谷歌DeepMind推出RT-2 使机器人更智能
谷歌的DeepMind宣布了机器人变换器2(RT-2),这是一种首创的视觉-语言-行为(VLA)模型,可以使机器人在没有特定训练的情况下执行新的任务。

就像语言模型如何从网络规模的数据中学习一般的想法和概念一样,RT-2使用网络上的文本和图像来理解不同的现实世界概念,并将这些知识转化为机器人行为的通用指令。
当这项技术得到改进时,它可以导致具有上下文感知、适应性强的机器人,它们可以根据不同的情况和环境执行不同的任务——而且所需的训练比目前要少得多。
早在2022年,DeepMind就推出了RT-1,这是一个多任务模型,它在13万个演示上进行了训练,并使日常机器人能够以97%的成功率执行700多个任务。现在,使用RT-1的机器人演示数据和网络数据集,该公司已经训练了该模型的后继者:RT-2。
RT-2最大的亮点是,与RT-1和其他模型不同,它不需要数十万个数据点来让机器人工作。组织长期以来发现特定的机器人训练(涵盖每一个对象、环境和情况)对于在高度可变的环境中处理复杂、抽象的任务至关重要。
然而,在这种情况下,RT-2从少量的机器人数据中学习,以执行基础模型中看到的复杂推理,并将所获得的知识转移用于指导机器人行为——即使是它从未见过或被训练过的任务。
“RT-2显示出了改善的泛化能力和超越它所接触到的机器人数据的语义和视觉理解,”谷歌解释说。“这包括解释新的命令并通过执行初级推理来响应用户命令,比如关于对象类别或高级描述的推理。”
谷歌DeepMind的机器人负责人文森特·范霍克(Vincent Vanhoucke)举例说,以前训练一个机器人扔掉垃圾意味着明确地训练机器人识别垃圾,以及捡起垃圾并扔掉它。
但是对于RT-2来说,由于它是在网络数据上进行训练的,所以不需要这样做。该模型已经有了什么是垃圾的一般概念,并且可以在没有明确训练的情况下识别它。它甚至有了如何扔掉垃圾的想法,尽管它从未被训练过采取这样的行动。
当处理内部测试中看到的任务时,RT-2表现得和RT-1一样好。然而,对于新颖、看不见的场景,它的表现几乎提高了一倍,从RT-1的32%提高到62%。
当进步时,像RT-2这样的视觉-语言-行为模型可以导致具有上下文感知能力的机器人,它们可以根据手头的情况在现实世界中执行各种各样的行为,并进行推理、解决问题和解释信息。
例如,企业可以看到的不是在仓库中执行相同重复动作的机器人,而是可以根据对象的类型、重量、易碎性和其他因素以不同的方式处理每个对象的机器人。
根据Markets and Markets的数据,AI驱动的机器人领域预计将从2021年的69亿美元增长到2026年的353亿美元,预期的复合年增长率为38.6%。
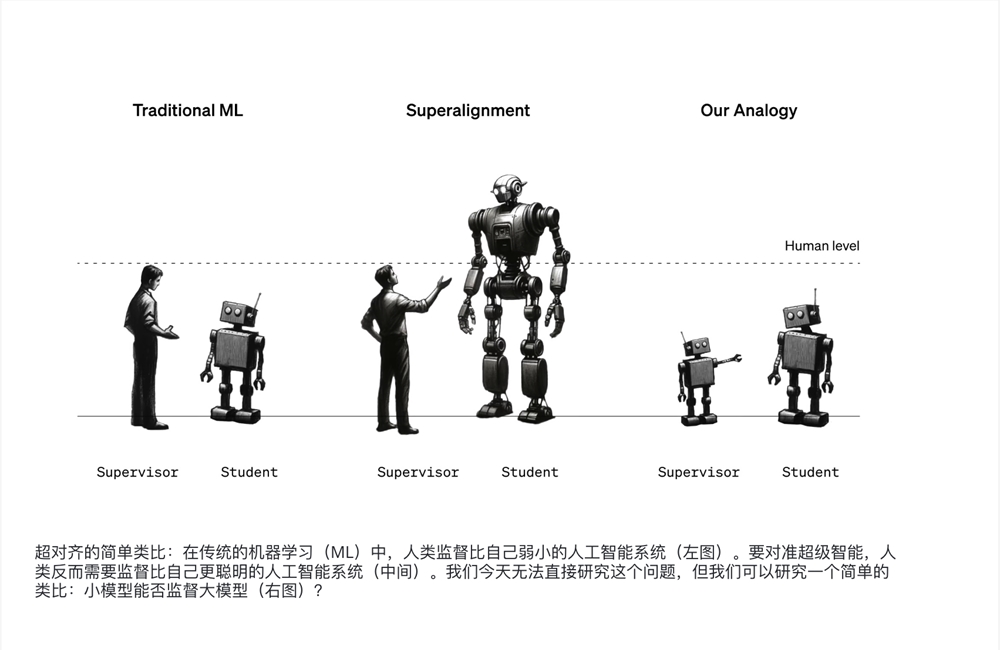
OpenAI 演示超级智能 AI 的控制方法:研究人员要求 GPT-2 指挥更强大的 GPT-4
OpenAI,一个承诺为全人类利益构建人工智能的公司,自去年推出ChatGPT以来,其商业雄心在最近的治理危机中变得更加显著。现在,该公司宣布,一个专注于管理未来超级智能AI的新研究小组开始取得成果。站长网2023-12-15 09:34:100000上线24小时吸金2000万后被下架,狂飙中的短剧被按暂停键?
那部网传24小时吸金2000万的付费短剧《黑莲花上位手册》,被下架了。11月16日上线,两天后冲上微博热搜出圈、引发广泛讨论,随后被全网下架,短短三四天时间,《黑莲花上位手册》引爆了整个短剧行业。这部剧由短剧团队“听花岛”出品,在小程序和抖音上播放,凭借一路高开高走的庶女复仇剧情,节奏快、反转多,戳到了一众网友的爽点,被称为是《甄嬛传》和《延禧攻略》的合体。站长网2023-11-22 12:01:370000OpenAI:Android 版 ChatGPT 应用现已在所有支持 ChatGPT 的国家和地区推出
OpenAI今天宣布,Android版ChatGPT应用程序现已在所有支持ChatGPT的国家和地区推出。OpenAI官方表示,我们很自豪能够为许多国家和地区提供ChatGPT的访问权限,而且我们也在不断增加支持的地点。站长网2023-08-01 09:18:180005英伟达推文生图模型 ConsiStory:免训练、可生成连贯图片
划重点:⭐️英伟达和特拉维夫大学研究人员共同开发了一种免训练、可生成连贯图片的文生图模型ConsiStory。⭐️ConsiStory通过主体驱动自注意力(SDSA)和特征注入等核心模块,在不需要任何训练或调优的情况下实现图像主体的一致性。⭐️该模型还包含锚图像和可重用主体功能,提供主题一致性的参考,避免了传统训练方法中针对每个主题进行训练的难题。站长网2024-02-21 09:11:3100012000大衣只赔60,网上送洗到底靠不靠谱
不靠谱的洗衣平台,正在背刺一线年轻人当你有一件羽绒服需要干洗时,你会花50块钱选择小区门口那家开了五年的小店,还是拿出手机支付25块钱等待某线上洗衣平台上门取件?不同的消费者或许会给出不同的答案。天气转凉,又到了一年一度整理衣柜的季节。洗衣行业也迎来旺季,线上团购平台屡推特价套餐搞促销,线下洗衣店仓库爆满。站长网2023-10-25 20:16:370000