让视觉模型具备语言理解能力:通过跨模型对齐实现文本到概念的转换
如果你只需要训练一个线性层,就能拿将纯视觉模型转变为具备语言理解能力的视觉语言模型 (VLM),结果会怎样?有研究人员想到了这个办法。
研究人员通过使用没有文本监督训练的现成视觉编码器来将文本映射到概念向量,以便直接比较单词和图像的表示。他们的方法调整了视觉模型的表示空间,使其与 CLIP 模型的表示空间相一致。CLIP 模型是同时训练图像和文本编码器的,因此它已经包含了用于文本到概念的文本编码器。

该方法通过学习表示空间之间的映射来使用商用模型的这种能力。具体来说,研究人员最大化一个函数,以推断出图像在 CLIP 模型中的表示,该模型使用了预训练模型的表示,并将其映射到 CLIP 模型的表示。经过映射后,对应的特征将存在于与目标文本的概念向量相同的空间中。然而,映射函数可能会严重改变输入的语义。为了避免这种情况,他们确保映射的假设空间中只存在仿射变换。尽管它们看起来不太复杂,但研究人员发现线性层意外地对于在架构和训练方法不同的模型之间实现特征空间对齐非常有用。

项目地址:https://github.com/k1rezaei/Text-to-concept/
该方法在文本到概念的零样本分类方面提供了强大的支持。与 CLIP 模型相比,这些商用模型在许多任务上展示出惊人的零样本准确性,尽管它们的规模更小,使用的样本更少,并且没有显式地针对文本到概念进行调整。令人惊讶的是,在某些情况下,尤其是在颜色识别方面,商用模型的零样本准确性甚至超过了 CLIP 模型。
文本到概念的可解释性好处不仅仅在于免费的零样本学习,还包括将视觉编码器转换为概念瓶颈模型 (CBM) 而无需概念监督的需求。研究人员将这种方法应用于 RIVAL10数据集,该数据集包含属性标签,以确保零样本概念预测的准确性。借助所提出的零样本方法,他们能够高度准确地预测 RIVAL10的属性 (93.8%),从而实现了预期的可解释性好处。
他们的研究还证明了文本到概念可以用人类术语解释大型数据集的分布,通过分析一系列文本到概念向量与数据的对齐表示之间的相似性。通过比较对易理解的概念的变化,可以诊断出分布的变化。基于概念的图片检索是文本到概念的另一种方法,它可以方便地与大型数据集进行交互。研究人员使用概念逻辑来查询给定模型的图像表示,满足一组概念相似性阈值,从而使人们更加掌握搜索中每个概念的相对权重,并在庞大的语料库中定位特定照片时获得可接受的结果。
最后,研究人员引入了概念到文本的方法,直接解码模型表示空间中的向量,完成人机交流的循环。他们使用现有的 CLIP 空间解码器和嵌入来指导 GPT-2的输出,在将模型的空间与 CLIP 对齐后进行解码。然后,他们使用人类研究来检查解码的标题是否准确解释了与每个向量相关联的类别。结果表明,他们的简单方法在92% 的测试中都取得了成功。
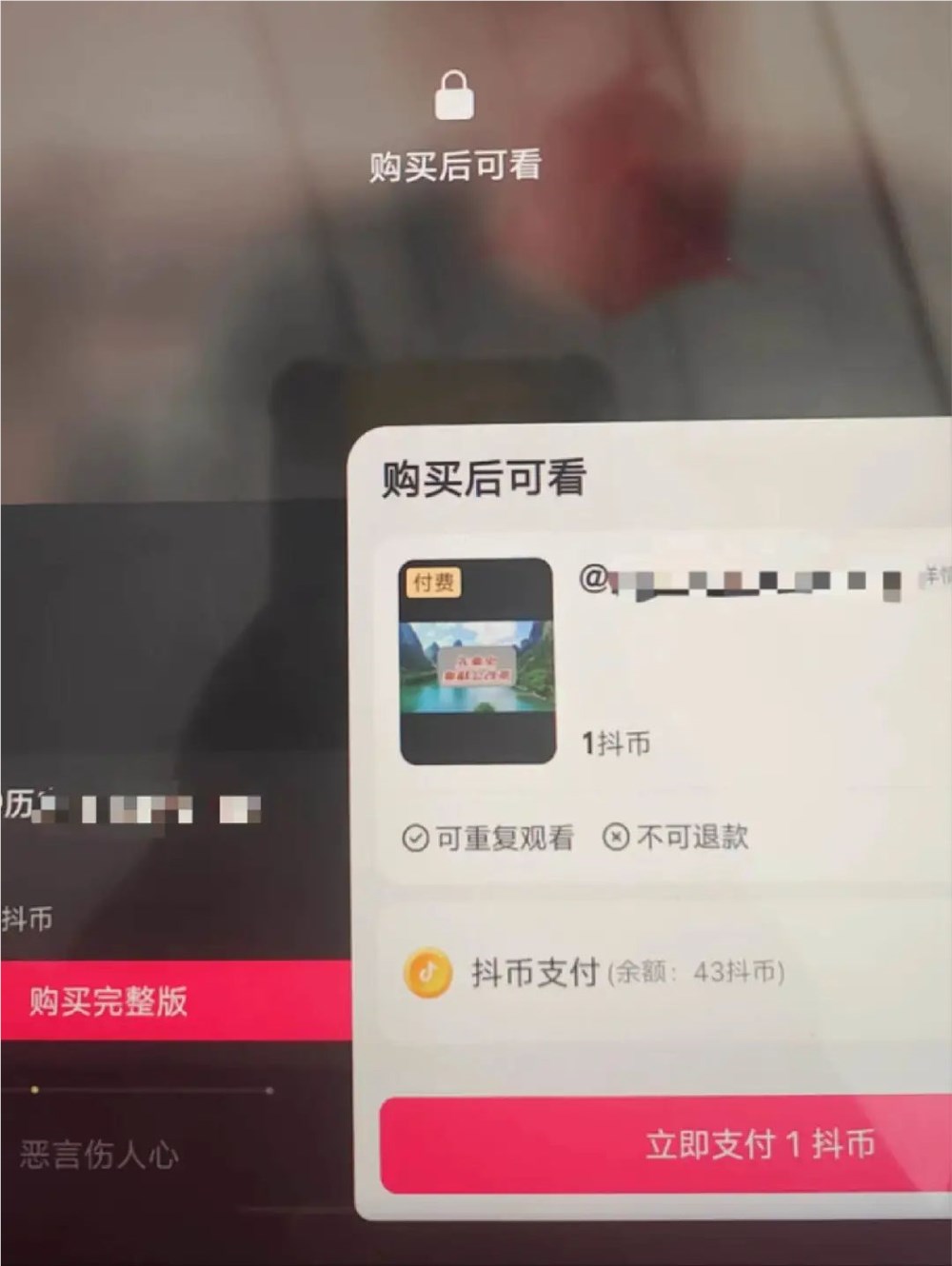
独家|抖音测试视频内容付费,花钱刷短视频将成趋势?
Tech星球独家获悉,抖音于近期测试视频内容付费服务,即用户在平台观看部分视频内容时,需要付费才能解锁全部的内容。图注:Tech星球拍摄的抖音视频内容,可以设置付费。对此,Tech星球向抖音方面进行求证,截至发稿,抖音方面暂无回应。站长网2023-11-16 09:12:570000Together AI 推出 Llama-2-7B-32K-Instruct:扩展上下文语言处理能力
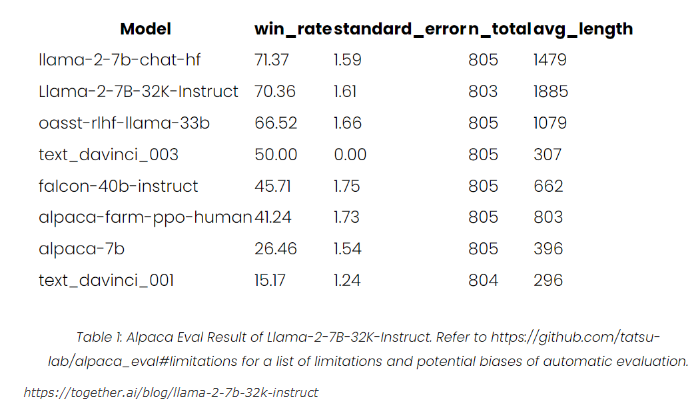
TogetherAI发布了Llama-2-7B-32K-Instruct:一项在语言处理中扩展上下文的突破。这项创新具有重大意义,特别是在需要对复杂上下文细微差别有深刻理解的任务中。该模型通过巧妙地利用TogetherInferenceAPI的能力,成功地处理了长篇指令,同时在短篇情境下表现出色。站长网2023-08-22 11:53:110000LangSplat:一种基于3D高斯技术提高3D语言查询交互任务效率
划重点:1.LangSplat是一种基于传统3D高斯技术的人工智能方法,用于在3D环境中进行开放式语言查询,以解决当前方法在处理速度和准确性方面的限制。2.该方法使用了独特的3D语言领域构建和语言嵌入技术,通过场景级语言自动编码器减少内存使用,并通过SegmentAnythingModel(SAM)解决复杂场景中的点模糊问题。站长网2024-01-18 11:25:450000格莱美CEO:AI作为工具很酷,但不能取代人类创造力
RecordingAcademy发布了新的格莱美奖指南,规定只有“人类创作者”才有资格获得这个音乐界最高荣誉。虽然AI创作的音乐仍然可以参选和提名,但是学院不会授予AI部分格莱美奖。这一举措旨在承认AI在增强、修饰或补充人类创造力方面的作用,但不是取代它。该指南是在与版权办公室等机构进行广泛研究和讨论后制定的。站长网2023-07-08 17:00:560001风险投资创始人:人工智能泡沫将会「破裂」,但技术将继续存在
人工智能泡沫即将破裂吗?风险投资公司SineWaveVentures的创始人YanevSuissa日前在接受SeekingAlpha采访时表示,这可能会在明年发生。但他补充说,这并不意味着这项技术没有价值。Suissa说:「人工智能是科技的下一个革命,但它也一直存在。这是那种会破裂的东西,而且它会是一个巨大的破裂,然后它会自我调整。」站长网2023-10-16 11:50:130000