鸿蒙4里的大模型,能否撑起华为的野心?
一个以大模型作为终极操作系统(AIOS)的AI时代,终将会统合分裂的物联网市场。
这几天,关于鸿蒙4的文章、报道,可谓沸沸扬扬。
一时间,就算是不关注AI赛道的人,都听说了这个新系统里有个大模型,它大致相当于被升级、强化后的Siri。

比如能帮你生成点文章摘要、图片,或是自动订个酒店什么的。
但是,华为的野心,可不止是在手机里干点生成图片、文字的小花活。
人家可是把万物互联的梦想,都寄托在了这个小小的AI之上了呢。
具体来说,就是以手机上的大模型为起点,不断将智能化技术扩散到智能家居、智能汽车、甚至是智能城市之上。
如此,最后就能形成一个“万物互联”的超级终端。
其实,这不只是华为的野心,苹果、高通、荣耀等大厂都进行了类似的布局。
毕竟,大模型与终端的结合,是下一阶段AI战场必争的阵地。
然而,要知道,现在有点竞争力的通用大模型,体量和参数,往往都是一千亿规模往上的。
要想把这么一坨“庞然大物”塞进小小的手机,还要能保证性能,绝非易事。
如果关键的技术问题没处理好,大模型终端化的梦想,最终将难免会沦为镜花水月。
1
可靠性问题
要让大模型进入终端,首先要解决的问题之一,就是输出的可靠性问题。
毕竟,任何使用过大模型的人,几乎都见识过各种各样的幻觉和谬误,而这样的幻觉一旦出现在终端侧,产生的损失和后果,往往比处理“案头工作”时要严重得多。
例如,在鸿蒙4的发布会上,华为就介绍到:大模型AI小艺,会根据你的地点数据等信息为你个性化推荐信息。
以出国旅行为例,在出发前小艺会提醒你出行信息,出发后小艺会给你推荐翻译等实用功能,到目的地后,则会展示当地的美食和地点导航。
然而,倘若处理不好可信、可控问题,一个可能出现的情况是:由于信息过时或错误,小艺告诉了你一个已经变迁或不存在的地点。不知情的你被“带偏”后,才恍然自己走了不少冤枉路。
同样地,在智能驾驶领域,倘若车辆上的大模型在终端侧输出不可靠,就会导致规划决策结果出现不合理、不符合交通规则的情况,影响车辆的行驶效率和安全性。
类似的情况,如果出现在2B端,只要存在1%的偏差,都将给企业埋下风险的种子,成为落地的门槛。
目前,关于大模型可信、可控方面的问题,学术界没有完美解,只能在各个环节逐步逼近。
但有一点却是业内的共识,那就是:预训练数据越多、越广,就越可以提高大模型的泛化能力和鲁棒性,从而减少生成幻觉和错误的可能性。
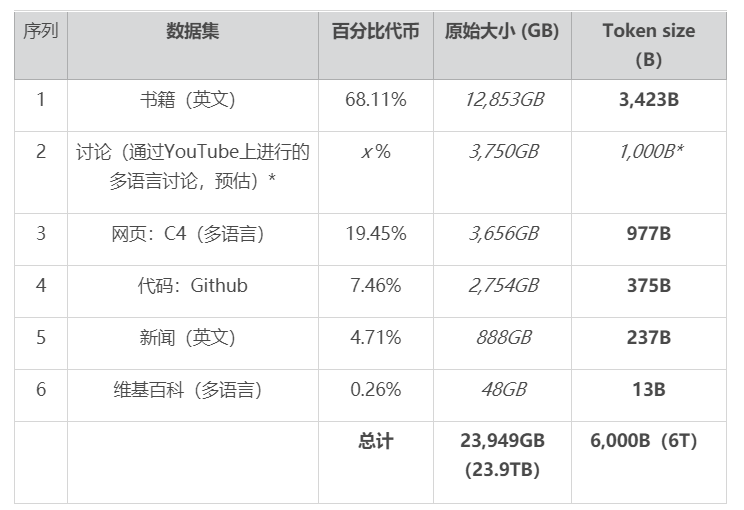
在之前披露的信息中,华为对外宣称自身的盘古大模型涉及项目超过1000个,除了学习大量通用知识外,盘古还深耕金融、政务、气象、医疗、健康、互联网、教育等行业,每个行业数据量超过500亿tokens。
从数据层面来看,可谓涵盖面甚广。
但需要注意的是,盘古大模型实际上分为了四个版本,分别是100亿参数、380亿参数、710亿参数和1000亿参数。
考虑到手机的硬件性能和运行环境,鸿蒙4中搭载的,很有可能是100亿参数版本的盘古大模型。
想在这100亿的数据规模上,保障大模型的准确性、可靠性,可能吗?
对于这个问题,华为有两种可能的解决方案:
首先一种,是直接将鸿蒙4中的大模型,变成一个看似通用的“专用”大模型。
这样的思路,其实是一种小而精的策略。
因为在某些特定场景,预训练数据的质量和相关性,远比其数量和范围要重要得多。
具体到手机方面,由于人们使用手机的场景、用途,都是相对比较固定的,例如查天气、导航、订外卖、订酒店等,因此华为可以根据这些特定的“手机场景”,针对性地搜集相应的高质量数据。
而经由这种高质量、高相关性数据训练出来的紧凑型语言模型,有可能在特定任务和场景上表现得比大参数模型更出色。
而第二种方式,则是通过“压缩”的方式,在不牺牲性能和精度的情况下,降低模型的参数。
2
化大为小
可以说,压缩功力的强弱,直接关系到了端侧大模型的可靠性、质量。也是大模型走向端侧的必要条件。
因为只有把模型压缩到了完全能在终端侧运行,摆脱云端计算的地步,大模型才能适应更多对延迟性要求高的边缘场景。
例如,智能汽车对于模型运行的可靠性和延迟要就非常高,在实时变化的路况中,如果在云端运行大模型,并且使用网络把结果传送到终端,肯定无法满足智能汽车的需求。同时,完全终端化、本地化的运行方式,也是出于对用户数据、隐私方面的一种考虑。
这也是为什么,颇为重视隐私的苹果,也宣布自己将要发布的AppleGPT将采取完全本地化的方式运行。
同样地,在鸿蒙4上,华为表示AI“小艺”相关的数据和学习的都是在端侧推理,以保障用户的安全和隐私。
既然“压缩”是大模型终端化的必要条件,那么目前在这方面,华为和其他大厂的差距究竟如何呢?
在之前的WAIC大会上,高通展示的手机大模型,已经能做到在安卓手机上,直接运行参数规模超过10亿的StableDiffusion,而且生成效果也还过得去。
而这背后,靠的正是不俗的模型压缩能力。
通过量化、压缩、条件计算、神经网络架构搜索和编译,高通在不牺牲太多精度的前提下对AI模型进行了缩减。
比如在在量化方面,高通将FP32模型量化压缩到INT4模型,实现了64倍内存和计算能效提升。
在这方面,华为自身的昇腾模型压缩工具,也提供了一系列的模型压缩方法,根据量化方法不同,分为基于calibration的量化和基于retrain的量化。
而上述两种量化方法,根据量化对象不同,分为权重量化和数据量化。
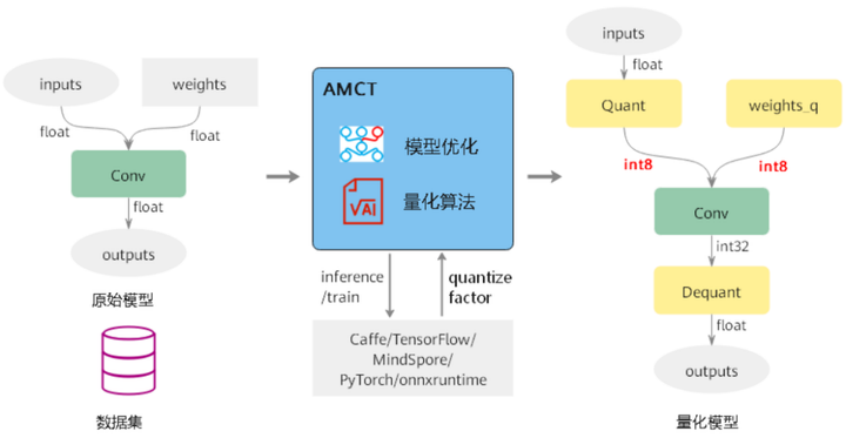
而具体来说,权重量化对模型影响不大,而数据量化对模型影响比较大。
这样的影响,可以用一个形象的比喻来说明:
压缩大模型就像切西瓜,而权重量化就像是把西瓜的种子变成整数,数据量化就像是把西瓜的果肉和果汁变成整数。
一般人吃西瓜的时候,更在乎的往往是果肉,而不是种子。
同理,权重是模型的一部分,但不是最重要的部分,我们运行模型的时候,主要关注的是输入输出数据的准确性和多少。
也正因如此,在用户可感知到的范围内,权重量化对模型性能的影响是较小的。
而这也是为什么,谷歌、腾讯、百度等在将模型压缩技术结合到移动端时,使用的也大多是权重量化。
例如腾讯提出的NCNN和MNN模型,主要就是存储模型中各层的权重值。ncnn模型中含有扩展字段,用于兼容不同权重值的存储方式。
在科技发展的路径上,有一条真理,那就是:正确、合理的技术,往往都存在着一种趋同化的“最优解”,很少会存在什么“秘技”。
说到这里,问题来了:既然在可预见的未来,各个大厂在模型压缩、量化方面的技术,大体上都是趋同、相近的,那么在这场“终端AI”竞赛中,真正决定性的制胜因素,究竟是什么?
3
总结
在终端大模型的较量中,除了模型压缩、端侧芯片外,最主要的因素,就剩下了终端软件生态的搭建。
由于端侧芯片实在是一个太大的话题,受于篇幅所限,此处不再赘述,将来会单独用一整篇的内容加以分析。
这里主要重点说下终端软件生态。
一个可以预见的未来是:由于终端设备的多样性,碎片性,将来的终端大模型,必定会出现针对不同应用场景的“智能助理”。
例如,音箱中的智能助理,可以帮助我们管理智能家居;在工作场合,耳机中的智能助理可以作为秘书帮助处理会议纪要等工作。
在这种情况下,谁若能率先取得多模态方向上的突破,针对不同场景微调,提供多样化、专属化的智能助理,谁就能在终端大模型的长跑中,处于领先优势。
此外,考虑到手机、智能家居等终端设备,具有很强的“私有性”,因此,如何根据用户的个人喜好和使用习惯,进行自适应学习,并提供个性化的建议和服务,就成了终端大模型能否长期陪伴用户的关键因素。
而倘若上述问题,都得到了较好的解决,那么一个以大模型作为终极操作系统(AIOS)的AI时代,就迟早会到来。
到了那时,分散、割裂、碎片化的物联网应用市场,也终将被大模型AIOS统合。
微信:严查公众号标题党!典型案例公布
快科技5月30日消息,如今自媒体时代各种标题党层出不穷,对大家的日常信息获取造成了极大困扰,各大平台也在不断加强治理。今天微信公众平台运营中心发文表示,近期发现部分运营者发布的文章标题具有一定混淆性、煽动性或夸大性,容易导致用户对文章内容产生误判,影响其阅读体验。微信强调,文章标题是用户识别文章内容的首要依据,平台建议运营者在创作内容时使用更加准确、清晰、能体现文章内容主旨的标题。站长网2024-05-31 08:05:410000谷歌认真起来,就没 OpenAI 什么事了!创始人亲自组队创建“杀手级”多模态 AI 模型
谷歌正在计划如何利用即将推出的大型语言模型系列Gemini来取代ChatGPT。截至目前,OpenAI大语言模型在AI竞赛中一直处于领先地位。而强劲优势的背后,离不开微软庞大数据中心基础设施的有力支持。但ChatGPT的主导地位恐怕无法长久持续下去,因为新的、更强大的AI模型正不断涌现,而其中最具战斗力的挑战者就来自谷歌。站长网2023-08-19 16:16:060000据报道,苹果因需求低迷而削减 Vision Pro 产量
划重点:⭐️苹果因预期之外的低需求削减VisionPro生产。⭐️预计2024年销量仅为40万至45万台,远低于市场预期。⭐️调整头戴设备路线图,可能推迟低成本混合现实头盔的推出。据苹果分析师郭明錤称,苹果在VisionPro推出美国以外市场之前就已削减了订单。站长网2024-04-24 11:40:190000阿里云推出通义万相AI绘画大模型
在2023年世界人工智能大会上,阿里云宣布推出了通义大模型家族的新成员——通义万相。据介绍,这是一个进化中的AI绘画模型,能够支持文生图等功能。目前,通义万相已经正式上线,并向公众开放邀测。通义万相作为一款AI绘画模型,它能够通过机器学习和自然语言处理技术,从文本描述中生成对应的图片或画作。这对于那些想要通过文字表达创意的人来说,无疑是一个非常有用的工具。站长网2023-07-08 16:23:070001