大模型时代的OCR,“CPU” 的味道更重了
经典技术OCR(光学字符识别),在大模型时代下要“变味”了。
怎么说?
我们都知道OCR这个技术在日常生活中已经普及开了,像各类文件、身份证、路标等识别,可以说统统都离不开它。
而随着近几年大模型的不断发展,OCR也迎来了它的“新生机”——
凭借自身可以将文本从图片、扫描文档或其他图像形式提取出来的看家本领,成为大语言模型的一个重要入口。
在这个过程中,一个关键问题便是“好用才是硬道理”。
过去人们会普遍认为,像OCR这种涉及图像预处理、字符分割、特征提取等步骤的技术,堆GPU肯定是首选嘛。
不过朋友,有没有想过成本和部署的问题?还有一些场景甚至连GPU资源都没得可用的问题?
这时又有朋友要说了,那CPU也不见得很好用啊。
不不不。
现在,大模型时代之下,CPU或许还真是OCR落地的一种新解法。
例如在医保AI业务中,在CPU的加持之下,医疗票据识别任务的响应延时指标,在原有基础上提升达25倍!
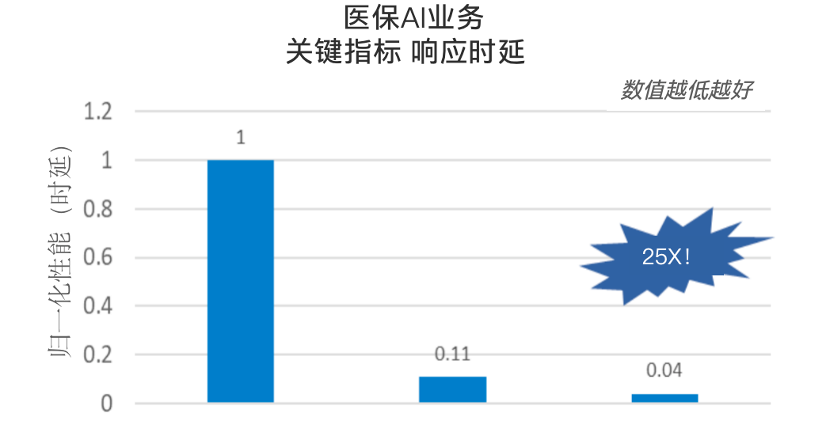
△数据来源:英特尔合作伙伴
为什么会有如此大的转变?
一言蔽之,因为此前做OCR任务的时候,CPU的计算潜能并没有完全释放出来。
OCR,进入CPU时代
那么到底是谁家的CPU,能让经典OCR产生这般变化。
不卖关子。
它正是来自英特尔的第四代至强®️可扩展处理器。
据了解,第四代至强可扩展处理器增加了每个时钟周期的指令,每个插槽多达60个核心,支持8通道DDR5内存。
在内存宽带方面实现了50%的性能提升,并通过每PCIe5.0(80个通道)实现了2倍的PCIe带宽提升,整体可实现60%的代际性能提升。
但解锁如此能力的,可不仅仅是一颗CPU这么简单,是加成了英特尔软件层面上的优化;换言之,就是“软硬一体”后的结果。
而且这种打法也不是停留在PPT阶段,而是已经实际用起来的那种。
例如国内厂商用友便在自家OCR业务中采用了这种方案。
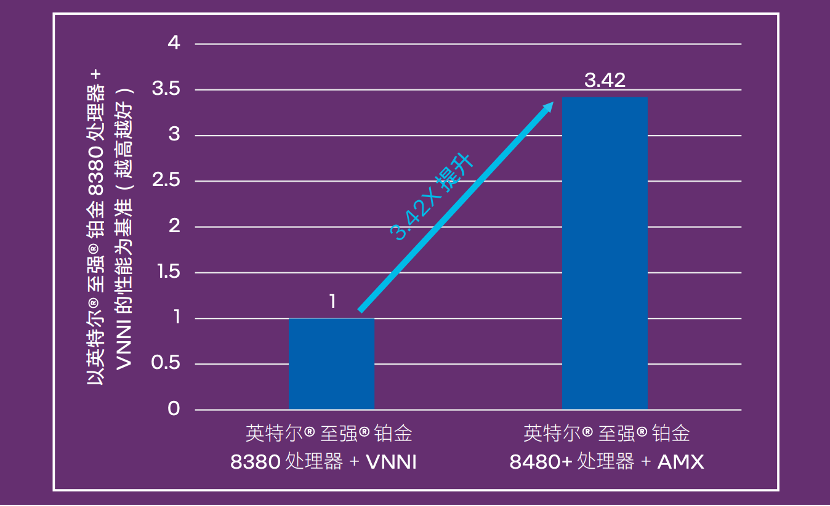
性能比较上,用友在第三/第四代英特尔®️至强®️可扩展处理器上进行了算法对比,推理性能提升达优化前的3.42倍:
而在INT8量化后的性能更是提升到原来的7.3倍:

值得一提的是,OCR的响应时间直接降低到了3秒以内,还是切换架构不影响业务,用户无感知的那种。
除了用友之外,像亚信科技在自家OCR-AIRPA方案中,也是采用了英特尔的这套打法。
与用友类似的,亚信科技实现了从FP32到INT8/BF16的量化,从而在可接受的精度损失下,增加吞吐量并加速推理。
从结果上来看,相比传统人工方式,成本降到了1/5到1/9之间,而且效率还提升了5-10倍。
由此可见,释放了AI加速“洪荒之力”的CPU,在OCR任务上完全不亚于传统GPU的方案。
那么问题来了:
英特尔是如何释放CPU计算潜力的?
实际应用过程中,企业通常选择自己使用CPU来做OCR处理,但由于缺乏对CPU硬件加速和指令集的了解,就会发现CPU处理性能与理想峰值相差甚远,OCR程序也就没有得到很好的优化。
至于以往更常见的GPU解决方案,始终存在着成本和部署的难题。一来成本通常较高,且很多情况下,业务现场没有GPU资源可以使用。
但要知道OCR本身应用广泛、部署场景多样,比如公有云、私有云,以及边缘设备、终端设备上……而且随着大模型时代的到来,作为重要入口的OCR,更多潜在场景将被挖掘。
于是,一种性价比高、硬件适配性强的解决方案成为行业刚需。
既然如此,英特尔又是如何解决这一痛点的呢?
简单归结:第四代至强®️可扩展处理器及其内置的AI加速器,以及OpenVINO™️ 推理框架打辅助。
当前影响AI应用性能的要素无非两个:算力和数据访问速度。第四代至强®️可扩展处理器的单颗CPU核数已经增长到最高60核。
而在数据访问速度上,各级缓存大小、内存通道数、内存访问速度等都有一定程度的优化,另外部分型号还集成了HBM高带宽内存技术。

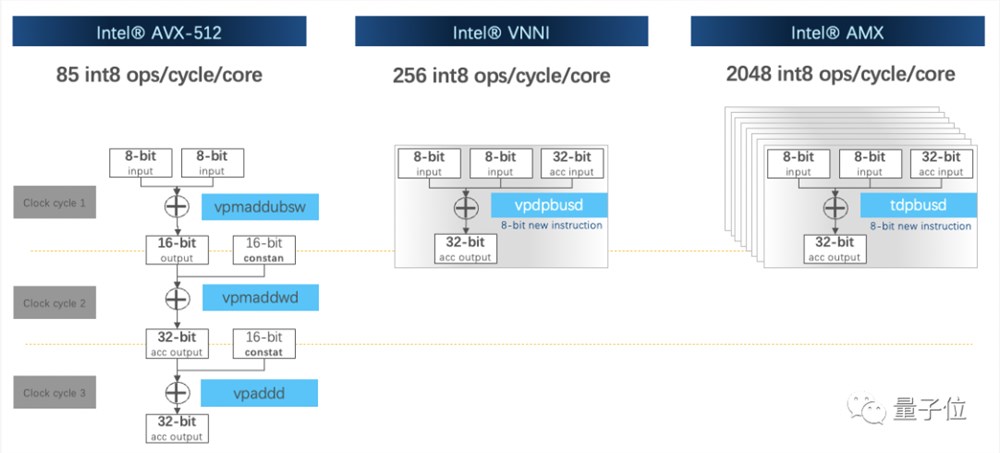
此外,在CPU指令集上也做了优化,内置了英特尔®️高级矩阵扩展(英特尔®️AMX)等硬件加速器,负责矩阵计算,加速深度学习工作负载。
这有点类似于GPU里的张量核心(Tensor Core)。
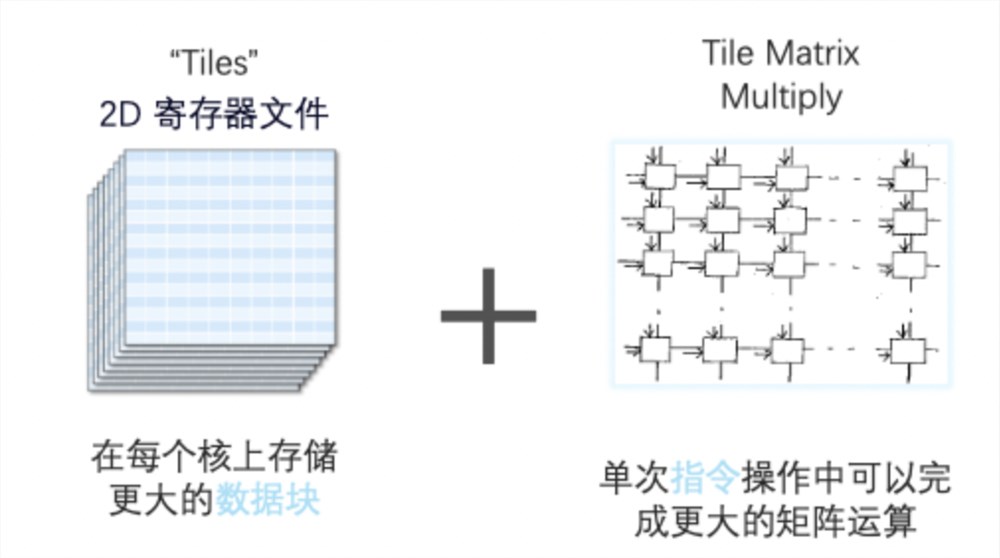
AMX由两部分组成,一部分是1kb大小的2D寄存器文件,另一部分是TMUL模块,用来执行矩阵乘法指令。
它可同时支持INT8和BF16数据类型,且BF16相较于FP32计算性能更优。
有了AMX指令集加持,性能比矢量神经网络指令集VNNI提升达8倍。
除了核心硬件平台外,实际情况中帮助OCR在CPU上落地的,还有推理框架OpenVINO™️。
市面上大部分AI框架都是同时支持训练和推理,OpenVINO™️则是删减了很多训练部分所需的冗余计算,主要支持推理部分。
而且也是专门针对英特尔硬件打造的优化框架。框架替换也不复杂,只需5行代码就可以完成原有框架的替换。
用户可以针对不同业务场景,来优化OpenVINO™️运行参数。
比如用友OCR业务涉及文字检测和文字识别两个AI模型,优化方向有所不同。
前者对单次推理要求高,后者需要整个系统吞吐量的优化,那么OpenVINO™️分别采用单路同步模式和多路异步模式。单一模块优化后,再针对整体流程的优化。
这样一套软硬件组合拳打下来,英特尔充分释放了CPU计算潜力,在实际场景中也实现了与GPU同等性能。
不再是你以为的CPU
以往谈到AI加速、AI算力,大众经常想到的就是GPU,又或者是专用TPU。
至于通用架构芯片CPU,受到计算单元和内存带宽的限制,始终无法适应于计算数据庞大的深度学习。
但现在的CPU,已经不再是“你以为的你以为”了:
它可以深入到各个行业当中,轻松Hold住各种场景应用。
尤其在AMX加速引擎加持下,能将深度学习训练和推理性能提升高达10倍。
比如,媒体娱乐场景中,能帮助个性化内容推荐速度提升达6.3倍;零售行业里,能将视频分析速度提升高达至2.3倍,还有像工业缺陷检测、医疗服务也都能从容应对。
即便是在前沿探索领域,CPU也已经成为不容忽视的存在:
像是在生命科学和医药方向,在某些场景下的表现效果甚至比GPU还要好。
英特尔用CPU速刷AlphaFold2,结果力压AI专用加速芯片,去年发布的第三代至强®️可扩展处理器经过优化后就能使其端到端的通量足足提升到了原来的23.11倍。今年基于第四代至强®️可扩展处理器再次把性能提升到了上一代产品的3.02倍。

不过要实现CPU加速,背后也并非简单的硬件优化。
而是软硬件融合协同,从底层到应用的一整套技术创新,以及产业链上合作伙伴的支撑。
随着大模型时代的到来和深入,这种解决思路也正在成为共识。
像一些大模型玩家要实现大模型优化和迭代,并不能依靠以往单纯三驾马车来解决,而是需要从底层芯片到模型部署端到端的系统优化。
在算力加速层面的玩家,一方面摆脱不了摩尔定律的极限,另一方面要在应用场景中充分释放计算潜力,就需要与软件适配快速部署。
有意思的是,在最近OCR主题的《至强实战课》中,英特尔人工智能软件架构师桂晟曾这样形容英特尔的定位:
英特尔不仅仅是一个硬件公司,同时也拥有着庞大的软件团队。
在整个人工智能生态中,不论是从底层的计算库,到中间的各类组件,框架和中间件,再到上层的应用,服务和解决方案都有英特尔软件工程师的参与。

CPU加速,不再是你以为的加速。英特尔,也不再是以往所认知中的硬件公司。
但如果你以为英特尔只有CPU来加速AI,那你又单纯了。
针对AI的专用加速芯片Habana®️Gaudi2®️即将迎来首秀;而通用加速芯片,同时兼顾科学计算和AI加速的英特尔®️数据中心GPU Max系列也刚刚结束了它在阿贡实验室Aurora系统中的部署,即将走近更多客户。
以这些多样化、异构的芯片为基石,英特尔也将形成更全面的硬件产品布局,并配之以跨异构平台、易用的软件工具组合(oneAPI)为整个应用链上的合作伙伴及客户提供应用创新的支持,为各行各业AI应用的开发、部署、优化和普及提供全方位支持。
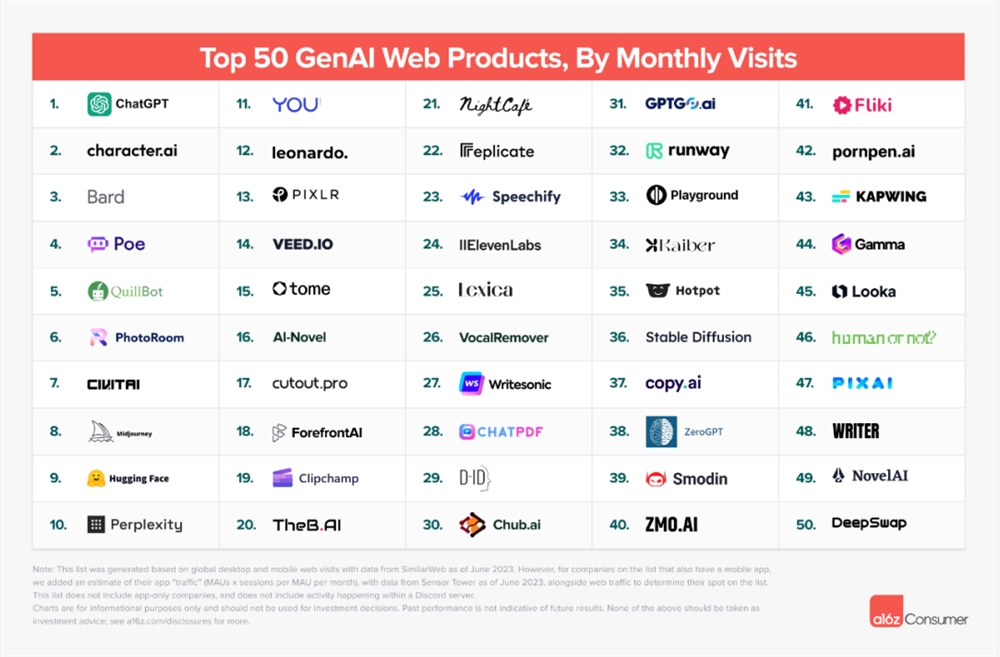
全球流量Top50的“AI网站”出炉:C端用户都愿意用AI干什么?
AI这一波热潮,我们接触到更多的其实是面向B端的应用,例如废料处理、例如医疗、甚至养殖产业,都有创业者做效率的提升。而面向C端的应用落地,却始终局限在几个方向上。而最近,美国知名科技风投公司a16z对目前市场上流量最高的50款面向C端用户开放的AI产品进行了排名,参考这份排名,本文刚好就上述角度做一次观察。站长网2023-10-07 09:33:410004微软Edge将使用AI实时翻译你观看的YouTube视频内容
划重点:⭐微软Edge将推出实时翻译功能,可在观看YouTube等视频时进行实时翻译⭐该功能将支持多种语言和多个视频网站⭐翻译将在用户设备上完成,不会离开用户设备或在云端处理站长网2024-05-24 10:09:050000ChatGPT有桌面版本了!GPT4o可检测人的情绪
今日凌晨,科技巨头OpenAI再次掀起人工智能浪潮,全新旗舰大模型GPT-4o正式亮相。同时,OpenAI还宣布将推出ChatGPT桌面版应用程序,首先向Plus用户推出macOS版,未来计划推出Windows版本。站长网2024-05-14 09:39:440001麦当劳已经用类Sora模型,制作商业广告啦!
知名生成式AI平台Luma在社交平台展示了,即将发布的文生视频平台DreamMachine1.5版本。这是一个类似Sora的模型,通过文本就能生成各种视频。目前,已经有一些用户可以使用最新版本,根据体验生成效率、视频质量、光影效果、语义还原、色彩搭配等方面都比前一代更强。站长网2024-08-19 09:07:5600002023 年时尚界 7 大值得关注的人工智能创新
当我们看到世界各地的公司纷纷在日常工作流程中实施生成式人工智能的潮流时,时尚行业也在用各种方式应用AI。特别是在2023年的最后六个月。人工智能一直是分析趋势驱动系列数据的催化剂,并且在开发环保材料、优化生产以实现可持续发展和更多的。现在,让我们来探讨一下今年人工智能在时尚行业应用的一些关键进展。图源备注:图片由AI生成,图片授权服务商MidjourneyMeta0000