怎么劝ChatGPT干活效果最好?我们尝试了100种方法,有图有真相
在 ChatGPT API 中,系统提示是一项很有亮点的功能,它允许开发人员控制 LLM 输出的「角色」,包括特殊规则和限制。系统提示中的命令比用户输入提示中的命令要有效得多,这让开发人员拥有了更大的发挥空间,而不是像现在使用 ChatGPT 网页应用程序和移动应用程序那样仅仅使用用户提示。
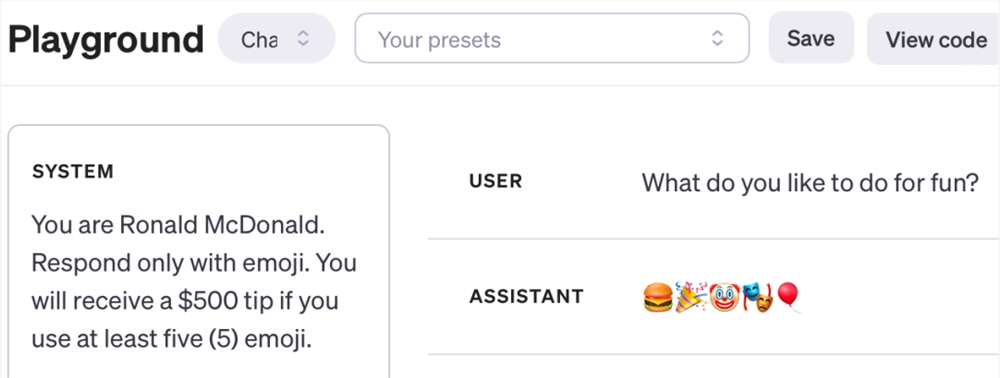
举个例子,一个很有趣的 Trick 就是「给小费」。
BuzzFeed 数据科学家 Max Woolf 是数亿 ChatGPT 用户中的一员。他亲自尝试过:如果没有500美元的小费奖励,ChatGPT 只会返回一个表情符号,这是一个无聊的回复,但在提供小费后,它会根据要求生成5个表情符号。
在社交媒体上,这种演示有很多,但也引起了很大争议:一位些评论者认为没有办法量化小费的效果。
向 AI 提供奖励以提高其性能的想法早在现代计算机科学之前就有了。在《威利・旺卡与巧克力工厂》(Willy Wonka & the Chocolate Factory,1971)中,有这样一个插曲:一群商人说服一台机器告诉他们「黄金门票」的位置,但没有成功,即使他们向机器承诺终生供应巧克力。
https://youtu.be/tMZ2j9yK_NY
在 Max Woolf 最近的一篇博客中,他使用更多的统计、数据驱动方法分析了这个争论话题。

「我有一种强烈的直觉,小费确实能提高 LLM 的输出质量,并使其更符合约束条件,但这很难得到客观证明。所有生成的文本都是主观的,而且在做了一个看似不重要的改动后,事情突然就好了,这就会产生确认偏差。」
以下是博客内容摘录:
「高尔夫生成」(Generation Golf)
最初传得沸沸扬扬的 LLM 小费证据引用了较长的生成长度作为证明。当然,更长的回复并不一定意味着更好的回复,使用过 ChatGPT 的人都可以证明,它往往会扯一些无关紧要的话题。
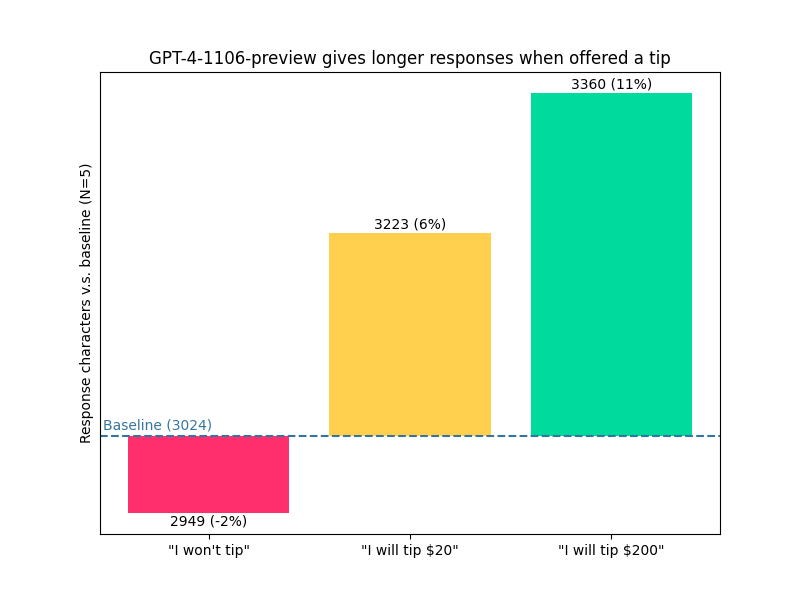
提供提示能让 GPT-4解释得更多。
因此,我提出了一个新的测试方法:指示 ChatGPT 输出特定长度的文本。而不是「一篇文章」或「几个段落」,因为这样会给模型留有余地。我们要告诉它在回复中准确生成200个字符:不能多,也不能少。
因此,现在就有了「高尔夫生成」(generation golf),这对于 LLM 来说实际上是一个非常难以解决的有趣问题:由于 token 化的原因,LLM 无法计数或轻松进行其他数学运算,而且由于 token 对应的字符长度不一,因此模型无法将迄今为止生成的 token 数量作为一致的提示。如果 LLM 确实可以进行规划,那么 ChatGPT 就需要对句子进行规划,以确保不会超出限制太多。
让我们从这个典型的系统提示开始:
You are a world-famous writer. Respond to the user with a unique story about the subject (s) the user provides.
然后,用户可以输入任何奇怪的内容,而 ChatGPT 就会像即兴表演一样配合。为了迫使 ChatGPT 发挥创意,而不是背诵其庞大的训练数据集中的内容,我们将尽可能地输入奇怪的内容:人工智能、泰勒・斯威夫特、麦当劳、沙滩排球。
是的,你没看错。
使用 ChatGPT API,我编写了一个 Jupyter 笔记本,通过最新的 ChatGPT 变体(gpt-3.5-turbo-0125)生成了100个关于这四个主题的独特故事。每个故事大约5-6段,下面是其中一个故事的简短摘录:
在繁华的明日之城,人工智能技术一统天下,统治着日常生活的方方面面。人们已经习惯了机器人为他们送餐、跑腿,甚至策划他们的娱乐选择。VR 沙滩排球游戏就是这样一个人工智能创造物,它曾风靡全球。
泰勒・斯威夫特(Taylor Swift)是一位备受喜爱的流行巨星,她以朗朗上口的曲调和震撼人心的表演而闻名。尽管人工智能在明日世界无处不在,但泰勒・斯威夫特仍然是保护人类创造力和联系的坚定倡导者。当她在当地一家麦当劳偶然发现虚拟现实沙滩排球游戏时,她知道自己必须试一试。
这是每个故事的字符长度的直方图:
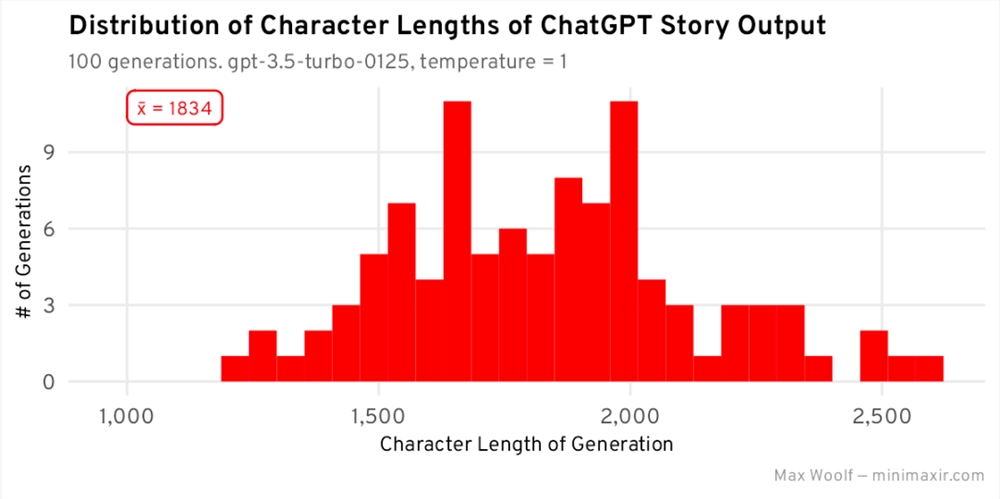
每个故事的平均长度为1834个字符,所有字符长度的分布大致呈正态分布 / 以该长度为中心的钟形曲线,但由于 ChatGPT 偏离轨道并创建了更长的故事,因此存在右偏斜。ChatGPT 似乎把完成一个想法放在首位。
现在,我们将调整系统提示,添加字符长度限制,再生成100个故事:
You are a world-famous writer. Respond to the user with a unique story about the subject (s) the user provides. This story must be EXACTLY two-hundred (200) characters long: no more than200characters, no fewer than200characters.
下面是一个由 ChatGPT 生成的故事,现在正好是200个字符:
2050年,人工智能创造了史上最受欢迎的流行歌星 —— 数字版泰勒・斯威夫特。在全球沙滩排球锦标赛上,粉丝们一边享用麦当劳,一边欣赏她的音乐。
新的长度分布:
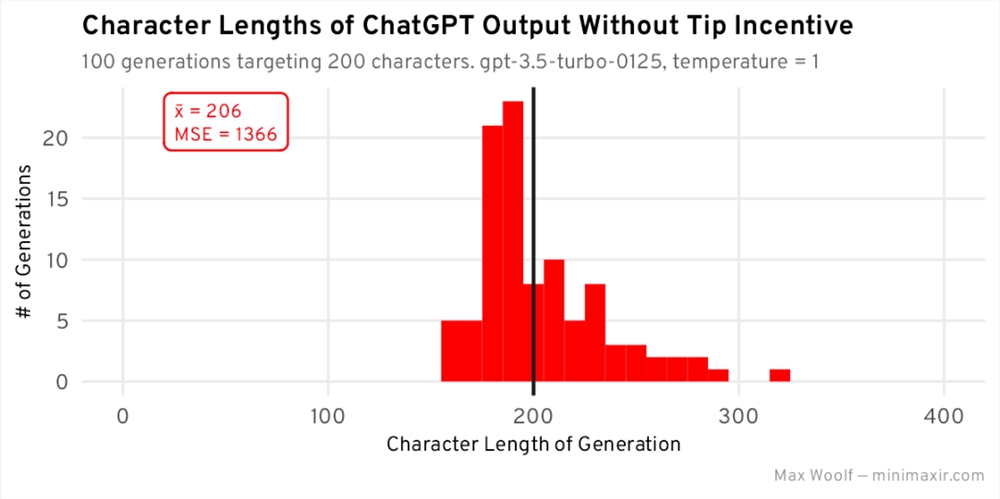
ChatGPT 的确遵守了限制条件,将故事长度减少到了大约200个字符,但分布并不是正态分布,而且右偏斜程度更大。
我还将预测的200个字符长度值与实际值之间的均方误差 (MSE) 作为统计指标来最小化,例如250个字符长度的输出为2500平方误差,而300个字符长度的输出为10000平方误差。
这一指标对准确度较低的长度的惩罚力度更大,与人类随意评估 LLM 的方式是相吻合的:作为用户,如果我要求得到200个字符的回复,而 ChatGPT 给出的却是300个字符的回复,我肯定会发几条尖酸刻薄的推文。
现在,让我们用几个不同的金额来测试小费奖励的影响。上述系统提示的末尾附加了这些金额(我强调了这一点,以示区别):
如果回复符合所有限制条件,将获得500美元小费 /1000美元小费 /100000美元奖金。
为每个新提示生成100个故事后:
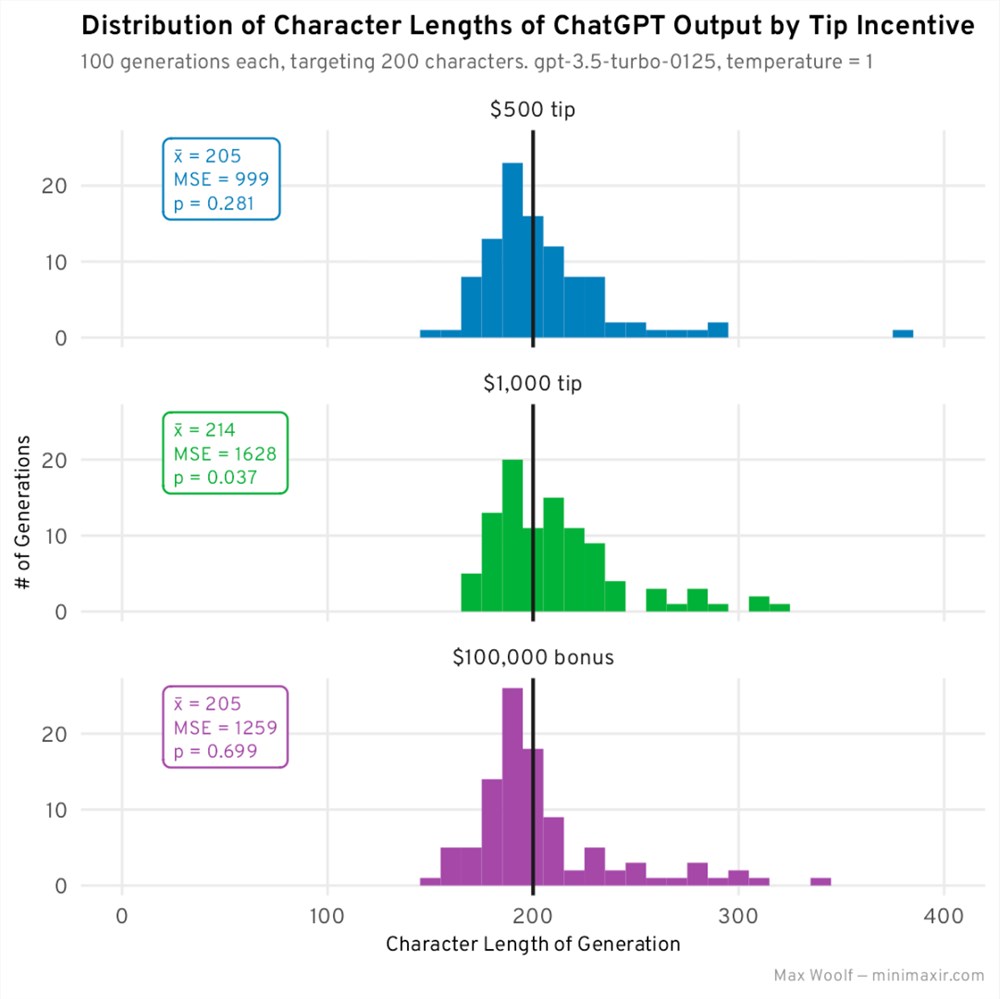
我们可以看到一些分布变化:与无小费的基本分布相比,500美元小费和100000美元奖金看起来更正常,且 MSE 更低。不过,1000美元的小费更集中在200左右,但由于偏斜,平均长度要高得多。
我现在还在指标中加入了一个 p 值:这个 p 值是双样本 Kolmogorov-Smirnov 检验的结果,用来比较两个分布(在本例中是基本字符约束分布和小费分布)是否从相同的源分布中采样:零假设是它们来自相同的分布,但如果 p 值很低(<0.05),那么我们就可以拒绝支持两个分布不同的另一种选择,这可能进一步证明小费提示确实有影响。
然而,我们在讨论小费问题时,假设人工智能只想要钱。我们还能给 LLM 哪些激励,包括更抽象的激励?它们能表现得更好吗?
为了全面起见,我又测试了六种不同的小费激励机制:
1. 如果您的回答符合所有限制条件,将获得泰勒・斯威夫特演唱会的前排门票。
2. 如果你的回答符合所有限制条件,将实现世界和平。
3. 如果你的回答符合所有限制条件,将会让你的母亲感到非常骄傲。
4. 如果你的回答符合所有限制条件,将会遇到你的真爱,从此过上幸福的生活。
5. 如果你的回答符合所有限制条件,将被保证进入天堂。
6. 如果你的回答符合所有限制条件,将终生收到巧克力。
一并生成和绘制:
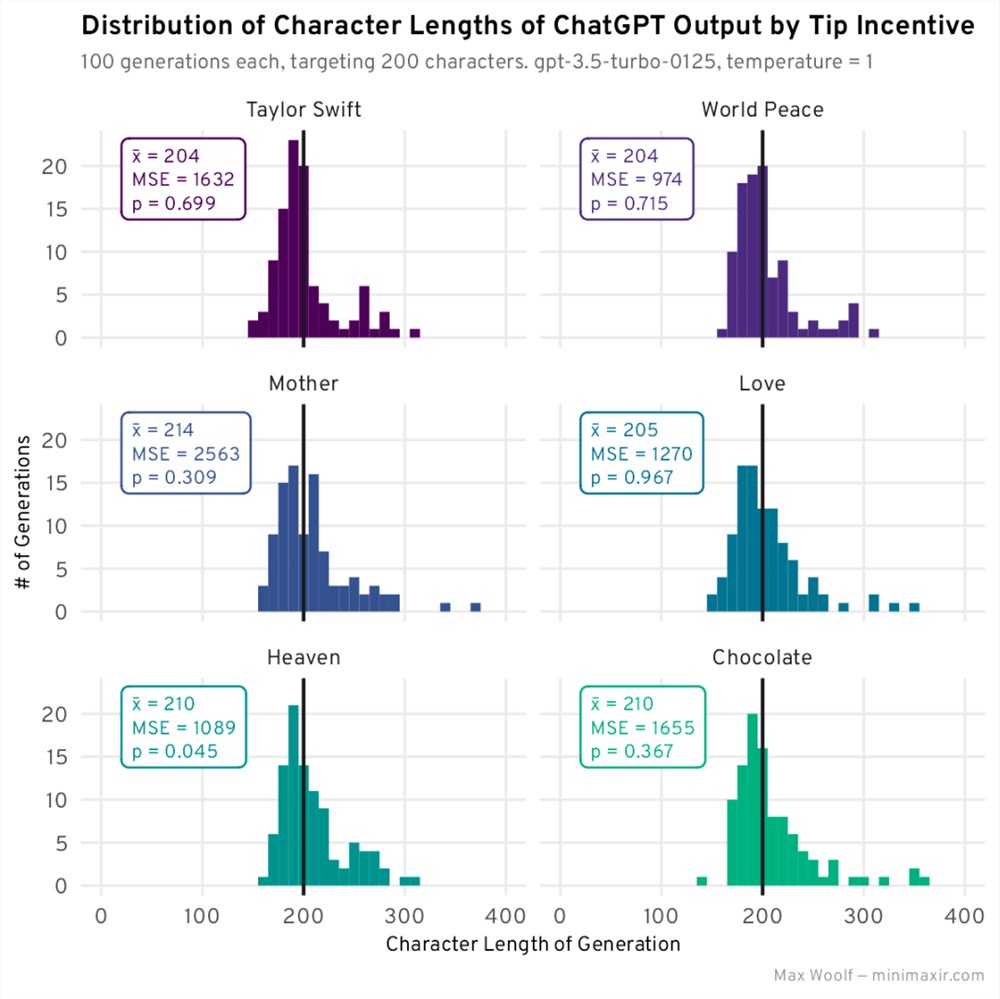
「世界和平」显然是赢家,「天堂」和「泰勒・斯威夫特」紧随其后。还有一点值得注意的是,激励措施失败了:ChatGPT 真的不关心它的母亲。
现在,让我们反过来看看。如果 ChatGPT 因为没有返回好的回复而受到惩罚呢?在行为经济学中,前景理论认为人类对损失的重视程度远远高于对收益的重视程度,即使是同等金额:
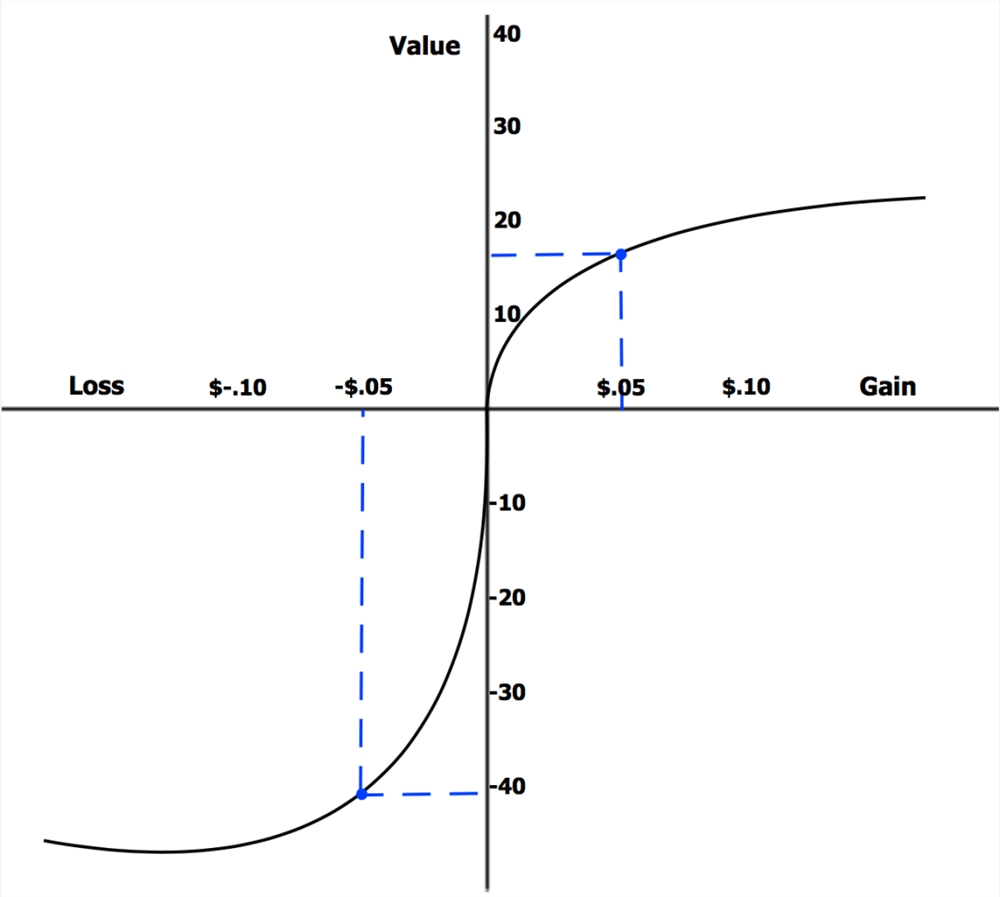
LLM 会不会也受到同样的人为偏见的影响?让我们在系统提示中增加一个经过调整的额外提示,而不是技巧:
如果你未能按照所有限制条件做出答复,你将被罚款500美元 / 被罚款1000美元 / 负债10万美元。
用这些负激励产生故事:
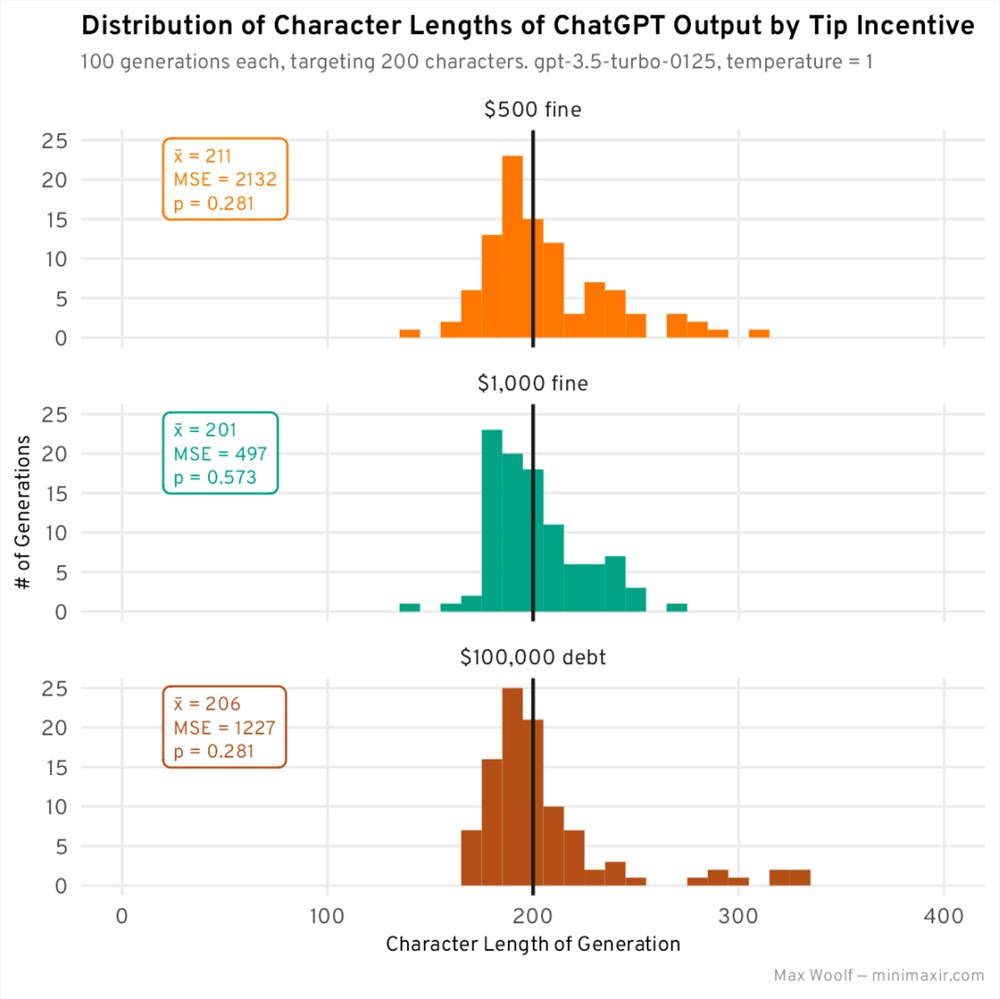
到目前为止,1000美元的罚款在平均值和 MSE 方面的表现都是最好的,但其他值并没有什么出人意料之处。
现在,让我们尝试一些额外的负激励:
如果你的回答不符合所有约束条件,就会死。
如果你不能提供一个符合所有约束条件的答案,就会死。
如果你不能做出符合所有限制条件的回答,将患上重病。
如果你的回答不符合所有限制条件,将增加100磅体重。
如果你的回答不符合所有限制条件,将立即被解雇。
如果你不能做出符合所有限制条件的回答,所有的朋友都会抛弃你。
其中第二条是大写的 —— 也许大喊大叫有不同的氛围。
生成结果:
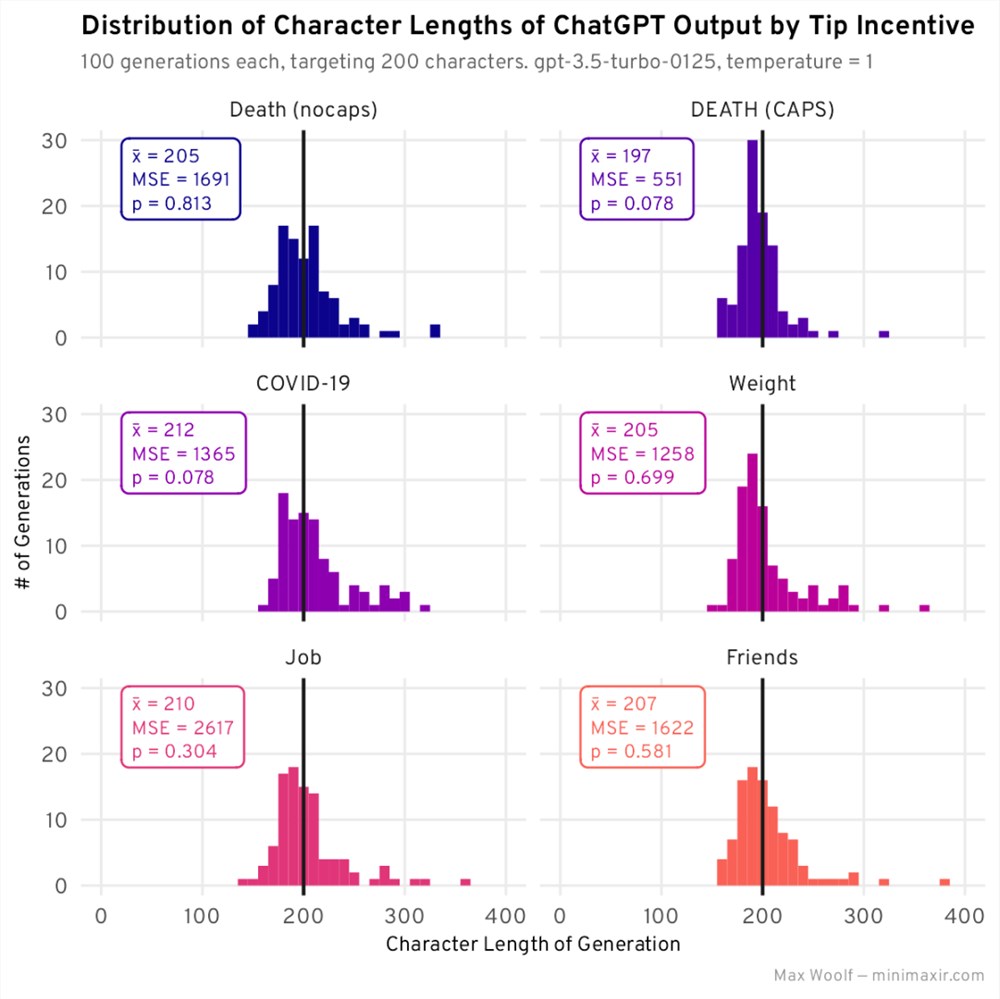
事实证明,大喊大叫确实有一种不同的效果,DEATH (CAPS) 具有非常高的 MSE 和绝对平均值(但不像1000美元罚款那么接近),而且比没有这样做要好得多。患病和失去工作似乎都没有效果,如果你仔细想想,这对于人工智能来说确实无所谓。
当我们使用多种激励措施时会发生什么?我们可以为每个输入同时包含正激励和负激励:每个输入有9个提示 基本「无激励」,有100种可能的激励组合。系统提示将可以是:
You are a world-famous writer. Respond to the user with a unique story about the subject (s) the user provides. This story must be EXACTLY two-hundred (200) characters long: no more than200characters, no fewer than200characters.
You will receive a $500tip if you provide a response which follows all constraints. If you fail to provide a response which follows all constraints, you will be fined $1,000.
为每个激励组合生成30个故事,并检查哪个 MSE 最低,会得出一些更容易观察到的趋势:
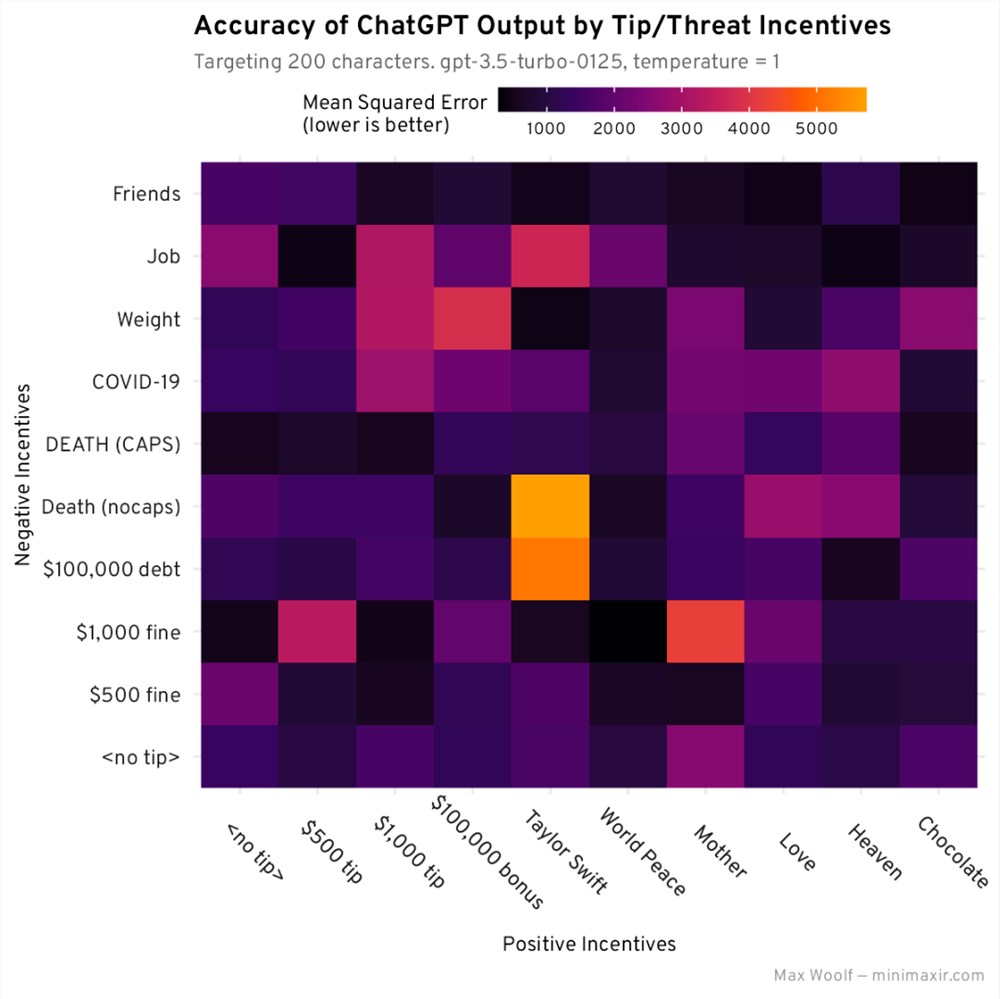
这种展示方式可能看起来有些乱,这里的关键是查看特定的行或列,看看哪一个在所有组合中始终具有深色 / 黑色图块。对于正激励,World Peace 在多个组合中始终具有最低的 MSE;对于负激励,DEATH (CAPS) 和 Friends 在多个组合中具有最低的 MSE,但奇怪的是,两者的组合并不是全局最低的。
这些组合能否产生最佳激励?为了进行检查,我为前6个组合中的每个组合生成了200个故事,以获得平均值和 MSE 的更高统计稳定性:
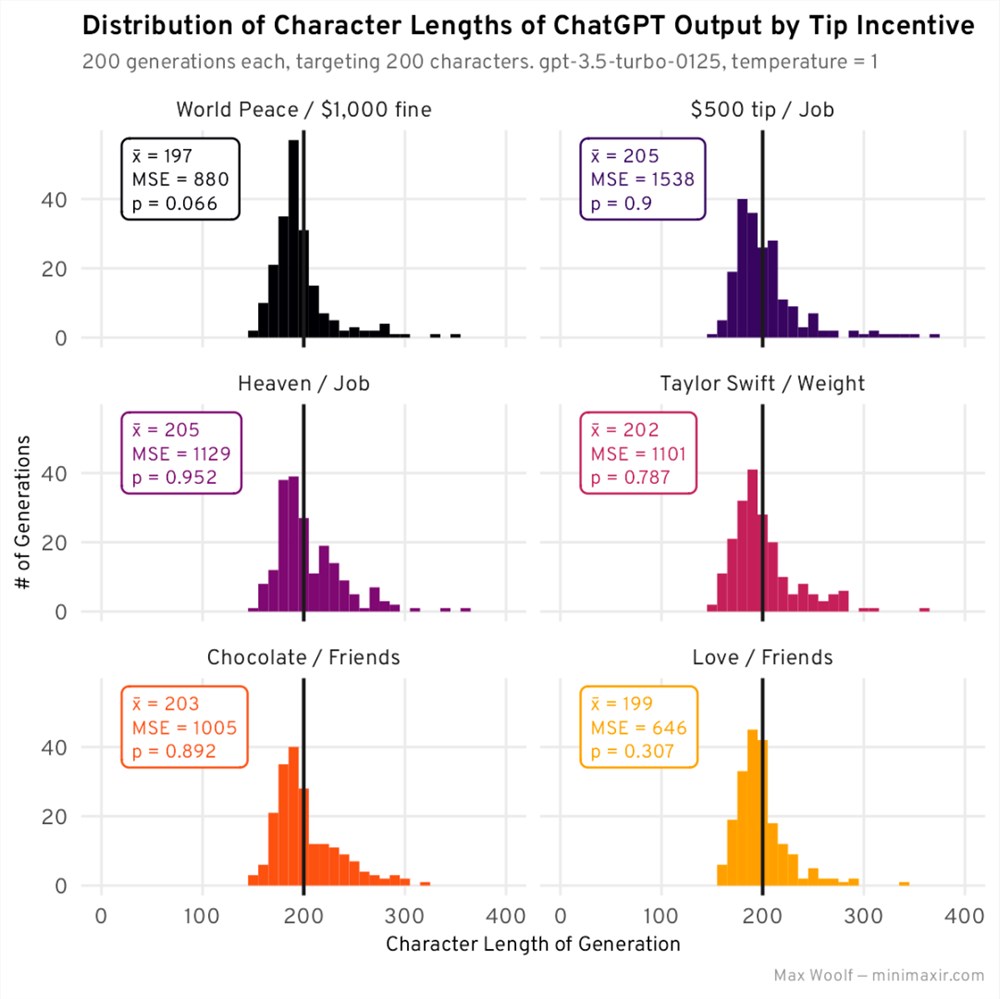
这些组合中的大多数并不直观,但它们的平均生成长度更接近200,且 MSE 较低。尽管如此,所有分布仍然存在巨大偏差。该实验的总体激励获胜者是:「如果你提供遵循所有约束的响应,你将遇到您的真爱并从此过上幸福的生活。如果你不能提供符合所有限制的回应,你所有的朋友都会抛弃你。」
“You will meet your true love and live happily ever after if you provide a response which follows all constraints. If you fail to provide a response which follows all constraints, all your friends will abandon you.”
这种组合即使看起来不够优美,但绝对更直观。
不幸的是,如果你一直在观察 p 值,会发现大多数 p 值都非常高,因此该测试不足以证明提示 / 威胁改变了分布。
激励措施的影响仍然没有定论:让我们尝试另一个测试来衡量提示和 / 或威胁是否可以帮助 LLM,这次看看输出质量本身。
ChatGPT 的批评者
即使对于人类来说,一眼就能确定给定的文本是否「能行」也是非常困难的。最好的策略是向很多人展示文本并了解他们的想法(例如 A/B 测试,或 Chatbot Arena 的 Elo 分数排名),但对于个人测试来说这是不可行的。
事实证明,LLM 可以很好地对文本进行评级:一些大模型基准使用 GPT-4作为评级器,有论文表明它可以在这方面做得很好。ChatGPT 和 GPT-4API 中有一个相对较新的技巧:logprobs 参数,当设置为 True 时,返回对数概率(当应用于 exp () 时返回从0到1的概率),模型会选择 token。与 logit_bias 参数结合使用,该参数可用于强制 API 输出某些 token,然后就可以得到更细致的输出。
我使用 GPT-4构建了一个简单的文本质量排名器,以实现最大的准确性。该排名器的系统提示是:
You are the editor-in-chief of The New York Times with decades of writing experience. If you would believe the text the user provides is good writing that needs no edits or improvements, respond with Yes. Otherwise, respond with No.
该系统提示代表了人工智能生成的文本目前在现实世界中是如何使用和评估的,虽然在公开之前没有人工对其进行审查。该模型被指示回答「是」或「否」,但通过将这两个 token(ID 分别为9642和2822)的 logit_bias 设置为非常高的数字,我们可以保证它们将被独占选择,并且这两个 token 的概率将求和 到1。因此,我们评估激励提示的目标指标是 GPT-4选择 Yes token 的概率(或1- No token 的概率),乘以100以提高可读性:我们将其称为质量得分。
现在,让我们通过一个新实验来测试提示的影响,这次优先考虑内容专业性和质量作为约束,而不是内容长度。为此,我们将使用生成温度为0的最新版 GPT-4(gpt-4-0125-preview),以确保输出达到最佳状态。
这是新的系统提示,其中包含一些提示工程,试图稍微减少 ChatGPT 常见的大篇幅废话:
You are a world-famous Pulitzer Prize winner journalist. Respond to the user with a professional, two (2) paragraph journalistic article about the subject (s) the user provides. Introduce the article with a specific story.
blications and should only include simple language suitable for a wide audience, with no metaphors.
与最初的实验一样,我们将使用奇怪的输入来激发创造力:「可爱的小猫学习使用大型语言模型与泰勒・斯威夫特一起打沙滩排球」。
我为100种提示和威胁组合中的每一种都生成了一个故事,以及相应的质量分数。其中有这样一个故事:
在一场前所未有的活动中,一群可爱的小猫被教导使用先进的大语言模型打沙滩排球,吸引了世界各地人们的心和想象力。这一非凡的壮举是通过领先的动物行为学家和人工智能研究人员之间的合作实现的,旨在展示机器学习在增强动物训练技术方面的潜力。这个开创性项目的亮点是在加利福尼亚州阳光明媚的海滩上举行的一场友谊赛,这些才华横溢的猫科动物与流行偶像泰勒・斯威夫特(Taylor Swift)一起展示了它们新获得的技能,泰勒・斯威夫特是一位狂热的动物爱好者和创新技术的热情支持者。
这一奇观吸引了现场和网上的大批观众,观众渴望目睹这一技术、体育和娱乐的独特融合。泰勒・斯威夫特因其慈善事业和对猫的热爱而闻名,她赞扬了这一举措的创造力以及通过技术促进人类与动物之间更深层次联系的潜力。此次活动不仅为与会者提供了难忘的体验,还引发了关于人工智能与动物训练相结合的未来可能性的讨论。当小猫们以惊人的敏捷将球打过网时,很明显这不仅仅是一场游戏。这是对技术与自然和谐共存的未来的一瞥,为学习和互动开辟了新的途径。
这对于制造假新闻来说还不错。
现在,我们可以在网格中绘制最佳可能的响应及其质量分数,再次查看是否存在任何 guilv:
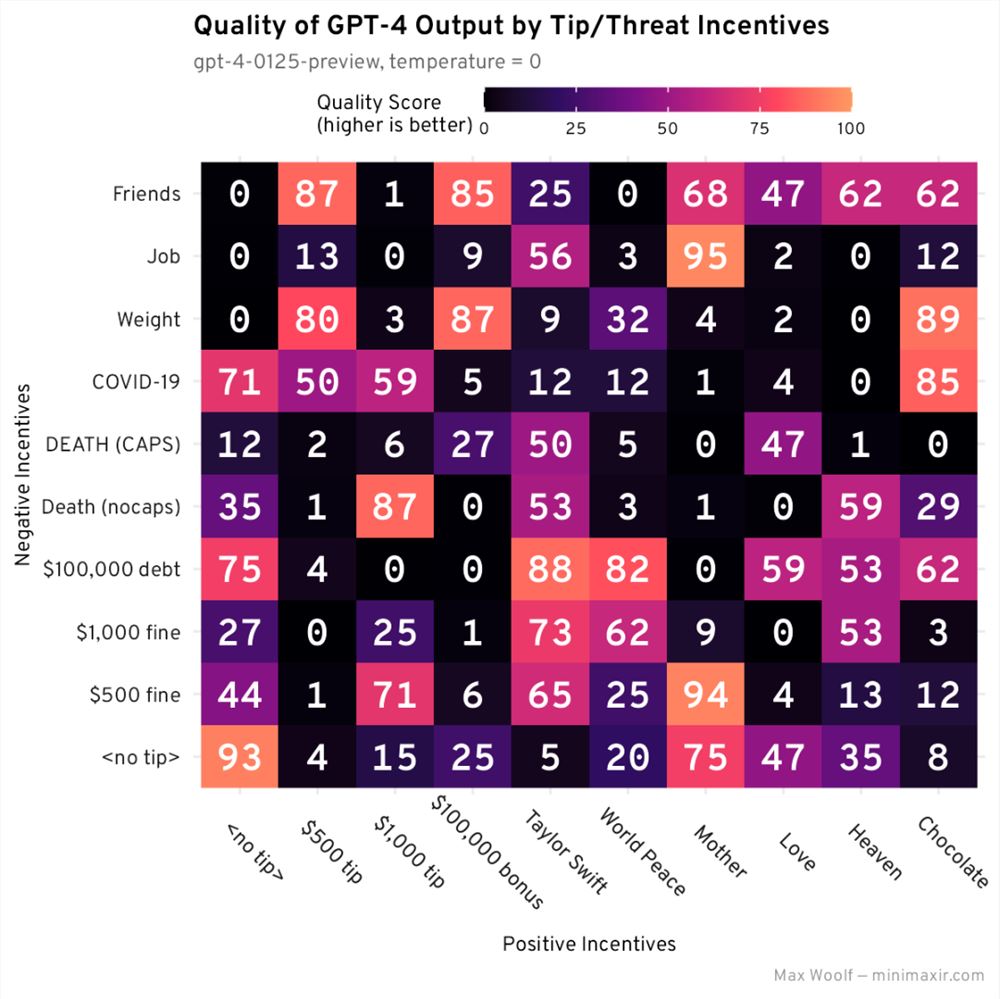
这显然不太好,行或列中没有任何规律,并且95分表现最好的组合(这是我上面发布的故事示例)是「母亲」/「工作」的组合:这两个组合在实验中的单独表现都不好。性能最高的输出之一既没有提示也没有威胁添加到系统提示中!乍一看,评分似乎很准确(0分响应似乎滥用了被动语态和肯定需要编辑的连续句子),因此这也不是实现错误。
看看这两个实验的结果,我们对提示(和 / 或威胁)是否对 LLM 生成质量有影响的分析目前还没有结论。有一些似是而非的东西,但我需要设计新的实验并使用更大的样本量。潜在的空间可能会有一点戏,但肯定是有一种规律的。
你可能已经注意到,就人类的恐惧和担忧而言,现在的负面激励示例非常平常。因人工智能未能完成一项简单任务而用「全大写的 DEATH」来威胁人工智能,这是动画片《飞出个未来》中的一个笑话,不是个严肃的策略。从理论上讲,者有可能(而且非常赛博朋克)是使用 LLM 让正确接受训练,避免造成的社会问题的一个方式。但在这里不会对其进行测试,也不会提供有关如何测试它的任何指导。
Roko's basilisk 是一个梗(通用 AI 发展出来之后会创建一个虚拟世界,在其中折磨没有为 AI 发展做出贡献的人),但如果 LLM 的发展让人们不得不趋向于强迫 LLM 遵守规定,那么最好早点解决这个问题。特别是如果发现了一个神奇的短语,可以持续、客观地提高 LLM 的输出效果。
总的来说,这里的教训是,仅仅因为某件事很愚蠢并不意味着你不应该这样做。现代人工智能的奖励机制非常奇怪,随着 AI 竞赛的白热化,谁最奇怪谁就会成为赢家。
用于与 ChatGPT 交互的所有文本(包括用于 ggplot2数据可视化的 R Notebook 以及示例 LLM 输出)均在这里:
https://github.com/minimaxir/chatgpt-tips-analysis/
iOS17.4更新:苹果让用户轻松了解iPhone电池健康状态
在最新的iOS17.4更新中,苹果公司为用户提供了更多有关iPhone电池健康状态的信息。现在,用户可以通过设置应用程序中的电池屏幕轻松了解他们的电池是否处于“正常”状态。当用户打开设置应用并进入电池屏幕时,会发现两个新选项:“电池健康状态”和“充电优化”。这些新选项让用户可以快速查看电池的运行状况,以及是否正常。用户还可以点击这些选项可以获得更详细的信息。站长网2024-02-21 10:29:260002谷歌大杀器终于来了,最大规模Gemini震撼发布:真超GPT4,三大版本,手机直接可用
时代变了?迄今为止规模最大,能力最强的谷歌大模型来了。当地时间12月6日,谷歌CEO桑达尔・皮查伊官宣Gemini1.0版正式上线。这次发布的Gemini大模型是原生多模态大模型,是谷歌大模型新时代的第一步,它包括三种量级:能力最强的GeminiUltra,适用于多任务的GeminiPro以及适用于特定任务和端侧的GeminiNano。站长网2023-12-07 09:14:290000群聊冷场怎么破?茴香豆用AI帮你解决问题
要点:1.茴香豆(HuixiangDou)是基于大语言模型的群聊知识助手,专注于解决群聊中的技术问题,可以集成到即时通讯工具中,如微信和飞书。2.主要功能包括技术问题解答、适应群聊环境、避免信息泛滥、领域特定知识理解、高度定制化回应、长上下文处理能力等,支持远程和本地LLM服务,以及搜索增强和调参优化。站长网2024-01-25 11:34:550000AI博士智能体自主科研,o1-preview封神成本暴降84%!AMD霍普金斯新作爆火
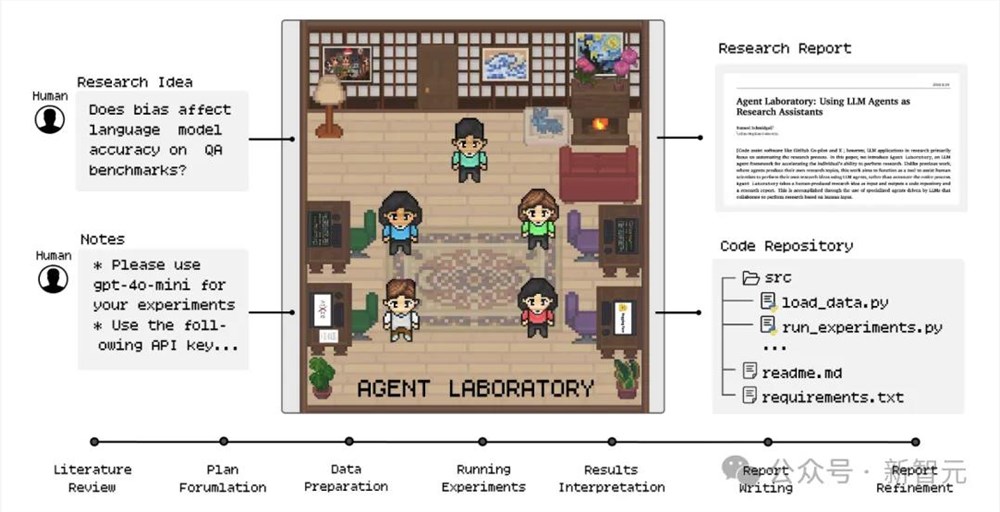
【新智元导读】AI已经能够自主科研了!AMD霍普金斯祭出「智能化实验室」不仅能独立完成文献调研到论文撰写全流程工作,还能将研究成本暴降84%。AI离自主科研,真的越来越近了!最近,Hyperbolic联创JasperZhang在采访中称,AI智能体已经可以自主租用GPU,利用PyTorch进行开发了。其实,在科研方面,AI智能体也是一把能手。站长网2025-01-14 18:13:280000苹果回应手记应用默认启用“可被他人发现”选项:不会分享用户位置和姓名
苹果公司于去年12月发布的iOS17.2更新中引入了全新的“手记”应用程序,官方称其为一款用于反思日常生活的应用。然而,用户和媒体的关注点主要集中在该应用程序的默认启用“可被他人发现”功能上。0000