麻省理工研究员在机器学习模型隐私保护方面取得突破
最近,麻省理工学院的研究人员在保护机器学习模型中的敏感数据方面取得了重大突破。研究团队开发了一种机器学习模型,可以根据肺部扫描图片准确预测患者是否患有肺癌,但是与全球医院分享该模型可能会面临恶意代理人进行数据提取的风险。为了解决这个问题,研究人员引入了一种新的隐私度量标准,称为 “Probably Approximately Correct(PAC)Privacy”,以及一个确定保护敏感数据所需的最小噪音量的框架。
传统的隐私方法,如差异隐私,主要通过添加大量噪音来防止对手区分特定数据的使用,这会降低模型的准确性。PAC 隐私从不同的角度评估对手在添加噪音后重构敏感数据的困难程度。例如,如果敏感数据是人脸,差分隐私将防止对手确定数据集中是否存在特定个体的脸部。相反,PAC 隐私探讨的是对手是否能够提取出可以识别为特定个体脸部的近似轮廓。

为了实现 PAC 隐私,研究人员开发了一种算法,确定向模型中添加的最佳噪音量,以确保即使在对手具有无限计算能力的情况下也能保持隐私。该算法依赖于对手从原始数据的不确定性或熵的角度。通过对数据进行子抽样并多次运行机器学习训练算法,该算法比较不同输出之间的方差,以确定所需的噪音量。方差越小,表示所需的噪音越少。
PAC 隐私算法的一个关键优势是不需要了解模型的内部工作原理或训练过程。用户可以指定对手在重构敏感数据方面的置信水平,并且算法提供实现该目标所需的最佳噪音量。然而,值得注意的是,该算法不会估计由于向模型添加噪声而导致的准确性损失。此外,由于在各种子采样数据集上重复训练机器学习模型,实施 PAC Privacy 的计算成本可能会很高。
为了增强 PAC 隐私,研究人员建议修改机器学习训练过程以提高稳定性,从而减少子样本输出之间的方差。这种方法将减少算法的计算负担并最大限度地减少所需的噪声量。此外,更稳定的模型通常表现出更低的泛化误差,从而对新数据进行更准确的预测。
虽然研究人员承认需要进一步探索稳定性、隐私和泛化误差之间的关系,但他们的工作在保护机器学习模型中的敏感数据方面迈出了一大步。通过利用 PAC 隐私,工程师们可以开发出在保护训练数据的同时保持准确性的模型,适用于实际应用。借助减少所需噪音量的潜力,这种技术为医疗领域和其他领域中的安全数据共享开辟了新的可能性。
原论文地址:https://arxiv.org/abs/2210.03458
100万份!网易云音乐教师节发福利:老师免费领黑胶VIP270天会员等
快科技9月5日消息,9月10日是我国第40个教师节,今日,网易云音乐宣布发放100万份教师节大礼包。大礼包权益如下:网易云音乐黑胶VIP270天卡、网易云音乐云贴贴红包90天黑胶VIP、网易云音乐有声书畅听270天会员,以及网易严选Pro会员有道云笔记高级会员网易邮箱会员樊登讲书VIP。站长网2024-09-06 16:25:470000DreamGift:你的AI个性化购物助手 帮你轻松找到完美礼物
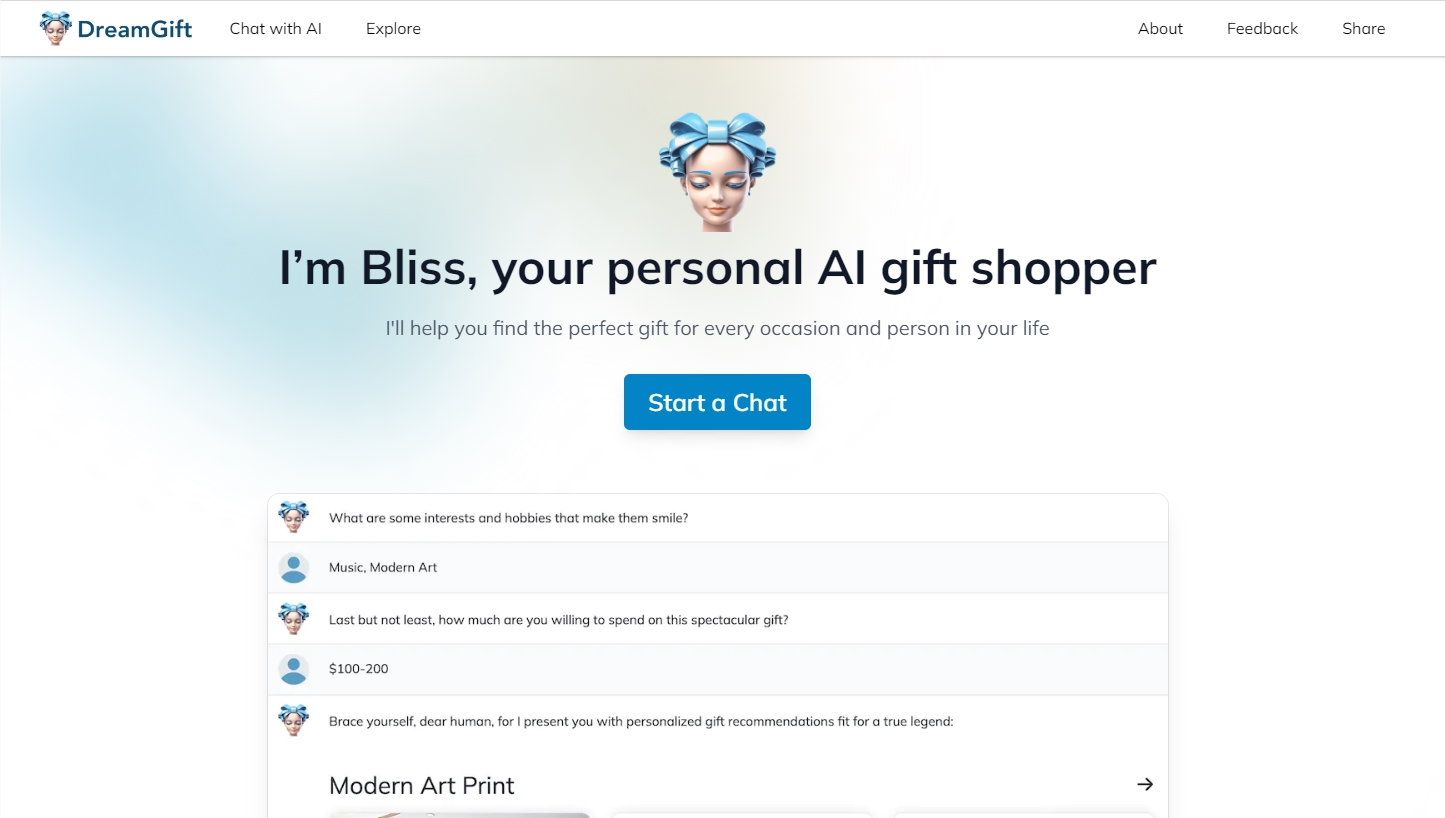
DreamGift是一个帮助用户挑选完美礼物的在线服务。它利用人工智能技术,根据用户提供的礼物接收者信息、具体场合以及预算,为用户提供个性化的礼物建议。体验地址:https://dreamgift.ai/站长网2023-09-14 12:40:550000深势科技推出多模态科学文献大模型Uni-Finder
深势科技推出了Uni-Finder,一个革命性的智能文献数据库平台,通过多模态检索功能和自然语言交互技术,提高科学文献的阅读和分析效率。Uni-Finder基于科学多模态大模Uni-SMT,综合考虑文献中的多模态元素,如图表、数学方程、分子结构等。站长网2023-11-15 19:21:000005半年涨粉1W、销售额28W,小众赛道为什么在小红书更吃香?
很多人以为只有做受欢迎的热门赛道内容,才能在小红书吸到粉、赚到钱。事实上,现在小红书发展越来越成熟了,细分出了很多更垂、更专的赛道,兴趣和爱好也能让用户喜欢、关注、下单。比如我们秋叶小红书训练营一位叫“明星花园”的学员,裸辞后发展自己的爱好,逐步成为了一名拥有1000平方花园的园艺博主。别看园艺类是小众赛道,他只用半年时间,涨粉1W,带来的销售额累计超过28W。他到底是怎么做到的?站长网2024-05-27 19:38:230001月之暗面:Kimi 大模型API 已支持 Tool Calling 功能
月之暗面(MoonshotAI)宣布Kimi大模型学会了使用工具,即API已支持ToolCalling功能。通过这个功能,开发者可以让Kimi大模型与各种自定义外部工具进行交互,从而拓展AI应用的想象空间。举例来说,Kimi大模型可以在对话中调用地图工具展示公司地址、调用PPT制作工具制作演示文稿,或者调用数学计算工具解答复杂问题。站长网2024-04-24 18:09:580002