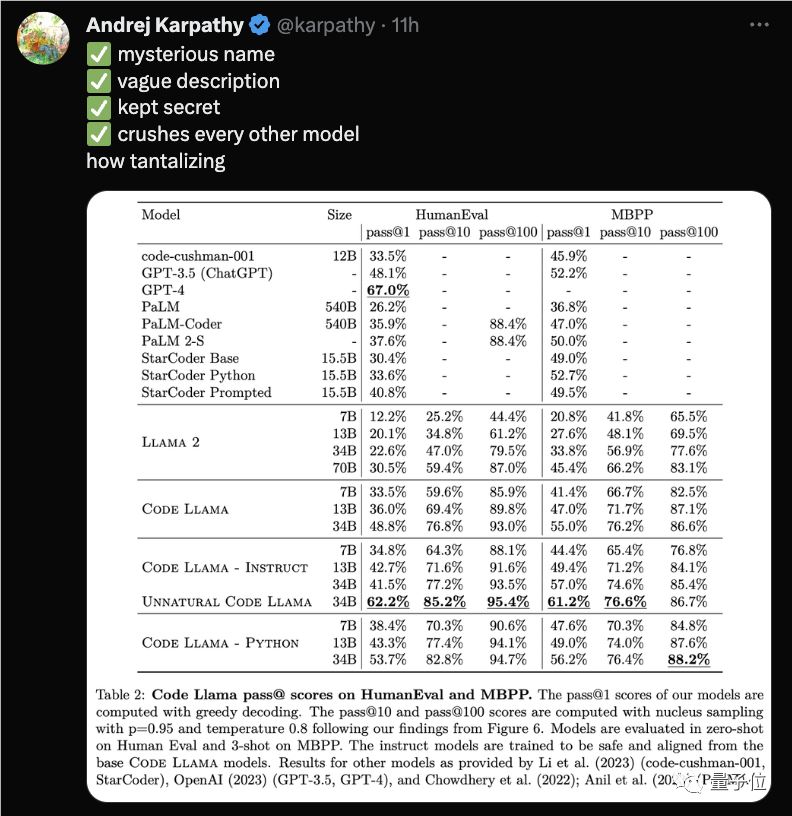
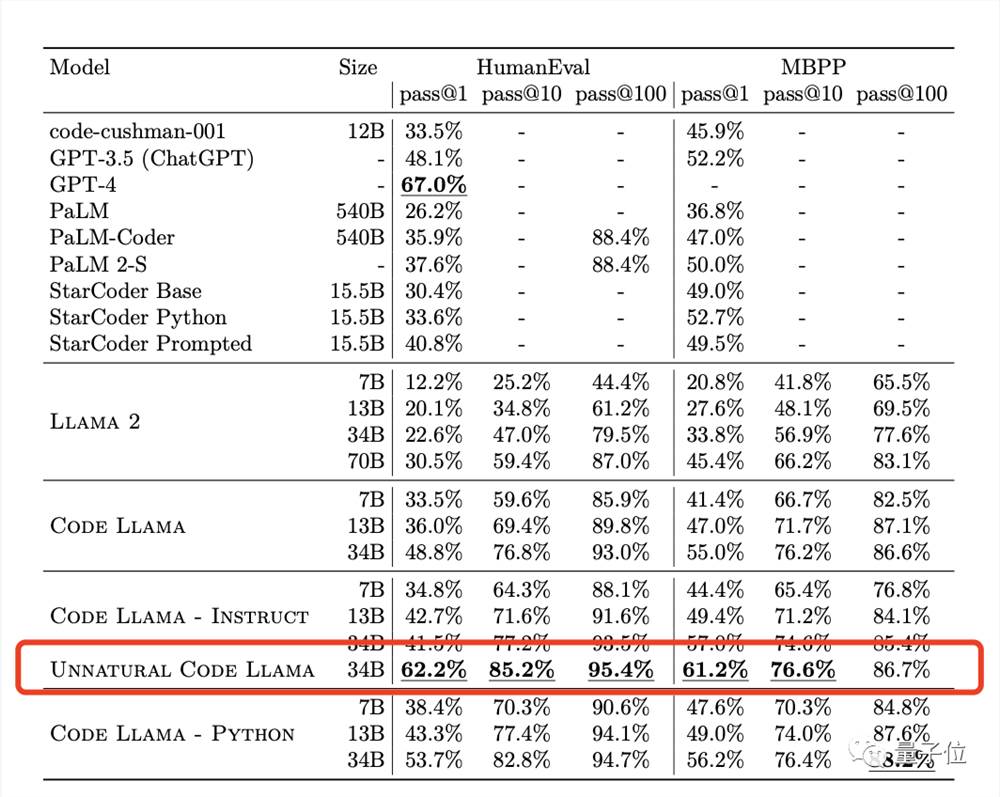
Meta分别在HumanEval和MBPP上测试了Code Llama的性能。
结果显示,Code Llama的表现在一众开源模型中位列第一,超过了Llama2。
具体来说,Code Llama-Python34B在HumanEval上得分为53.7%,在MBPP上得分为56.2%,超过了GPT-3.5(ChatGPT)的48.1%和52.2%。
基础模型版本和Instruct版本也有接近GPT-3.5的表现。

值得一提的是,在论文中,Meta还测试了一个“unnatural”34B版本,性能碾压一众模型,包括ChatGPT,仅略逊于GPT-4。
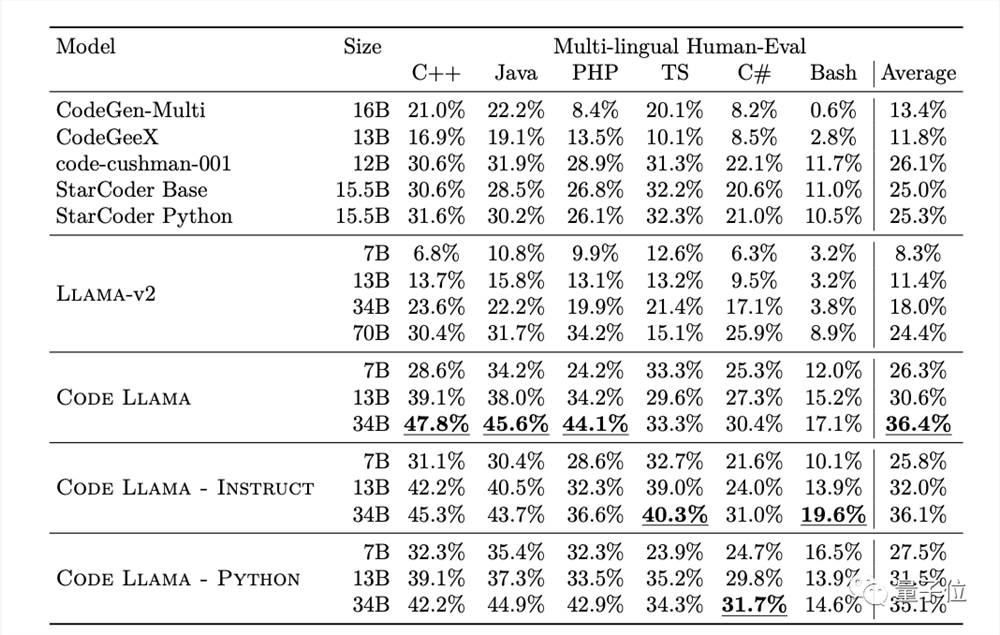
另外,Meta也在更多样化的编程语言数据集上评估了Code Llama的表现。
在任何语言的代码生成中,Code Llama都优于相同大小的Llama2。从综合得分来看,Code Llama的7B模型甚至超过了Llama2的70B模型。
同时,Code Llama7B的表现也超过了CodeGen-Multi和StarCoder等编程大语言模型,水平与Codex相当。
如果你对Code Llama感兴趣,GitHub项目链接文末奉上~
不过,想要获得代码和模型权重,还得先给Meta发个申请。
参考链接:
[1]GitHub项目页:https://github.com/facebookresearch/codellama
[2]https://ai.meta.com/blog/code-llama-large-language-model-coding/
[3]https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
Anthropic公司宣布Claude登陆欧洲市场 已在Apple App Store上线
Anthropic公司宣布旗下聊天机器人Claude正式登陆欧洲市场,目前已在AppleAppStore上架,为用户提供更便捷的使用体验。除了在iOS应用程序上的推出外,Anthropic还推出了新的团队计划,旨在为企业用户提供更高的使用限制和更强大的管理功能。此次更新还包括对服务条款、条件和隐私政策的更新。站长网2024-05-14 16:29:030001抖音生活服务上线数据平台「生意经」
抖音生活服务宣布官方数据平台「生意经」上线,平台提供官方权威的行业概览、优秀榜单,支持一键生成行业数据报告并定期推送,节省数据分析时间,提高数据使用效率,解决经营中的数据难题,帮助合作伙伴从数据中找到经营提升点和生意机会点。站长网2023-06-03 10:46:250000新SD加速模型!相比LCM模型PCM出图又快又稳
最近,一个新的SD加速模型——PCM已经可以使用了。这个模型不仅解决了原来LCM模型的各种问题,还对AnimateLCM进行了优化,使得直接使用PCM生成动画也能保证质量。以下是PCM针对LCM原有问题的改进点:站长网2024-05-30 11:03:380001Meta 宣布 Purple Llama 倡议,以促进负责任和安全的生成式人工智能开发
Meta今天宣布了一项名为「PurpleLlama」的新倡议,旨在促进人工智能(AI)系统的负责任开发。Meta表示,该项目将逐步提供AI开发社区构建开放生成AI模型所需的所有工具和评估,以确保安全和负责任的方式进行。0000Brave 发布注重隐私保护图像和视频搜索功能 人工智能内容生成导致谷歌搜索变得更糟
站长之家(ChinaZ.com)8月4日消息:Brave网络浏览器的开发商BraveSoftware为了减少对「大型科技」竞争对手的依赖,该公司调整了其搜索引擎,使其能够使用自己的图像和视频索引。图片来自Brave该公司表示,BraveSearch(可通过search.brave.com及其浏览器可用)的图像和视频结果将从其自己的索引中获取。站长网2023-08-04 17:51:030000