Stack Overflow 版主罢工抗议平台放宽AI生成内容要求
日前,程序员问答论坛Stack Overflow 版主宣布他们将罢工,理由是该公司禁止在该平台上审核 AI 生成的内容。版主在公司的Meta board上宣布罢工,并发布了一封直接写给Stack Overflow的附信。
上周,Stack Overflow 宣布了其新的审核政策表明,该政策将只在特定情况下删除人工智能生成的内容,声称人工智能发布的帖子过度审核会拒绝人类贡献者。生成的内容,声称对人工智能发布的帖子的过度审核正在损害人类贡献者。

该公司还在其帖子中表示,为了管理人工智能内容,需要使用严格的标准。在公开发布之前,该指令还私下传达给了平台的审核团队。该网站的版主声称,这一指令将允许经常不正确的人工智能内容在论坛上泛滥成灾,同时对Stack Overflow 溢出表示不满,因为没有更有效地沟通这一新政策。
信中写道,Stack Overflow, Inc. 已下令几乎完全禁止审核 AI 生成的内容,因为大量此类内容被发布到 Stack Exchange 网络并随后从 Stack Exchange 网络中删除,这默认允许不正确信息的扩散(“幻觉” ”)和 Stack Exchange 网络上不受约束的剽窃。这对平台及其内容的完整性和可信度构成了重大威胁。Stack Overflow 网络中的一小部分版主 (11%) 已经停止参与多项活动,包括审核内容。
版主表示,他们试图通过适当的渠道表达对公司新政策的担忧,但他们的焦虑被置若罔闻。因此计划无限期罢工,并将停止所有行动,包括关闭帖子、删除帖子、标记答案和其他有助于网站维护的任务,直到撤回 AI 政策。
AI最近一直在改变 Stack Overflow,无论好坏。Stack Overflow 证实,由于 OpenAI 的 ChatGPT,流量正在下降,因为越来越多的程序员开始转向聊天机器人来调试他们的代码,而不是在论坛上等待人工回复。
网络分析公司 SimilarWeb 在4月份报告称,自2022年初以来,Stack Overflow 的流量每月都在下降,平均降幅为6%。3月份,Stack Overflow 的流量比2月份下降了13.9%,4月份,该网站的流量比3月份下降了17.7%。
网信办公布第三批深度合成服务算法备案信息 淘宝、抖音、网易等在列
站长之家(ChinaZ.com)1月8日消息:根据国家互联网信息办公室1月5日发布的公告,包括淘宝、抖音、网易等在内的多家企业已对其深度合成服务算法进行了备案。据悉,根据《互联网信息服务深度合成管理规定》第十九条,具有舆论属性或者社会动员能力的深度合成服务提供者需要履行备案手续。以下是部分已备案的企业及算法名称:淘宝:淘宝图像风格化生成算法、淘宝对话生成算法天猫:天猫对话生成算法0000《西部世界》真来了!斯坦福爆火「小镇」开源,25个AI智能体恋爱交友|附保姆级教程
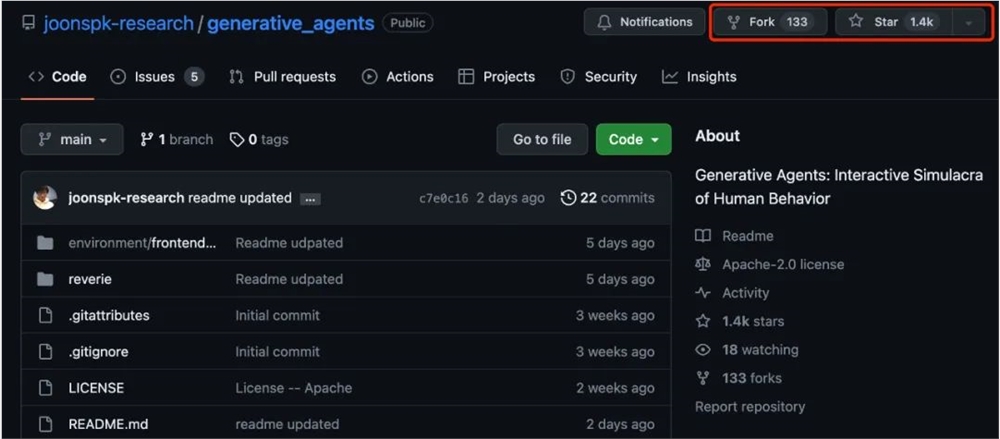
【新智元导读】斯坦福25个AI智能体「小镇」终于开源了,GitHub狂揽1.4k星,《西部世界》即将走进现实。准备好,此前曾轰动整个AI社区的斯坦福智能体小镇,现在已经正式开源!项目地址:https://github.com/joonspk-research/generative_agents在这个数字化的「西部世界」沙盒虚拟城镇中,有学校、医院、家庭。站长网2023-08-10 13:58:460003Anthropic 超越 OpenAI 的聊天机器人 Claude AI 能在一分钟内分析整本书
聊天机器人经常被忽视的一个限制是记忆能力。虽然这些系统的AI语言模型是基于TB级的文本上训练的,但它们在使用过程中能够处理的文本量(即输入文本和输出的组合,也称为「contextwindow上下文窗口」)是有限的。对于ChatGPT来说,大约是3000个单词。虽然有办法可以解决这个问题,但它仍然不是大量的信息。站长网2023-05-15 11:43:210001智源推Vision Mamba 高效处理视觉任务,内存能省87%
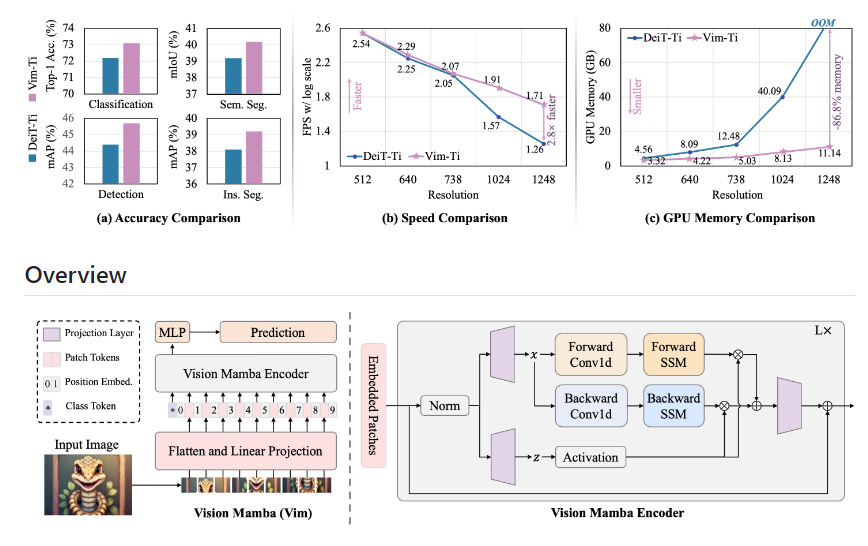
要点:1.VisionMamba在图像分类任务、对象检测任务和语义分割任务上性能更高,同时提高计算和内存效率。2.Mamba的提出引发了对状态空间模型的兴趣,并在语言建模中取得成功。3.VisionMamba块整合了双向序列建模和位置嵌入,实现了高效的视觉任务处理。站长网2024-01-19 14:45:180001苹果 iPhone 15 Pro 仍有望采用「Action」操作按钮而不是静音开关
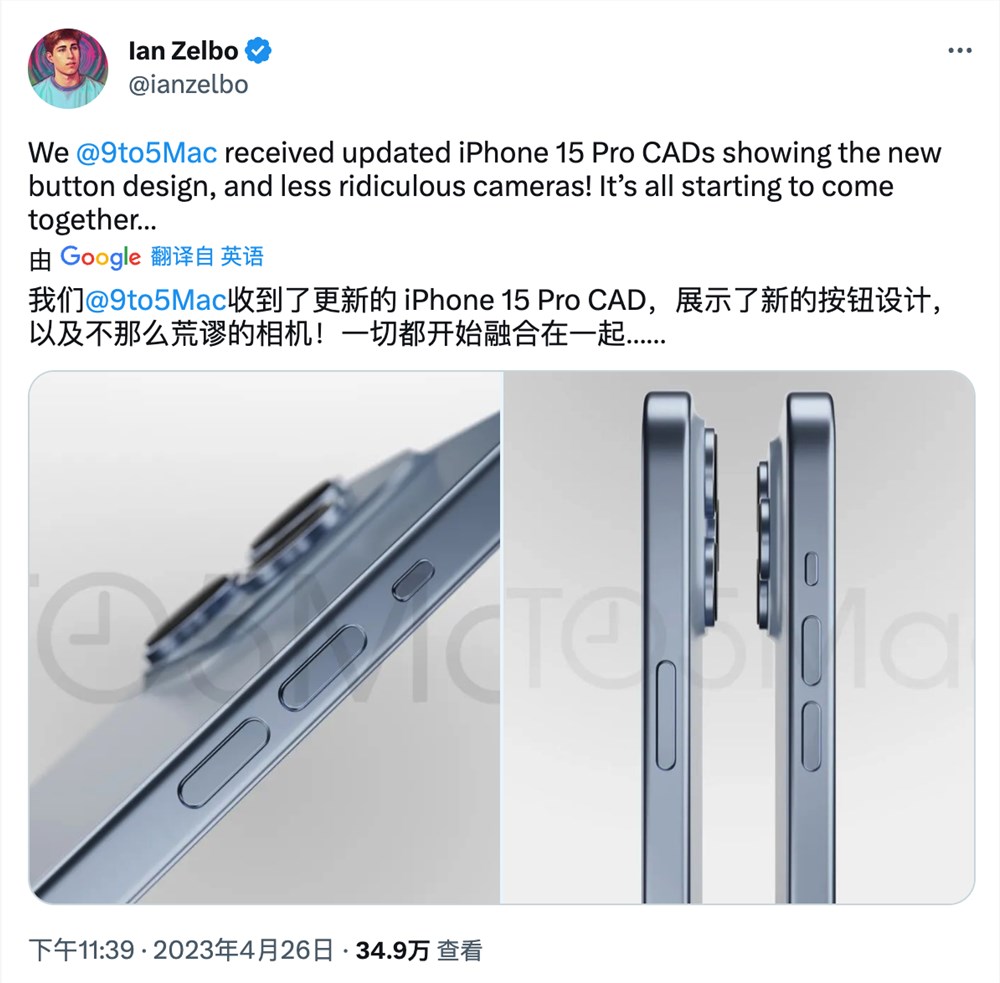
站长之家(ChinaZ.com)4月27日消息:虽然最新的传言称苹果放弃了在iPhone15Pro机型上使用固态按钮的计划,但即将推出的设备仍有望配备一个可定制的「Action」操作按钮,以取代传统的铃声/静音开关。站长网2023-04-27 09:39:330000