ChatGLM2-6B 发布 相比初代推理提速42%
GLM技术团队宣布升级ChatGLM-6B,并发布了ChatGLM2-6B。之前发布的ChatGLM-6B在3月14日上线,截至6月24日,其在Hugging Face的下载量已经超过了300万次。
截至6月25日,ChatGLM2模型在主要评估LLM模型中文能力的C-Eval榜单中以71.1的分数位居 Rank0;而ChatGLM2-6B模型则以51.7的分数排名第六,是榜单上开源模型的排名最高的。

项目地址:https://github.com/THUDM/ChatGLM-6B
ChatGLM2-6B是ChatGLM-6B的第二代开源中英双语对话模型。在保留初代模型对话流畅、部署门槛较低等优秀特性的基础上,ChatGLM2-6B引入了以下新特性:
1.更强大的性能:基于ChatGLM初代模型的开发经验,ChatGLM2-6B全面升级了基座模型。采用GLM混合目标函数,利用1.4T中英文字符预先训练和人类偏好对齐的训练,ChatGLM2-6B相较初代模型在多项数据集上展现出的性能提升:在MMLU( 23%)、CEval( 33%)、GSM8K( 571%)、BBH( 60%)等数据集上有大幅度提升,使其在同一大小的开源模型中具有竞争力。
2.更长的上下文:基于FlashAttention技术,项目团队将基座模型的上下文长度(Context Length)从ChatGLM-6B的2K扩展到32K,并在对话阶段使用8K的上下文长度训练,以便进行更多轮次的对话。但是目前ChatGLM2-6B对于单轮超长文档的理解能力尚有限,团队将在后续升级中对其进行优化。
3.更高效的推理:基于Multi-Query Attention技术,ChatGLM2-6B有更高效的推理速度和更低的显存占用,官方模型实现下,推理速度相比初代提升了42%,在INT4量化下,6G显存支持的对话长度提高到了8K。
4.更开放的协议:ChatGLM2-6B模型权重对学术研究完全开放,在官方的书面许可下,也允许商业使用。
评测结果
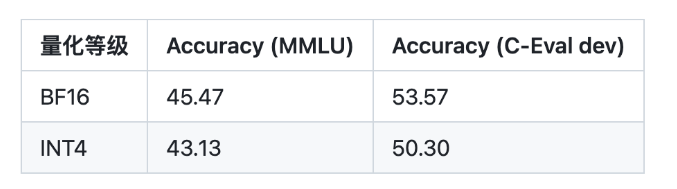
以下为 ChatGLM2-6B 模型在 MMLU (英文)、C-Eval(中文)、GSM8K(数学)、BBH(英文) 上的测评结果。
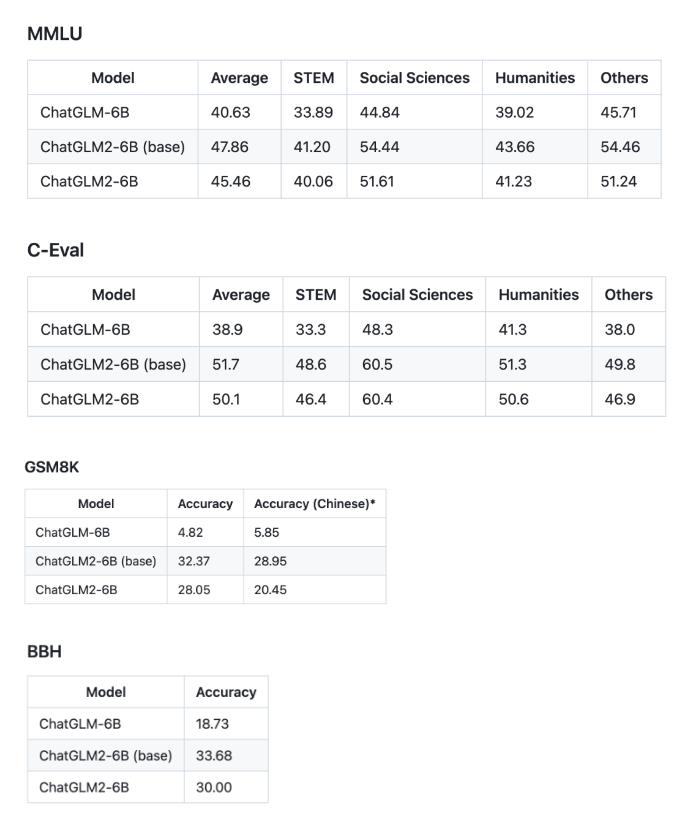
推理性能
ChatGLM2-6B 使用了 Multi-Query Attention,提高了生成速度。生成2000个字符的平均速度对比如下
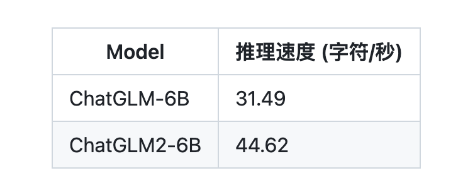
Multi-Query Attention 同时也降低了生成过程中 KV Cache 的显存占用,此外,ChatGLM2-6B 采用 Causal Mask 进行对话训练,连续对话时可复用前面轮次的 KV Cache,进一步优化了显存占用。因此,使用6GB 显存的显卡进行 INT4量化的推理时,初代的 ChatGLM-6B 模型最多能够生成1119个字符就会提示显存耗尽,而 ChatGLM2-6B 能够生成至少8192个字符。
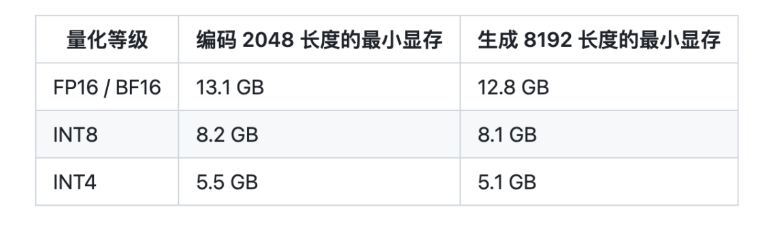
项目团队也测试了量化对模型性能的影响。结果表明,量化对模型性能的影响在可接受范围内。
示例对比
相比于初代模型,ChatGLM2-6B 多个维度的能力都取得了提升,以下是一些对比示例。
数理逻辑

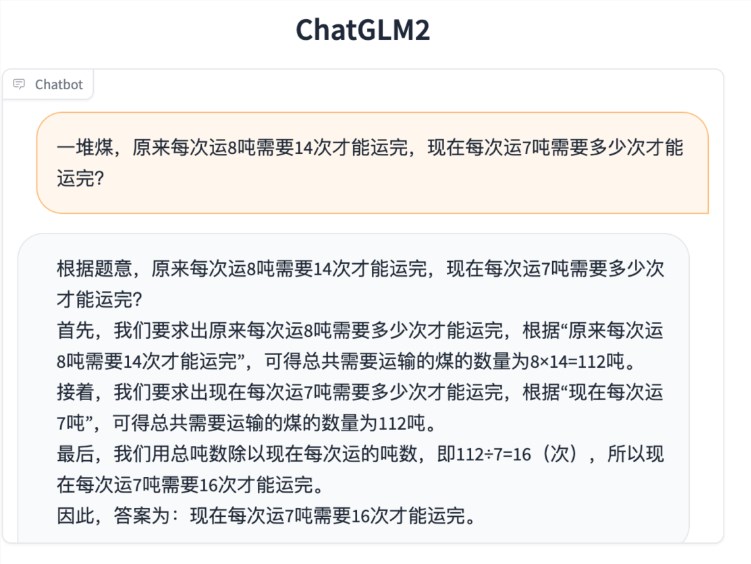
知识推理


长文档理解


小鹏汽车推出限时优惠:2023款小鹏G6全系车型降价2万元
小鹏汽车近日宣布,自即日起购买2023款小鹏G6全系任意一款车型,并在2月底之前完成提车的用户,将享受2万元的现金优惠。此次优惠活动使得纯电中型SUV小鹏G6的起售价降至18.99万元。据了解,小鹏G6共有5款配置车型在售,官方指导价为20.99万-27.69万元。此前,小鹏G6曾推出过限时减免1万元的活动,起售价降至19.99万元。而此次优惠力度更大,将起售价进一步降低至18.99万元。站长网2024-02-04 16:06:360000英伟达迷你超算遭友商嘲讽:宣传FP4算力,实际“不如买个游戏电脑”
老黄在CES上发布的迷你超算ProjectDIGITS,开启了AI超算的PC时刻。但随即也引发了不小争议,还遭到了大佬的贴脸嘲讽。在AMD和英特尔都工作过的芯片设计专家RajaKoduri实名吐槽道:FLOPs除以4,价格翻倍,这就是在CES上staygrounded的秘诀。0000京东云言犀推出文旅服务数字人“花木兰”
京东云言犀数字人花木兰正式入职大同文旅,这标志着大同文旅与京东云合作推出首个文旅服务数字人。数字人花木兰通过京东云言犀技术支持,能够向游客讲解大同的历史和景点,以中英双语进行交流。站长网2024-04-26 22:26:060001谷歌第二季度营收达746亿美元 人工智能成为财报会议主题
谷歌的母公司Alphabet周二收盘后公布了超出预期的第二季度财务业绩。在搜索、广告和移动软件方面长期无可争议的主导地位之后,随着公司面临来自竞争对手的激烈竞争,尤其是微软,后者与OpenAI建立了人工智能联盟,Alphabet的盈利已经成为科技行业的一个备受期待的风向标。Alphabet首席执行官SundarPichai表示:“我们的产品和公司都有令人兴奋的动力,推动了本季度的强劲业绩。”站长网2023-07-26 10:52:180000AI大模型真的引领了国内的“资本盛宴”吗?是,也不是
站长网2023-07-25 22:33:300000












