麻省理工学院研究人员在机器学习模型隐私保护方面取得突破
站长网2023-07-21 12:09:286阅
麻省理工学院的研究人员通过引入一种新的隐私度量标准和一个确定所需噪音最小量的框架,取得了保护机器学习模型中敏感数据的突破。
传统的隐私保护方法往往通过添加大量噪音来防止对特定数据的识别,但这会降低模型的准确性。而新的隐私度量标准 “Probably Approximately Correct (PAC) Privacy” 则从不同的角度考虑,评估了对手在添加噪音后重构敏感数据的难度。

为了实现 PAC 隐私,研究人员开发了一个算法,根据对手的观点计算原始数据的不确定性或熵,并通过对多次运行机器学习训练算法的子采样数据进行比较,确定所需噪音的最佳量。
该算法不需要了解模型的内部工作机制或训练过程,并且可以根据用户对对手重构敏感数据能力的要求提供最佳噪音量。然而,该算法并不估计添加噪音对模型准确性的损失,而且由于需要反复在多个子采样数据集上训练机器学习模型,实现 PAC 隐私可能会导致计算成本较高。为了提高 PAC 隐私的效果,研究人员建议修改机器学习训练过程以增加稳定性,从而减少子采样输出之间的方差。这种方法可以降低算法的计算负担,并减少所需噪音的量。
此外,更稳定的模型通常表现出更低的泛化误差,从而可以在新数据上进行更准确的预测。通过利用 PAC 隐私,工程师可以开发出在保护训练数据的同时保持准确性的模型,从而在实际应用中实现安全的数据共享。
0006
评论列表
共(0)条相关推荐
快手内测搜索智能问答产品
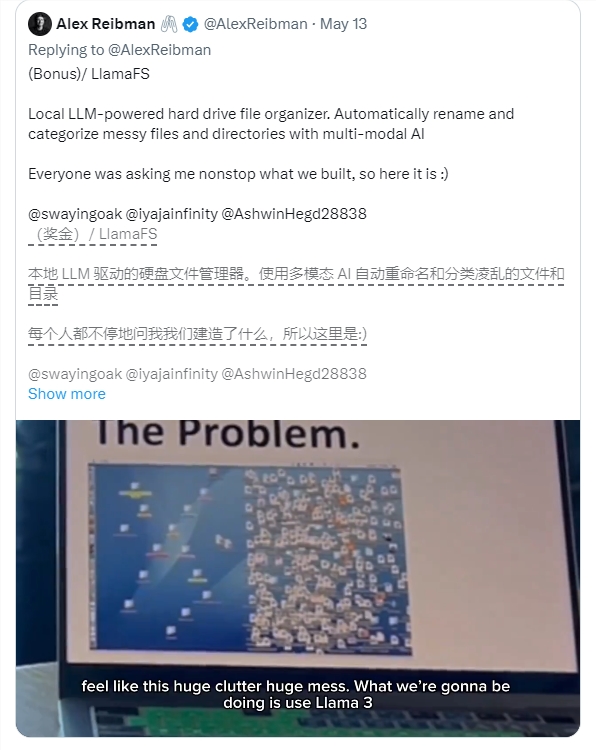
快手近日正在进行内测智能问答产品,为用户带来智能问答和文本创作等新功能。用户在快手搜索中输入问题后,可以获得来自智能问答产品提供的信息和答案。这一功能在原有搜索结果基础上提供了更加直接有效的信息补充。据了解,这是短视频直播行业首个基于大语言模型的应用产品。0003你乱糟糟的桌面有救了!LlamaFS:基于Llama 3的自动整理小助手
LlamaFS是一个基于Llama3的自动文件整理系统,旨在帮助用户自动重命名和组织电脑中的文件。功能特点:自动整理文件:LlamaFS能够根据文件内容和时间等信息,自动对文件进行重命名和分类整理。支持多种文件类型:系统不仅支持普通文件的整理,还能够处理图片和音频文件。隐私保护:提供“隐身模式”,确保用户的文件安全,不会被泄露。站长网2024-05-27 19:35:510000微软 Viva 结合基于人工智能的「技能」功能来增强员工分析
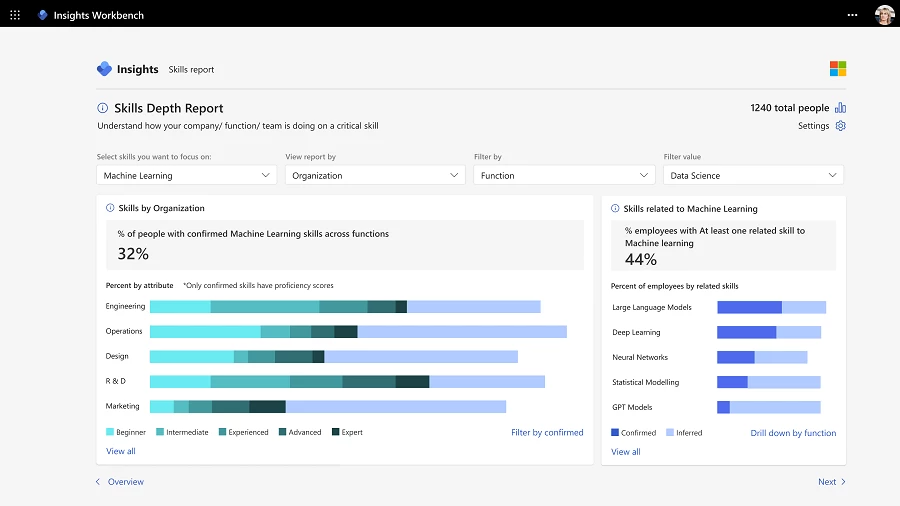
微软正在为其MicrosoftViva员工体验平台注入一项新的人工智能功能。该公司宣布新增「Skills(技能)」功能,这是一项以人工智能为重点的功能,旨在为雇主提供有关其员工能力的全面见解,从而发现并弥补可能存在的技能差距。图片来自Microsoft站长网2023-10-12 14:53:420001亚马逊利用生成式人工智能Project PI扫描包裹缺陷
划重点:⭐亚马逊利用生成式人工智能和计算机视觉技术扫描包裹,以减少退货率⭐项目P.I.(私家侦探)AI模型能够识别损坏产品和错误发货情况⭐AI技术有助于提高包裹质量,减少退货,改善可持续性站长网2024-06-03 20:16:340000交个朋友,逃不过“三年之痒”
近日,交个朋友公司迎来开播三周年的纪念日。4月1日,罗永浩带领交个朋友的主播天团在抖音“交个朋友直播间”为网友们举办许愿大会,多名网友的愿望得到实现。截至4月3日凌晨2点,抖音“交个朋友直播间”三周年庆典累计销售额超过2.1亿元,累计观看人数超1200万。由于踩中了直播电商的时代风口,交个朋友得以在三年时间内迅速扩张。站长网2023-04-13 09:24:060000