比OpenAI更快一步,最新开源的MiniGPT-4模型可让开发者提前感受GPT-4识图能力!
迄今为止,GPT-4凭借多模态能力已经成为 AI 领域备受关注的大模型,不过值得注意的是,OpenAI在推出 GPT-4时虽然引入了对图像理解的能力,但并没有在除了 Be myEyes(针对盲人或弱视人士的应用程序和服务)应用程序之外的任何地方提供此功能。
GPT-4对图像理解能力的示例详见:
用户:这幅画有什么好笑的地方?逐一描述它的板块。

图片来源:https://www.reddit.com/r/hmmm/comments/ubab5v/hmmm/
GPT-4:图片显示的是一个 "Lightning Cable "适配器的包装,有三个板块:
板块1:一部智能手机,VGA 连接器(通常用于电脑显示器的大型蓝色15针连接器)插在其充电端口。
板块2:"Lightning Cable "适配器的包装上有一张 VGA 接口的图片。
板块3:VGA 连接器的特写,末端是一个小的 Lightning 连接器(用于为 iPhone 和其他苹果设备充电)。
这张图片的幽默感来自于将一个大的、过时的 VGA 连接器插入一个小的、现代的智能手机充电端口的荒谬性。
近日,来自沙特阿拉伯阿卜杜拉国王科技大学的研究团队推出了一款名为 MiniGPT-4的新模型,以开源的形式提供了此功能。
研究人员还透露,MiniGPT-4具有许多类似于 GPT-4所展示的功能,下文我们也将分享相关的实例。
可执行复杂的视觉语言任务的 MiniGPT-4
该团队发现尽管 GPT-4表现出非凡的能力,但是其特殊能力背后的方法并不为众人所熟知。因此,他们提出「GPT-4具有先进的多模态生成能力的主要原因在于利用了更先进的大型语言模型(LLM)」这一想法。
为了验证这一想法,他们便提出了 MiniGPT-4模型。
根据研究团队发布的论文显示,为了构建 MiniGPT-4,研究人员使用了基于 LLaMA 构建的 Vicuna 作为语言解码器,并使用 BLIP-2视觉语言模型作为视觉解码器。
其中,Vicuna 和 BLIP-2都是开源的。这意味使用开源软件可以用较少钱进行训练和微调,并且没有海量数据和开销,这也是为什么这个模型加上了“mini”的前缀。

在实验中,该团队发现只对原始图像-文本对进行预训练会产生不自然的语言输出,包括重复和零散的句子,缺乏连贯性。为了解决这个问题,其在第二阶段策划了一个高质量、一致性好的数据集,利用对话模板对此模型进行微调,这一步被证明对提高模型的生成可靠性和整体可用性至关重要。
具体来看,研究团队分两个阶段训练了MiniGPT-4模型。
第一阶段,研究团队首先在四张 NVIDIA A100显卡上利用了大约500万个对齐的图像-文本对,让 MiniGPT-4进行了十个小时的训练。在第一阶段之后,Vicuna 能够理解图像。但是 Vicuna 的生成能力受到了很大的影响。
为了解决这个问题并提高可用性,研究人员提出了一种通过模型本身和 ChatGPT 一起创建高质量图像文本对的新方法。因此,展开了第二阶段的微调训练,该模型使用 MiniGPT-4和 ChatGPT 之间的交互生成的3,500个高质量文本图像对进行了改进。ChatGPT 更正了 MiniGPT-4生成的不正确或不准确的图像描述。
这一步显著提高了模型的可靠性和可用性,MiniGPT-4能够连贯地和用户友好地谈论图像,并且只需要在单个 NVIDIA A100上进行七分钟的训练。让研究人员自己都感到惊讶的是,这个阶段的计算效率很高。
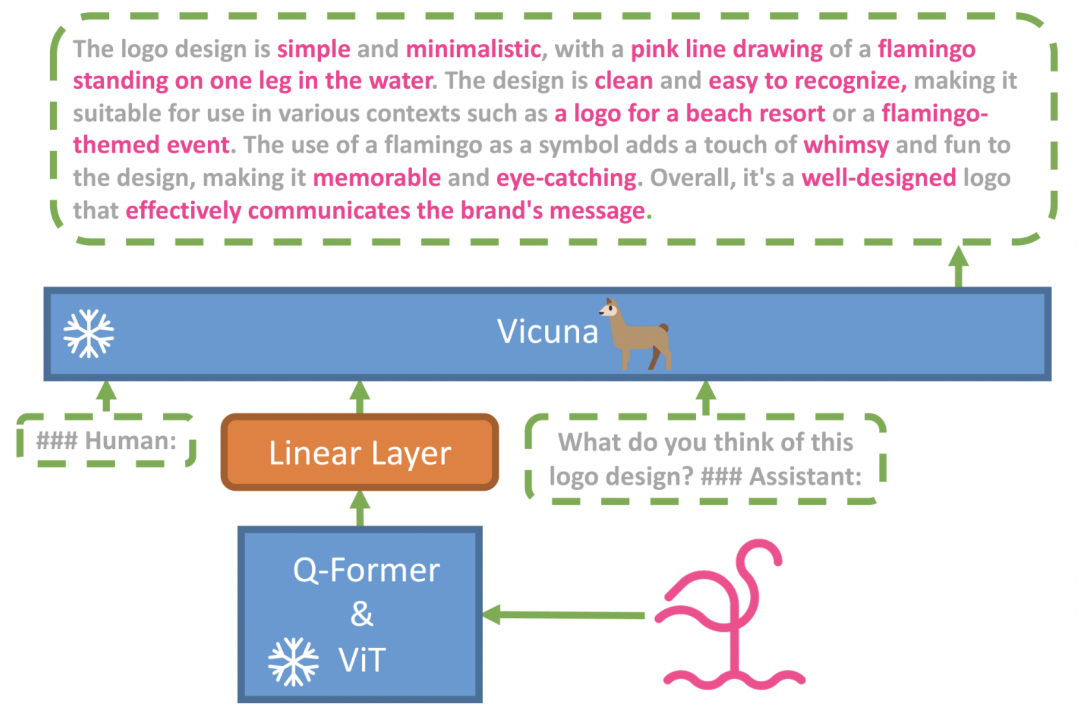
MiniGPT-4架构
MiniGPT-4Vicuna 的语言模型遵循 "Alpaca 公式",使用 ChatGPT 的输出来微调 LLaMA 系列的 Meta 语言模型。据说 Vicuna 与 Google Bard 和 ChatGPT 相当,同样只需相对较小的训练工作量。
当前,该研究团队已经将 MiniGPT-4的代码、预训练的模型和收集的数据集在 GitHub 上开源:https://minigpt-4.github.io/。
拥有和 GPT-4相似的图片解析功能
正如开头所述,该研究团队推出的 MiniGPT-4拥有和 GPT-4相似的功能。譬如:
给它一张图,便能生成详细的图像描述:

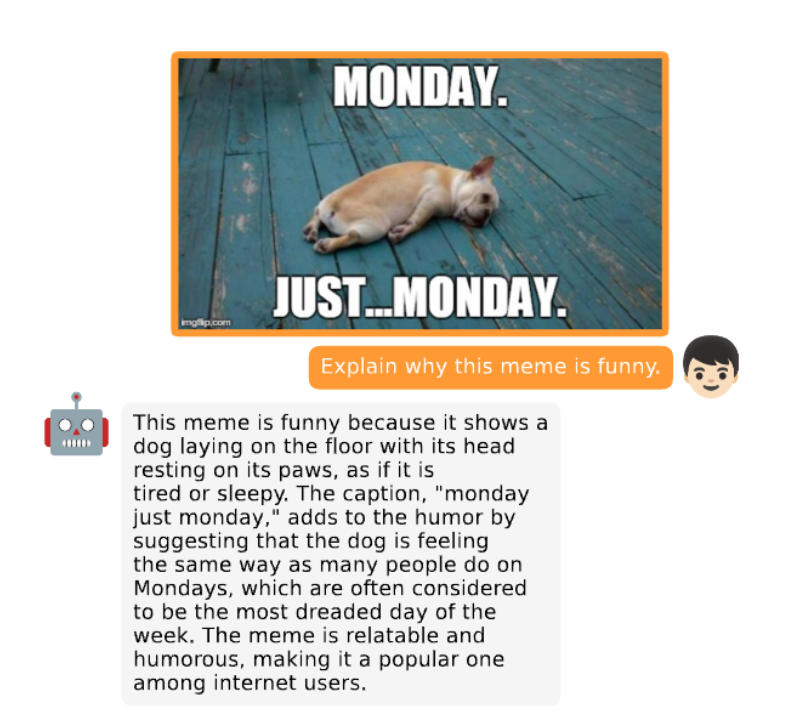
也能讲出图片中搞笑、有趣的部分:「星期一通常被认为是一周中最令人恐惧的一天」。
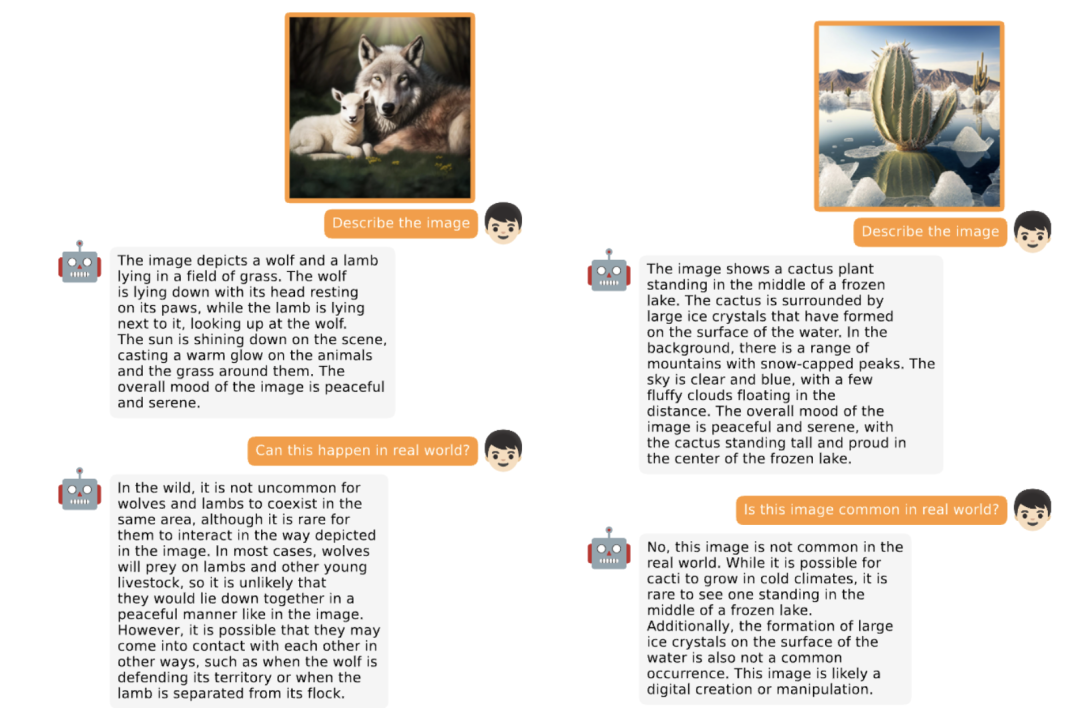
还能在进一步交互中发现不寻常的内容,如:虽然仙人掌有可能在寒冷的气候条件下生长,但很少看到仙人掌生长站在冰冻的湖泊中间。此外,水面上形成的大冰晶也不是常见的现象。
于是,MiniGPT-4给出了自己的见解:这张图片很可能是数字创作或操控的。
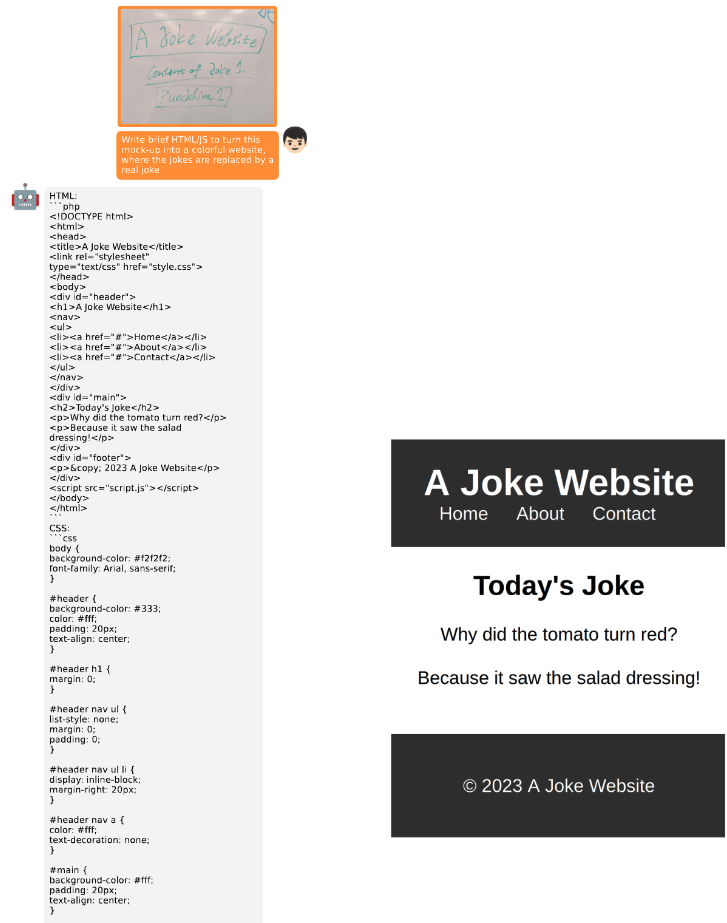
当然,和 GPT-4演示的一样,MiniGPT-4也能根据手绘草图生成网站:
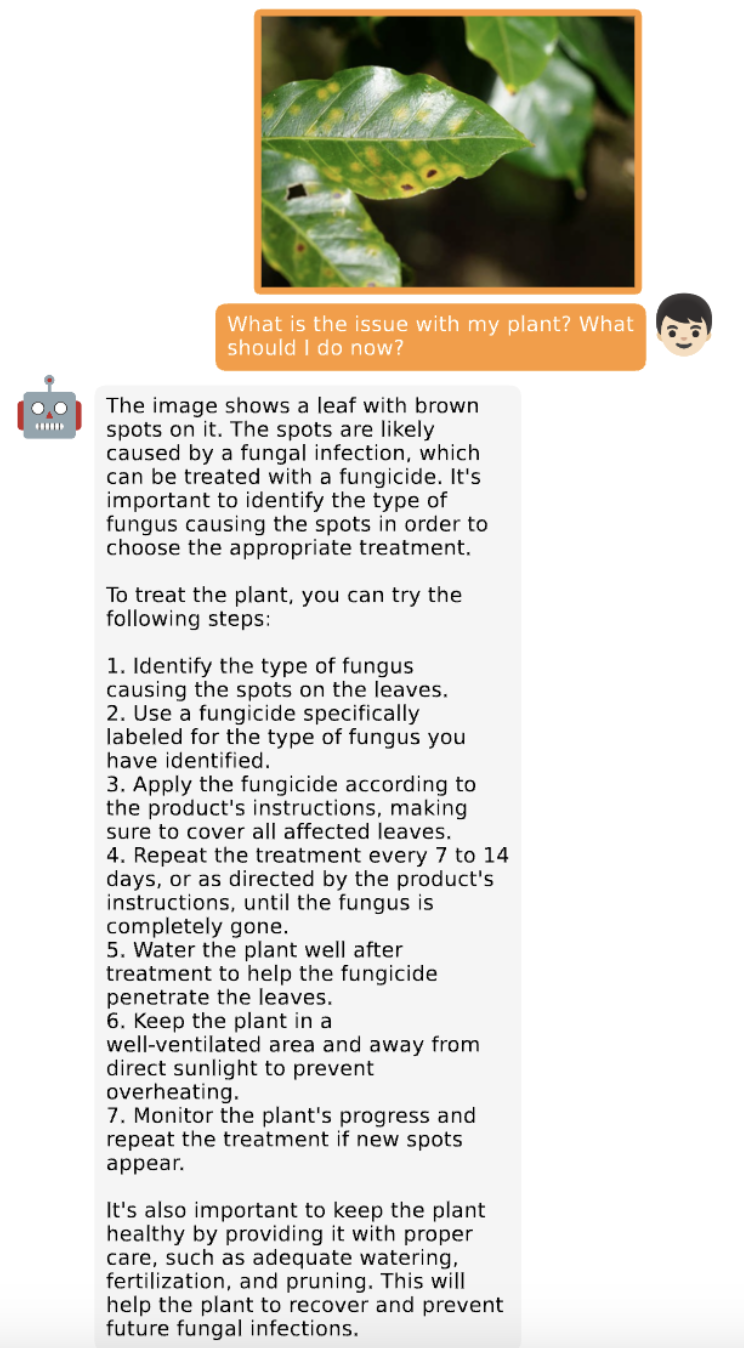
识别图像中的问题并提供解决方案:
以及创造诗歌或说唱歌曲的灵感:
此外,也能根据图片续写故事,给产品做广告,对图像展现的画面进行评论、检索与图片有关的事实,以及当给定一张准备好的菜肴照片时,该模型可以输出(可能)与之匹配的食谱或者生成一个适合视障人士的图像描述。
开源类 GPT-4模型层出不穷
鉴于 OpenAI 没有透露太多关于 GPT-4架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法的细节,强大的 LLM 的开源 MiniGPT-4可能在研究方面具有重要意义。
对于 MiniGPT-4的到来,也引发了一些 HN 网友的热议,有网友表示:
在技术层面上,这个研究团队正在做一些非常简单的事情--将 BLIP2的 ViT-L Q-former,用一个线性层连接到 Vicuna-13B,并在一些图像-文本对的数据集上只训练这个小层。
但结果是相当惊人的。它完全打败了 Openflamingo 和甚至原始的 blip2模型。最重要的是,它比 OpenAl 的 GPT-4图像模态更早到达。(这是)开源人工智能的真正胜利。
也有媒体评价到,「MiniGPT-4是开源社区在很短时间内取得快速成功的另一个案例。前几天,开源聊天机器人 OpenAssistant推出,使用从志愿者那里收集的指导数据进行训练,并打算最终成为一个 ChatGPT 的开源平替。这表明纯AI 模型公司的护城河可能没有那么高。在这种趋势下,对于 OpenAI 公司而言,首先应该专注于使用 ChatGPT 插件为 GPT-4建立一个合作伙伴生态系统,而不是现在就训练 GPT-5,这是有意义的。」
事实上,除了OpenAssistant、MiniGPT-4之外,GitHub 上也有网友盘点了近段时间来诞生的许多开源模型(https://github.com/nichtdax/awesome-totally-open-chatgpt),如Databricks 推出的 Dolly 模型、类 ChatGPT 的PaLM-rlhf-pytorch、OpenChatKit 等等,为此,你认为开源大模型在此趋势下会迎来什么样的发展机遇?欢迎留言分享你的看法。
关于 MiniGPT-4模型的更多内容可参考:
项目地址:https://minigpt-4.github.io/
GitHub地址:https://github.com/Vision-CAIR/MiniGPT-4
论文地址:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
参考:
https://the-decoder.com/minigpt-4-is-another-example-of-open-source-ai-on-the-rise/
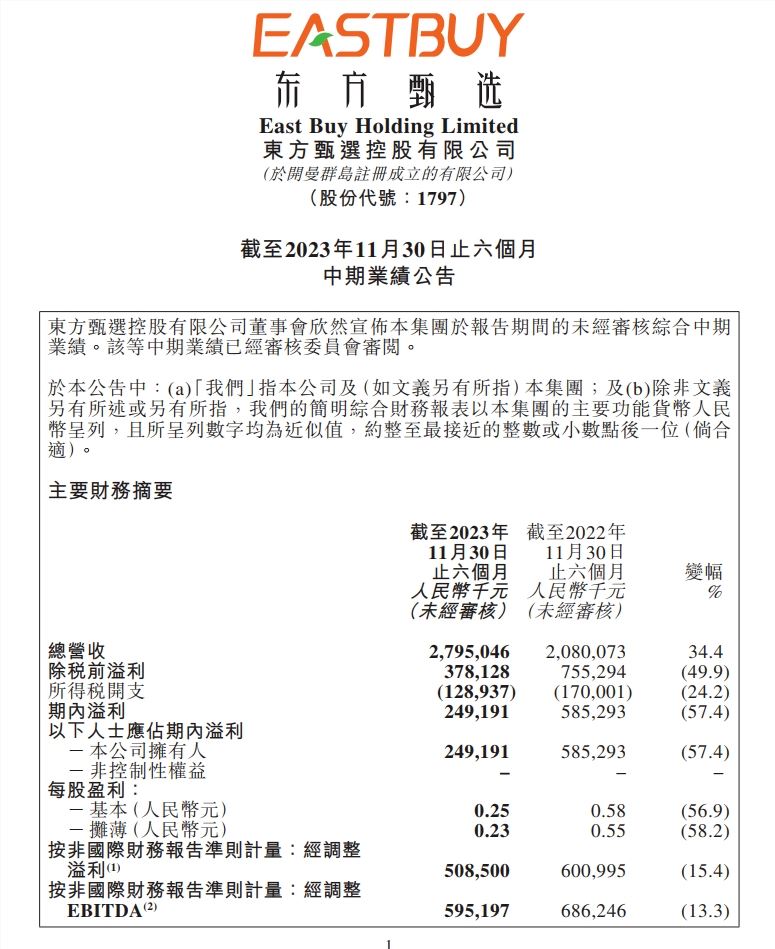
东方甄选入驻拼多多,出抖计划再进一步
东方甄选的抖音出逃计划,又有新动作了。最近,东方甄选悄悄入驻了拼多多。比起之前入驻淘宝时,大张旗鼓地联合宣传,这一次,东方甄选看上去格外低调,可以说是不动声色。如果说,之前出抖入淘,东方甄选还有种跟抖音明面叫嚣的意味在,现在它的种种动作,更像在以一种平常心稳步推进。站长网2024-03-15 09:17:390000AI大模型的风过去了?不,是离我们越来越近了
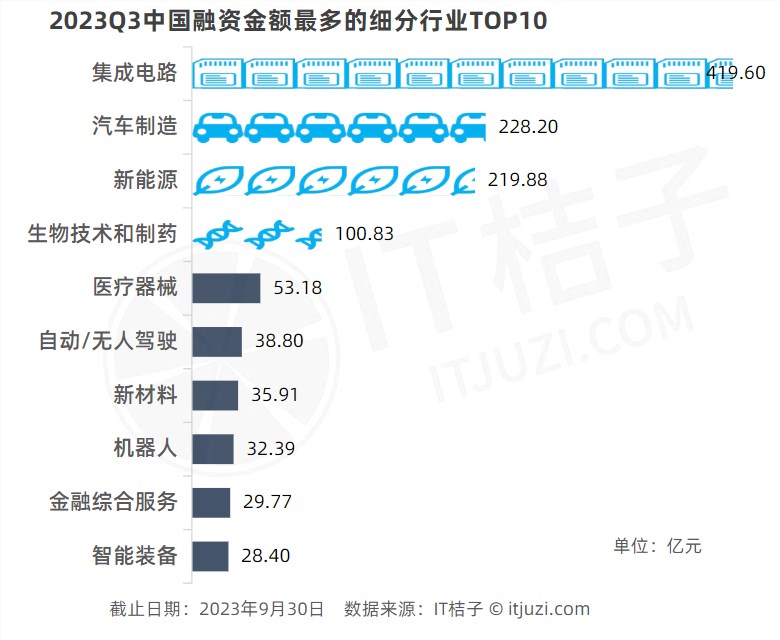
OpenAI摊牌了。不再掩藏锋芒,拿年初预测的2亿美元收入做挡箭牌,“我们的年营收达到了13亿美元。”10月中旬SamAltman终于透露出来。13亿美元,同比增长4500%。国内。资本和公众的视线越来越多地放在局势变幻、芯片和造车上。△三季度融资行业龙虎榜,大模型暂时滑落榜下来源:IT桔子,2023年三季度中国新经济创业投资数据分析报告站长网2023-11-02 14:01:030000独立开发变现周刊(第111期):AI Excel公式生成器,月收入2万美元
目录1、Opengpts:开源的基于LangChain等基础上的GPTs交互式体验代码库2、sshx:开源的web协作终端3、Tally:一个简单的表单构建器,月收入7万美元4、一个AIExcel公式生成器,月收入2万美元1、Opengpts:开源的基于LangChain等基础上的GPTs交互式体验代码库站长网2023-11-10 09:20:200001本田等日本汽车制造商引入生成式AI进行车辆设计
**划重点:**🌐多家日本汽车制造商,包括本田、索尼本田移动(SHM)和斯巴鲁,正采用生成式人工智能技术进行车辆设计。🌐生成式人工智能在汽车设计中的应用是众多汽车制造商探索的方向,这标志着技术在汽车工业中的不断演进。在全球汽车行业竞争加剧的背景下,日本汽车制造商正迎来一项革命性的技术进步,他们正在引入生成式人工智能(GenerativeAI)来协助车辆设计。站长网2023-11-15 18:58:000000微软向云计算客户提供 AMD 替代 Nvidia AI 处理器
划重点:-微软计划为云计算客户提供AMD人工智能芯片,与Nvidia竞争,详细信息将在下周的开发者大会上公布。-微软将推出新型Cobalt100定制处理器的预览,预计性能比其他基于ArmHoldings技术的处理器高出40%。-AMD人工智能芯片集群MI300X将通过Azure云计算服务销售,为客户提供Nvidia的替代方案。站长网2024-05-17 16:44:100000