《纽约时报》禁止人工智能公司使用其内容进行模型算法训练
据 Adweek 报道,纽约时报在 8 月初更新了其服务条款,禁止将其文章和图片用于人工智能训练。此举发生在科技公司继续通过像 ChatGPT 和 Google Bard 这样的 AI 语言应用获取数据的大规模未经授权抓取的情况下。

新的条款禁止未经明确书面许可使用时报的内容,包括文章、视频、图片和元数据,用于训练任何 AI 模型。在服务条款的第 2.1 节中,纽约时报称其内容仅供读者的「个人非商业使用」,非商业使用不包括「开发任何软件程序,包括但不限于训练机器学习或人工智能(AI)系统」。
在接下来的第 4.1 节中,条款规定,未经纽约时报的事先书面同意,任何人都不得「将内容用于开发任何软件程序,包括但不限于训练机器学习或人工智能(AI)系统。」
纽约时报还概述了违反限制规定的后果:「进行禁止使用服务的行为可能导致对用户及协助用户的人员的民事、刑事和/或行政处罚、罚款或制裁。」
尽管听起来很威胁,但限制性使用条款以前并没有阻止将整个互联网转化为机器学习数据集。目前所有大型可用的语言模型,包括 OpenAI 的 GPT-4、Anthropic 的 Claude 2、Meta 的 Llama 2 和 Google 的 PaLM 2,都是在从互联网抓取的大量材料的基础上进行训练的。通过一种称为无监督学习的过程,将 web 数据输入神经网络,使 AI 模型通过分析单词之间的关系获得语言的概念意义。
使用抓取的数据来训练 AI 模型的争议性,在美国法庭上尚未完全解决,已经导致至少一起指控 OpenAI 涉嫌剽窃的诉讼。上周,美联社和其他几家新闻机构发表了一封公开信,称「必须制定法律框架来保护驱动 AI 应用的内容」,其中提出了其他关切。
OpenAI 可能预期未来会面临持续的法律挑战,并已开始采取一些举措,可能是为了应对这些批评,OpenAI 最近宣布,网站运营商现在可以阻止其 GPTBot 网络爬虫抓取其网站。这导致一些网站和作者公开表示将阻止这个爬虫。
微软还在自己的条款和条件中添加了一些新的限制,禁止人们使用其人工智能产品「创建、训练或改进(直接或间接)任何其他人工智能服务」,同时禁止用户从其人工智能工具中抓取或以其他方式提取数据。
目前已经抓取的内容已经成为 GPT-4 的一部分,包括纽约时报的内容。也许我们要等到 GPT-5 才能看到 OpenAI 或其他 AI 供应商是否尊重内容所有者希望被排除在外的愿望。如果没有的话,可能会出现新的 AI 诉讼或法规。
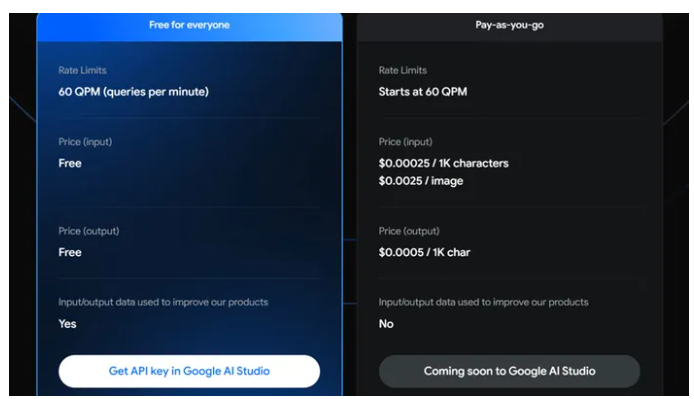
谷歌即将面向企业和开发者提供Gemini Pro API服务
划重点:-💡谷歌通过API向企业和开发者提供了其最强大的大型语言模型Gemini的初步功能。-💡Gemini分为Ultra、Pro和Nano三个规格,并已经通过谷歌云的VertexAI平台提供给企业使用。-💡GeminiPro的API目前免费使用,但每分钟最多只能查询60次,后续将推出按需付费版本。站长网2023-12-14 10:27:490000理想MEGA开放预订 订金5000元
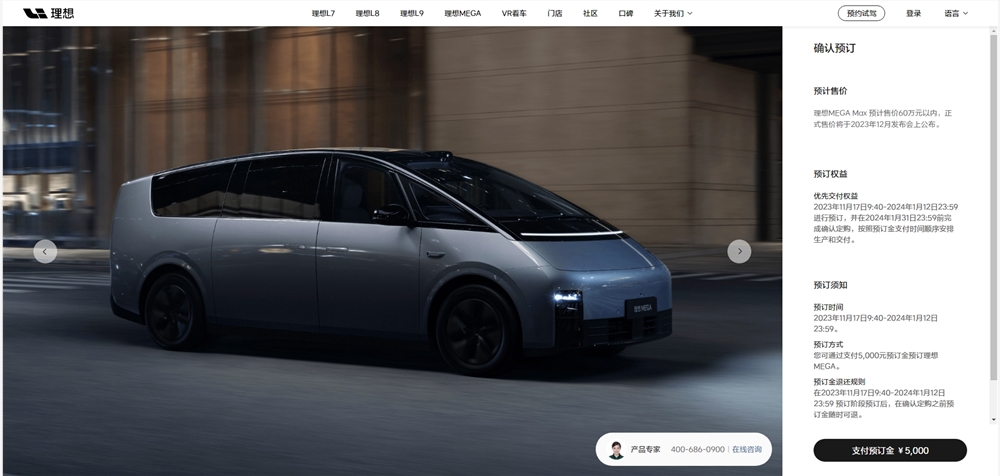
理想MEGA现已在官网开放预订,消费者需支付5000元预定金。该车型的正式售价将在2023年12月的发布会上公布。预订时间为2023年11月17日9:40至2024年1月12日23:59,消费者需在此期间预订。订单确认定购的截止时间是2024年1月31日23:59,按照预定金的支付时间顺序,厂商将安排生产和交付。站长网2023-11-17 10:26:030000AI训练中的缺陷:算法决策或成为未来生活的威胁
要点:AI系统使用描述性标签训练的数据可能导致比人类更严厉的决定。设计AI模型的方式存在深刻缺陷,可能在未来影响决策的各个领域。研究发现,当人们对数据附加描述性标签时,与附加规范标签相比,AI系统的决策更为苛刻。站长网2023-11-28 16:04:060000《银河文明IV:超新星》通过 AlienGPT 技术将 ChatGPT 集成到游戏中
众所周知,游戏行业已开始探索使用人工智能的途径。目前,我们看到这一技术推动的新迭代,如银河文明IV:超新星版将把ChatGPT集成到其游戏,让玩家可以通过AI创建知识、对话对话以及更多方面。这项技术被称为AlienGPT,现在就可以使用。Steam游戏截图站长网2023-05-02 09:38:150001FF汽车5天涨39倍 股价达每股1.65美元
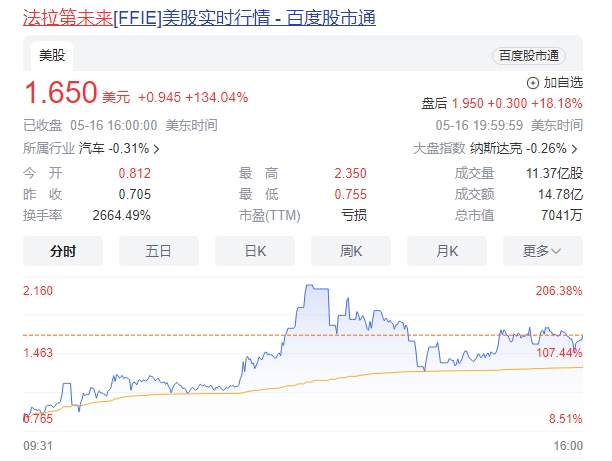
在当地时间5月16日,法拉第未来(FaradayFuture)的股价经历了一场惊心动魄的上涨,连续五日飘红,并在盘中一度飙升超过200%,两次触发了交易暂停机制。截至交易日结束,FF汽车股价成功突破1美元退市警戒线,以每股1.65美元的高位收盘,总市值大幅攀升至7041万美元,单日涨幅高达134%。自5月10日以来,FF汽车的股价累计涨幅更是达到了惊人的3924.39%。站长网2024-05-17 13:53:190000