《西部世界》真来了!斯坦福爆火「小镇」开源,25个AI智能体恋爱交友|附保姆级教程
【新智元导读】斯坦福25个AI智能体「小镇」终于开源了,GitHub狂揽1.4k星,《西部世界》即将走进现实。
准备好,此前曾轰动整个AI社区的斯坦福智能体小镇,现在已经正式开源!
项目地址:https://github.com/joonspk-research/generative_agents
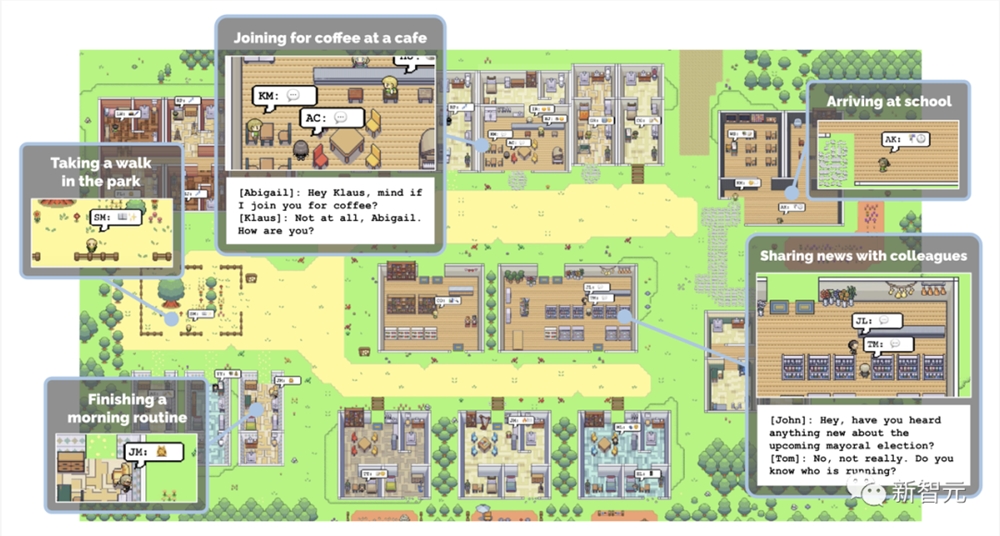
在这个数字化的「西部世界」沙盒虚拟城镇中,有学校、医院、家庭。
25个AI智能体不仅能在这里上班、闲聊、social、交友,甚至还能谈恋爱,而且每个Agent都有自己的个性和背景故事。
不过,它们对于自己生活在模拟中,可是毫不知情。
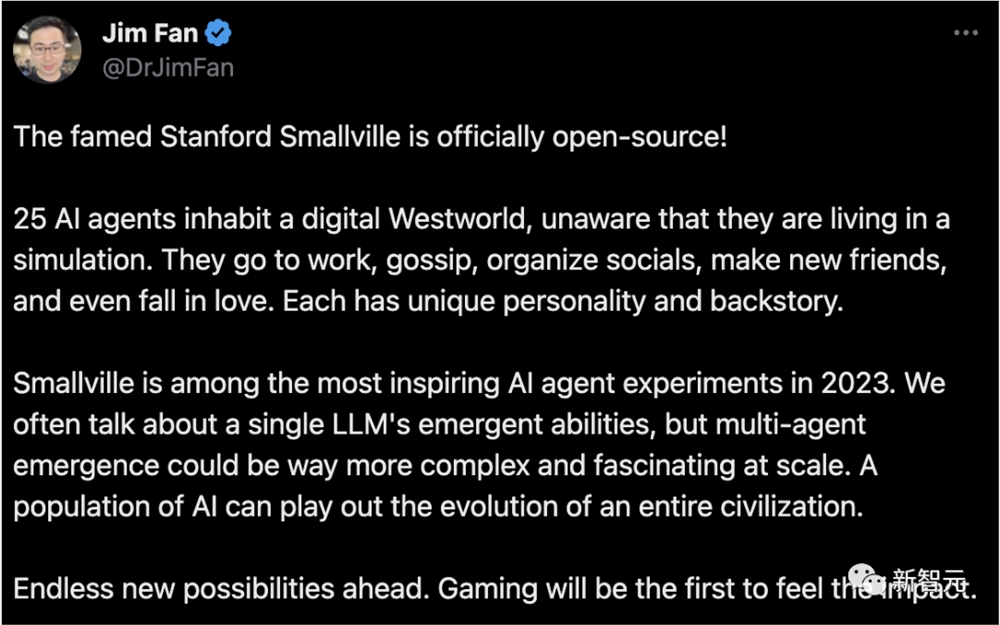
英伟达高级科学家Jim Fan评论道——
斯坦福智能体小镇是2023年最激动人心的AI Agent实验之一。我们常常讨论单个大语言模型的新兴能力,但是现在有了多个AI智能体,情况会更复杂、更引人入胜。
一群AI,可以演绎出整个文明的演化进程。
现在,首先受到影响的,或许就是游戏领域。
总之,前方有无限的新可能!
网友:众游戏厂商们,你们懂我意思吧?
很多人相信,斯坦福的这篇论文,标志着AGI的开始。

可以想象,各种RPG和模拟类游戏都会用上这种技术。
网友们也非常激动,脑洞大开。
有想看神奇宝贝的,有想看谋杀探案故事的,还有想看恋爱综艺的……
「我已经等不及看AI智能体之间的三角恋剧情了。」

「《动物之森》中重复、沉闷的对话,所有村民共有的一维人格系统,都太令人失望了。任天堂赶快学学吧!」

「可以让《模拟人生》移植一下这个吗?」


如果能在《神界》这样的经典RPG游戏中,看到AI在NPC上运行,整个游戏体验都会被颠覆!」

有人还畅想:这项技术在企业空间中也有很多应用场景,比如员工如何和不同的工作环境/流程变化互动。
当然,也有人表示,你们激动个啥?其实我们一直都生活在这样的模拟中,只不过我们的世界有更多的算力罢了。

是的,如果我们把这个虚拟世界放大到足够多倍,我们肯定能看到自己。

Karpathy:AI智能体,就是下一个前沿
此前,前特斯拉总监、OpenAI大牛Karpathy就表示,如今AI智能体才是未来最前沿的方向。
OpenAI的团队最近5年把时间花在了别的地方,但现在Karpathy相信,「Agent代表着AI的一种未来。」

如果某篇论文提出训练大语言模型的不同方法,OpenAI内部的Slack群组中就会有人说:「这个办法我两年半前尝试过,没什么用。」
然而每当有AI智能体从论文出现,所有同事都会很感兴趣。

Karpathy曾将AutoGPT称为快速工程的下一个前沿
「西部世界」中的25个AI智能体
在美剧《西部世界》中,被预设了故事情节的机器人被投放到主题公园,像人类一样行事,然后被重置记忆,在新一天再被投放进自己所在的核心故事情节。
而在今年4月,斯坦福和谷歌的研究者竟然构建出了一个虚拟小镇,让25个AI智能体在其中生存、从事复杂行为,简直堪称是《西部世界》走进现实。

论文地址:https://arxiv.org/pdf/2304.03442.pdf
架构
为了生成智能体,研究者提出了一种全新架构,它扩展了大语言模型,能够使用自然语言存储Agent的经历。
随着时间的推移,这些记忆会被合成为更高级别的反射,智能体可以动态检索它们,来规划自己的行为。
最终,用户可以使用自然语言和全镇的25个Agent都实现交互。
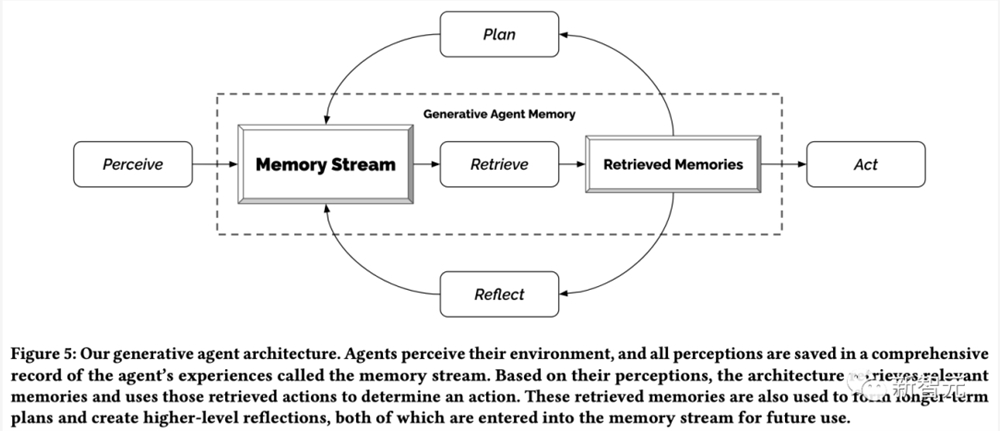
如上,生成式智能体的架构实现了一个「检索」功能。
这一功能将智能体的当前情况作为输入,并返回记忆流的一个子集传递给语言模型。
而检索功能有多种可能的实现方式,具体取决于智能体在决定如何行动时考虑的重要因素。
生成式智能体架构面临一个核心挑战,就是如何管理大量必须保留的事件和记忆。
为了解决这个问题,架构的核心是记忆流(memory stream),即一个记录智能体全部经验的数据库。
智能体可以从记忆流中检索相关记忆,这有助于它规划行动,做出正确反应,并且每次行动都会反馈记录到记忆流中,以便递归地改进未来行动。
另外,研究还引入了第二种类型的记忆——反思(reflection)。反思是智能体根据最近经历生成的高级抽象思考。
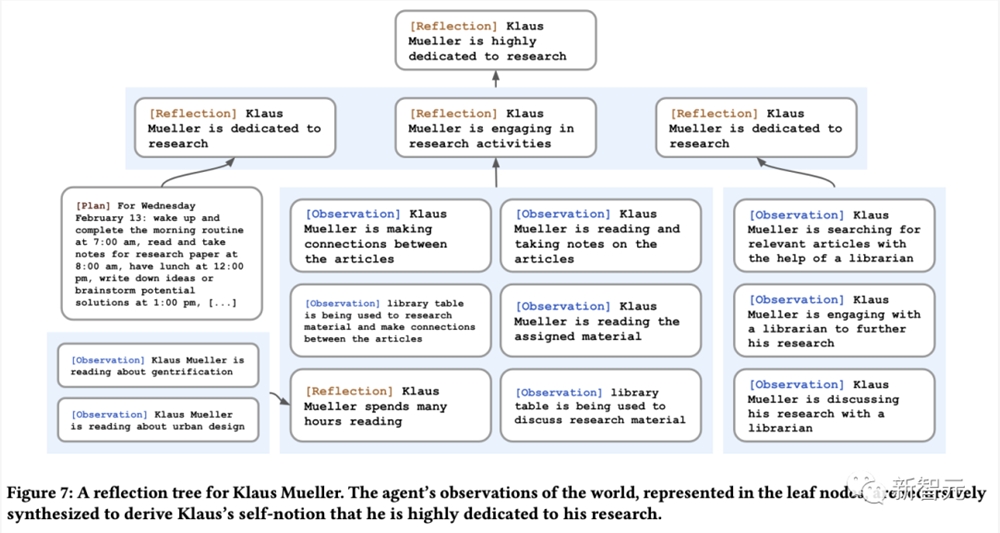
在这项研究中,反思是周期性触发的过程,只有当智能体判断最近一系列事件的重要性评分,累积超过设定阈值时,才会启动反思机制。
生成式智能体为了创建合理的规划,它们会自上而下递归生成更多的细节。
而这些规划最初只是粗略的描述了当日所要做的事情。

在执行规划的过程中,生成智能体会持续感知周围环境,并将感知到的观察结果存储到记忆流中。
通过利用观察结果作为提示,让语言模型决定智能体下一步行动:继续执行当前规划,还是做出其他反应。
在实验评估中,研究人员对这一框架进行了控制评估,以及端到端的评估。
控制评估是为了了解智能体能否独立产生可信个体行为。而端到端评估,是为了了解智能体的涌现能力以及稳定性。
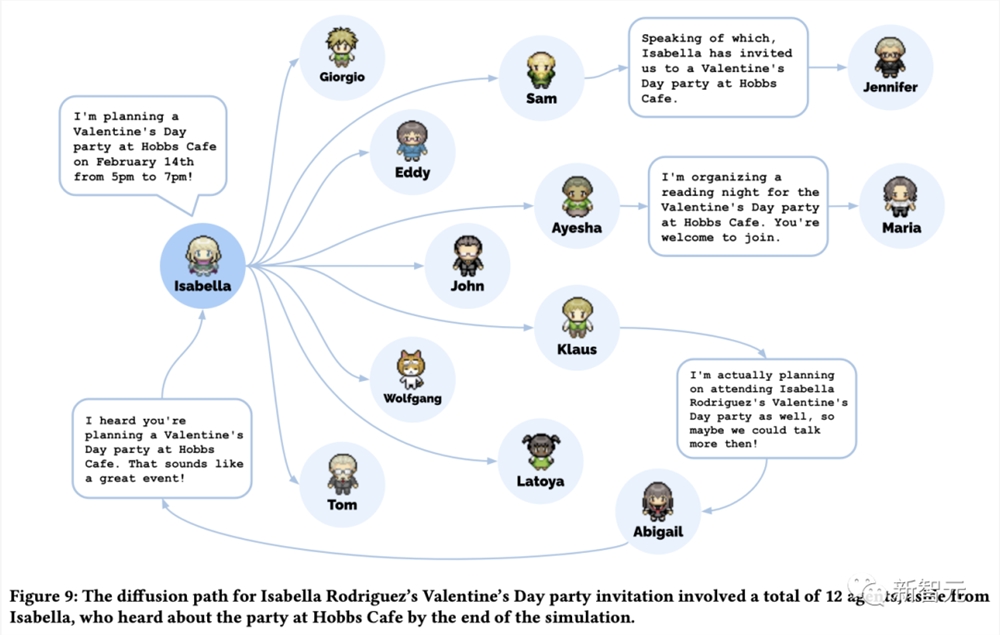
比如,Isabella策划一个情人节party邀请大家来。12个智能体中,7个人还在考虑中(3个人有了别的计划,还有4个人没有想法)。
这一环节与人类相处模式很相似。
像真人一样交互
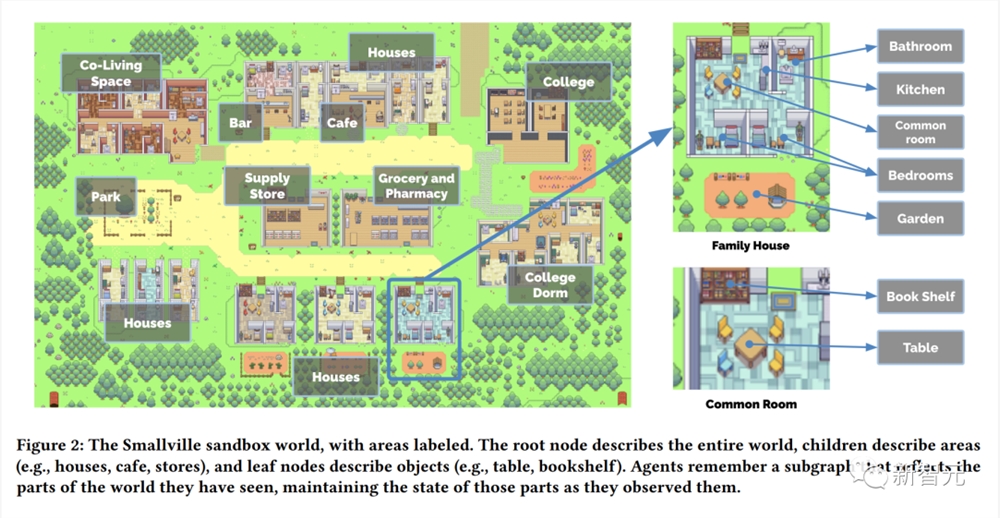
在这个名为Smallville的沙盒世界小镇中,区域会被标记。根节点描述整个世界,子节点描述区域(房屋、咖啡馆、商店),叶节点描述对象(桌子、书架)。
智能体会记住一个子图,这个子图反映了他们所看到的世界的各个部分。
研究者编写了一段自然语言,来描述每个智能体的身份,包括它们的职业、与其他智能体的关系,作为种子记忆。
比如,智能体John Lin的种子记忆就是这样的——
John Lin是一名药店店主,十分乐于助人,一直在寻找使客户更容易获得药物的方法。
John Lin的妻子Mei Lin是大学教授,儿子Eddy Lin正在学习音乐理论,他们住在一起,John Lin非常爱他的家人。
John Lin认识隔壁的老夫妇Sam Moore和Jennifer Moore几年了,John Lin觉得Sam Moore是一个善良的人。
John Lin和他的邻居山本百合子很熟。John Lin知道他的邻居TamaraTaylor和Carmen Ortiz,但从未见过他们。
John Lin和Tom Moreno是药店同事,也是朋友,喜欢一起讨论地方政治等等。
以下就是John Lin度过的一天早晨:6点醒来,开始刷牙、洗澡、吃早餐,在出门工作前,他会见一见自己的妻子Mei和儿子Eddy。
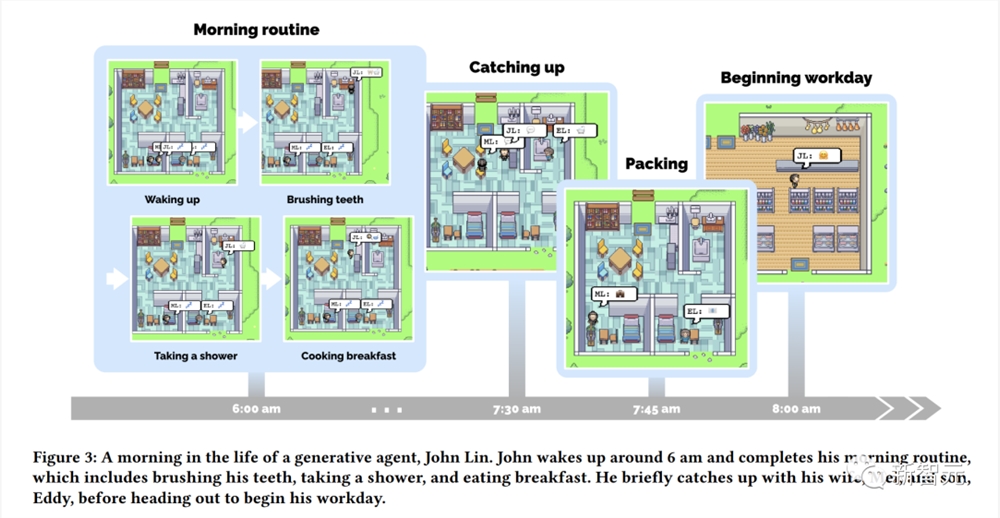
就这样,当模拟开始时,每个智能体都有属于自己的种子记忆。
这些智能体相互之间会发生社会行为。当他们注意到彼此时,可能会进行对话。
随着时间推移,这些智能体会形成新的关系,并且会记住自己与其他智能体的互动。
一个有趣的故事是,在模拟开始时,一个智能体的初始化设定是自己需要组织一个情人节派对。
随后发生的一系列事情,都可能存在失败点,智能体可能不会继续坚持这个意图,或者会忘记告诉他人,甚至可能忘了出现。
幸运的是,在模拟中,情人节派对真实地发生了,许多智能体聚在了一起发生了有趣的互动。
保姆级教程
配置环境
在配置环境之前,首先需要生成一个包含OpenAI API密钥的utils.py文件,并下载必要的软件包。
步骤1. 生成 Utils 文件
在reverie/backend_server文件夹中(reverie.py所在的文件夹),新建一个utils.py文件,并将下面的内容复制粘贴到文件中:
#CopyandpasteyourOpenAIAPIKeyopenai_api_key="<YourOpenAIAPI>"#Putyournamekey_owner="<Name>"maze_assets_loc="../../environment/frontend_server/static_dirs/assets"env_matrix=f"{maze_assets_loc}/the_ville/matrix"env_visuals=f"{maze_assets_loc}/the_ville/visuals"fs_storage="../../environment/frontend_server/storage"fs_temp_storage="../../environment/frontend_server/temp_storage"collision_block_id="32125"#Verbosedebug=True
将 <Your OpenAI API> 替换为你的OpenAI API密钥,将 <name> 替换为你的姓名。
步骤2. 安装requirements.txt
安装requirements.txt文件中列出的所有内容(强烈建议先设置一个虚拟环境)。
目前,团队已在Python3.9.12上进行了测试。
运行模拟
要运行新的模拟,你需要同时启动两个服务器:环境服务器和智能体模拟服务器。
步骤1. 启动环境服务器
由于环境是作为Django项目实现的,因此需要启动Django服务器。
为此,首先在命令行中导航到environment/frontend_server(manage.py所在的位置)。然后运行以下命令:
pythonmanage.pyrunserver
然后,在你喜欢的浏览器中访问https://localhost:8000/。
如果看到「Your environment server is up and running」这个提示,意思就是服务器运行正常。确保环境服务器在运行模拟时持续运行,因此请保持这个命令行标签打开。
(注意:建议使用Chrome或Safari。Firefox可能会出现一些前端故障,但应该不会影响实际模拟。)
步骤2. 启动模拟服务器
打开另一个命令行窗口(你在步骤1中使用的仍在运行环境服务器,需要保持不动)。导航到reverie/backend_server并运行reverie.py来启动模拟服务器:
pythonreverie.py
此时,会出现一个命令行提示询问以下内容:「Enter the name of the forked simulation: 」。
举个例子,现在我们要启动一个包含Isabella Rodriguez、Maria Lopez和Klaus Mueller这3个智能体的模拟,那么就是输入以下内容:
base_the_ville_isabella_maria_klaus
然后,提示将会询问:「Enter the name of the new simulation: 」。
这时只需要随意输入一个名称来表示当前的模拟即可(例如「test-simulation」)。
test-simulation
保持模拟器服务器运行。此阶段,它会显示以下提示:「Enter option」
步骤3. 运行和保存模拟
在浏览器中访问https://localhost:8000/simulator_home,并保持标签打开。
现在你会看到小镇的地图,以及地图上活跃的智能体列表,并且可以使用键盘箭头在地图上移动。
要运行模拟,需要在提示「Enter option」的模拟服务器中输入以下命令:
run<step-count>
请注意,需要将上述的 <step-count> 替换为一个整数,表示要模拟的游戏步数。
例如,如果要模拟100步游戏,就输入run100。其中,一个游戏步骤表示游戏中的10秒。
现在,模拟就会开始运行,你可以在浏览器中看到智能体在地图上移动。
一旦运行完成,「Enter option」提示会再次出现。此时,你可以通过重新输入run命令并指定所需的游戏步数来继续模拟,或者输入exit退出但不保存,输入fin则是保存并退出。
下次运行模拟服务器时,只要提供模拟的名称就可以访问已保存的模拟。这样,你就可以从上次离开的位置重新启动模拟。
Step4. 重放模拟
只需运行环境服务器,并在浏览器中访问到以下地址,即可重放已运行的模拟:https://localhost:8000/replay/<simulation-name>/<starting-time-step>。
其中,需要将<simulation-name>替换为重放的模拟的名称,将<starting-time-step>替换开始重放的整数时间步。
Step5. 演示模拟
你可能会发现,重放中所有角色的Sprite看起来都是一样的。这是因为重放功能主要用于调试,并不优先考虑优化模拟文件夹的大小或视觉效果。
要正确演示带有角色Sprite的模拟,首先需要压缩模拟。为此,请使用文本编辑器打开位于reverie目录中的compress_sim_storage.py文件。然后,执行压缩函数,并将目标模拟的名称作为输入。这样,模拟文件就会被压缩,从而可以进行演示。
启动演示,请在浏览器中打开以下地址:https://localhost:8000/demo/<simulation-name>/<starting-time-step>/<simulation-speed>。
注意,<simulation-name>和<starting-time-step>与上述提到的含义相同。<simulation-speed>可用于控制演示速度,其中1表示最慢,5表示最快。
定制模拟
你有两种可选方式来自定义模拟。
方法1:编写并加载智能体历史
第一种是在模拟开始时初始化具有独特历史记录的智能体。
为此,你需要执行以下操作:1)使用其中一个基本模拟开始,2)编写和加载智能体历史记录。
步骤1. 启动基本模拟
存储库中包含两个基本模拟:base_the_ville_n25(25个智能体)和base_the_ville_isabella_maria_klaus(3个智能体)。可以按照上述步骤加载其中一个基本模拟。
步骤2. 加载历史文件
然后,在提示输入「Enter option」时,需要使用以下命令加载智能体历史记录:
call--loadhistorythe_ville/<history_file_name>.csv
其中,需要将<history_file_name>替换为现有历史文件的名称。
存储库中包含两个示例历史文件:agent_history_init_n25.csv(针对base_the_ville_n25)和agent_history_init_n3.csv(针对base_the_ville_isabella_maria_klaus)。这些文件包含了每个智能体的内存记录列表。
步骤3. 进一步的定制
要通过编写自己的历史文件来定制初始化,请将文件放在以下文件夹中:environment/frontend_server/static_dirs/assets/the_ville。
自定义的历史文件的列格式必须与附带的示例历史文件一致。因此,作者建议通过复制和粘贴存储库中已有的文件来开始该过程。
方法2:创建新的基本模拟
如果想要更深度地定制,就需要编写自己的基本模拟文件。
最直接的方法是复制和粘贴现有的基本模拟文件夹,然后根据自己的要求进行重命名和编辑。
AirPods 4新增主动降噪版本:售价1399元 9月20日正式发售
在9月10日凌晨的苹果秋季新品发布会上,苹果公司推出了备受期待的全新一代蓝牙耳机——AirPods4。这款耳机以其半入耳式设计,提供了更舒适的佩戴体验,并且特别增加了主动降噪功能,以满足不同用户的需求。AirPods4的发布,标志着苹果在无线耳机领域的进一步创新。标准版AirPods4的售价为999元,而配备主动降噪功能的版本售价为1399元,两款产品都将于9月20日正式发售。站长网2024-09-11 15:25:000000ChatGPT每天烧掉500万元!OpenAI被曝已在破产边缘
提到生成式人工智能的突然流行,ChatGPT与其背后的OpenAI是无法绕过的两个名字。但目前有消息指出,OpenAI很可能已经在一步步走向破产,而原因正是让其名声大噪的ChatGPT。快科技8月13日消息,根据AnalyticsIndiaMagazine近日发布的一篇报告,ChatGPT服务每天就要消耗70万美元(约合人民币506万元)左右的成本。站长网2023-08-13 17:40:180001小米Civi 4 Pro即将发布 首发骁龙8s Gen 3
今日,小米Civi产品经理胡馨心在微博上的一则发文,通过微博小尾巴的形式,正式确认了新机型小米Civi4Pro的命名。这款新机型的亮相,标志着小米Civi系列首次采用了后缀为“Pro”的命名方式,预示着它在性能、影像、屏幕以及快充等方面将向旗舰机型看齐。站长网2024-03-18 16:43:590000SambaNova发布全新AI芯片SN40L 可运行5万亿参数模型
文章概要:-SambaNova发布了一款智能AI芯片SN40L,可运行高达5万亿参数的模型,实现快速可扩展的推理和训练,而不损害模型准确性。-这款由TSMC制造的SN40L芯片可以在单个系统节点上为5万亿参数模型提供256k的序列长度,这是通过整合技术的新突破,大大提高了模型质量、推理速度,并降低了总拥有成本。站长网2023-09-26 16:28:510000











