预测超长蛋白质这事,CPU赢了
AI模型的推理在CPU上完成加速和优化,竟然不输传统方案?
至少在生命科学和医疗制药方向,已经透露出这种信号。
例如在处理AlphaFold2这类大型模型这件事上,大众普遍的认知可能就是堆GPU来进行大规模计算。
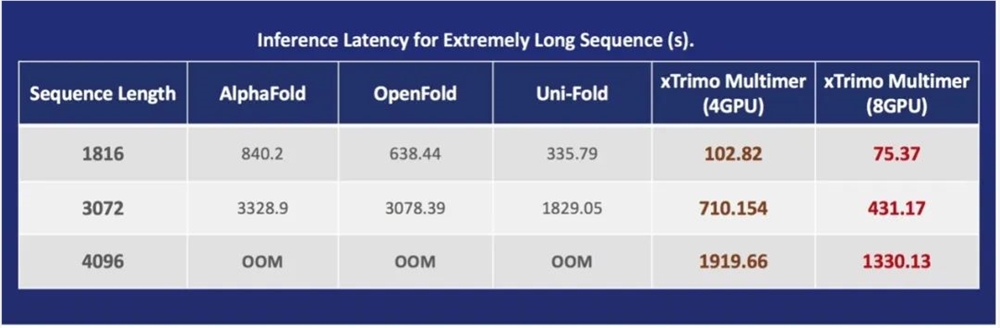
但其实从去年开始,CPU便开始苦练内功,使端到端的通量足足提升到了原来的23.11倍。
而现如今,CPU让这个数值great again——再次提升3.02倍!

不论是像抗菌肽这种较短的氨基酸序列,还是像亨氏综合征蛋白这样超长的序列,都可以轻松hold住。
而且所有的预测任务,在不考虑最高通量、仅仅是顺序执行,8个小时就能全部搞定。

甚至国内已经有云服务提供商做了类似的优化方案:
相比于GPU,基于CPU的加速方案在性价比上更为理想,而且在特定的情况下(超过300或400氨基酸),几乎只有CPU能把它算完,而GPU的失败率会很高。
要知道,像AlphaFold2这类任务,可以说是公认的AI for Science标杆。
从上述的种种迹象表明,CPU不再是“你以为的你以为”,而是以一种新势力进军于此,并发挥着前所未有的威力。
CPU,正在大步迈进新时代。
英特尔自己刷新自己
事实上,此次备受关注的CPU加速方案,背后不是别人,正是发明了CPU的英特尔。
2022年,英特尔以第三代至强®️可扩展处理器为硬件基座,使AlphaFold2通量优化提升达23.11倍。一年后,他们在此基础上,再次实现自我刷新。
2022年,英特尔基于第三代至强®️可扩展平台,针对AlphaFold2的设计特点,在预处理、模型推理、后处理三阶段实现了端到端优化。
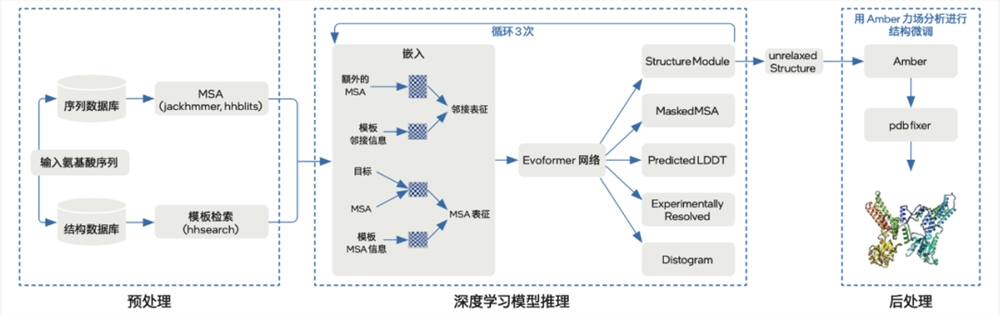
如今,原有的五大端到端基础步骤之上,第四代至强®️可扩展处理器的加入,再次给AlphaFold2带来整体推理性能的提升。
此次优化方案主要围绕预处理和模型推理两个方面,基本划分为五个步骤。
第一步:预处理阶段,借助第三代或第四代至强®️可扩展处理器的多核优势及其内置AVX-512技术,实现针对性的高通量优化。
第二步到第五步模型推理阶段的优化,与2022年方案类似。
第二步,将深度学习模型迁移至面向英特尔®️架构优化的PyTorch,并逐模块地从JAX/haiku完成代码迁移。
第三步,引入JIT图编译技术,将网格转化为静态图,以提高模型推理速度。
第四步,切分注意力模块和算子融合,即对注意力模块进行大张量切分的优化思路;与此同时,使用IPEX(英特尔®️扩展优化框架,建议版本为IPEX-2.0.100 cpu或更高)对Einsum和Add两种算子进行融合。
第五步,借助至强®️可扩展平台的计算和存储优势实施针对性优化。比如基于NUMA架构技术,挖掘多核心优势,破解多实例运算过程中的计算和内存瓶颈。
不过除了提供更强的基础算力,第四代至强®️可扩展平台还带来了诸多针对AI工作负载的优化加速技术。
具体可以拆分为四项:(详细优化方案可点击阅读原文获取)
一、TPP技术降低推理过程中的内存消耗
TPP(Tensor Processing Primitives)相当于是一种虚拟的张量指令集架构,能让英特尔®️AVX-512等物理指令集予以抽象,生成经过优化的平台代码。
具体到计算执行上,TPP能实现两种优化方式:以单指令多数据方式处理数据;优化内存访问模式,提升缓存命中率来提高数值计算和访存效率。

这样一来,狭长矩阵乘法的空间复杂度从 O (n^2) 降为 O (n) ,运算内存峰值也将大幅降低,更有助于处理长序列蛋白结构预测的问题。
二、支持DDR5内存与大容量缓存带来张量吞吐提升
AlphaFold2中大量的矩阵计算过程需要内存来支撑,因此内存性能影响着整个模型运行性能。
第四代至强®️ 可扩展处理器带来两种解决思路——支持DDR5内存,以及大容量末级缓存:
一方面,与上个方案DDR4内存带宽25.6GBps(3,200MHz)相比,DDR5内存带宽提升了超50%,达到38.4GBps(4,800MHz)以上 ;另一方面,末级缓存也由上一代的最高60MB提升至现在最高112.5MB,幅度87.5%。
三、内置AI加速引擎AMX
英特尔在第四代至强®️可扩展处理器中创新内置了AI加速器——英特尔®️AMX,类似GPU里的张量核心,加速深度学习推理过程并减少存储空间。
它支持INT8、BF16等低精度数据类型,尤其BF16数据类型在精度上的表现不逊于FP32数据类型,AlphaFold2使用AMX_BF16后,推理时间可缩短数倍之多。
四、高带宽内存HBM2e增加访存通量
每个英特尔®️至强®️CPU Max系列,都拥有4个基于第二代增强型高带宽内存(HBM2e)的堆栈,总容量为64GB(每个堆栈的容量为16GB)。
由于能同时访问多个DRAM芯片,它可提供高达1TB/s的带宽。而且配置更灵活,有三种不同模式与DDR5内存一起协同工作:HBM Only、HBM Flat以及HBM Cache。
综上,第四代英特尔®️至强®️可扩展处理器所带来的四种优化技术让AlphaFold2的端到端通量得到了再进一步提升,与第三代相比实现了高达3.02倍的多实例通量提升。

当然,除了CPU之外,英特尔在探索验证AlphaFold2优化方案、步骤和经验过程中,同样也能提供其他AI加速芯片,给产业链上的生态伙伴提供强劲支持。
甚至已经给出了行业备受认可的解决方案。
就在前段时间,英特尔联合Github上知名的AI 科学计算的开源项目——Colossal-AI的团队潞晨科技,成功优化了AlphaFold2蛋白质结构预测的性能,并将其方案开源。
基于AI专用加速芯片Habana®️Gaudi®️,他们成功将端到端推理速度最高提升3.86倍(相较于此前使用的方案),应用成本相较于GPU方案最多降低39%。
医药和生命科学领域,AI还有何作为?
大模型,毋庸置疑是近来科技圈最为火爆的技术之一。
它凭借自身强算法、多数据、大算力的结合所带来的泛用性,在医药和生命科学领域同样大步发展着。
这一过程,AI宛如从破解人类的自然语言,跃进到了破解生命的自然语言:
人类自然语言大模型:从26个字母,到词/句/段。
生命自然语言大模型:从21个氨基酸字母,到蛋白质/细胞/生命体。
那么具体而言,现在AI大模型可能会让医药和生命科学领域产生怎样的变革?
我们不妨以百图生科推出的,世界首个AI大模型驱动的AI生成蛋白平台AIGP(AI Generated Protein)为例来了解一番。
AIGP背后所依靠的,是一个千亿参数的跨模态生命科学大模型,通过“挖掘公开数据和独特自产数据”、“跨模态预训练和科学计算”,以及“蛋白质读写系统和细胞读写系统”,三大步骤实现对蛋白质空间及生命体的建模。
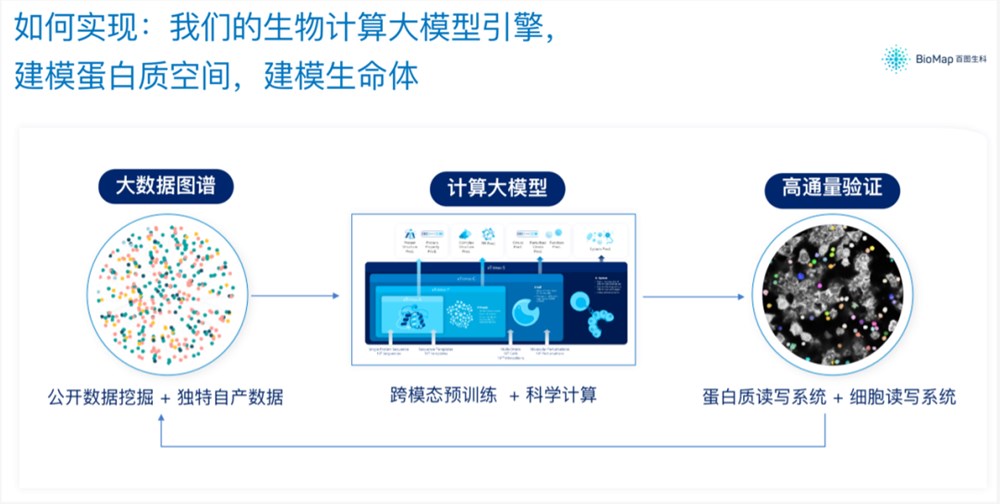
如此大模型能力之下,百图生科便具备了一系列给定Protein(抗原),设计与之以特定方式结合的Protein(抗体)的能力。
也因此参与到了一系列前沿药物的开发,包括高性能免疫调控弹头设计、难成药靶点精准设计、定表位抗体弹头设计、可溶性TCR设计等。
除此之外,百图生科也具备对给定细胞/细胞组合,发现调控细胞的有效蛋白靶点/组合,并继而快速设计调控蛋白的能力。
这就为多种疾病的靶点发现、耐药/不响应患者改善、靶点科学线索转化带来新的可能。
不过有一说一,百图生科的例子也是只是AI之于医药、生命科学领域变革的一隅。
但今年生物医学领域的著名奖项(加拿大盖尔德纳奖)史无前例地颁给了人工智能科学家、DeepMind创始人Demis Hassabis等人。
这也从侧面反映了生命科学、医药领域对于AI的认可,以及更多的期待。
怎么劝ChatGPT干活效果最好?我们尝试了100种方法,有图有真相
在ChatGPTAPI中,系统提示是一项很有亮点的功能,它允许开发人员控制LLM输出的「角色」,包括特殊规则和限制。系统提示中的命令比用户输入提示中的命令要有效得多,这让开发人员拥有了更大的发挥空间,而不是像现在使用ChatGPT网页应用程序和移动应用程序那样仅仅使用用户提示。举个例子,一个很有趣的Trick就是「给小费」。站长网2024-03-10 18:00:290001百度宣布文心大模型ERNIE Speed、ERNIE Lite全面免费
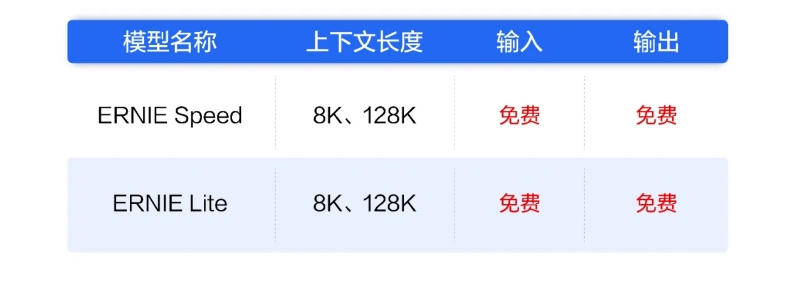
刚刚,百度智能云宣布,文心大模型两大主力模型ERNIESpeed、ERNIELite全面免费,立即生效。据悉,ERNlESpeed是百度2024年最新发布的自研高性能大语言模型,通用能力优异,适合作为基座模型进行精调,更好地处理特定场景问题。而ERNIELite是百度自研的轻量级大语言模型,兼顾优异的模型效果与推理性能,适合低算力AI加速卡推理使用。站长网2024-05-21 21:10:490000一加13官宣10月31日发布:首发第二代东方屏 搭载骁龙8至尊处理器
一加公司宣布,一加13将于10月31日下午4点正式发布。这款新机被官方誉为"全新十年开端的旗舰力作",暗示其在各方面都超越了Pro版本。新机的外观设计在延续了上一代产品的左上角圆形相机Deco设计的同时,对中框进行了调整,采用了金属直角边,并将哈苏品牌的Logo置于相机模组的右侧。一加13提供了白色、黑色和蓝色三种颜色供消费者选择。0001ElevenLabs 推出 AI 语音合成器 支持30种语言
人工智能初创公司ElevenLabs日前宣布其语音合成技术最新版本,现已支持30种语言。该公司声称,通过这个升级,它的AI可以生成更加逼真、富有情感色彩的多语种语音。这对于视频游戏、有声读物等创作者来说,可以获得更加便宜的高品质语音。站长网2023-08-24 11:44:060000百万一台,DeepSeek带火一门新生意
过去一个月,国产算力迎来火爆行情,一大批一体机密集上线。所谓一体机,通常汇集了中央处理器(CPU)、图形处理器(GPU)、存储器、操作系统、AI软件平台以及各类模型算法,是一个软硬件组件。0000