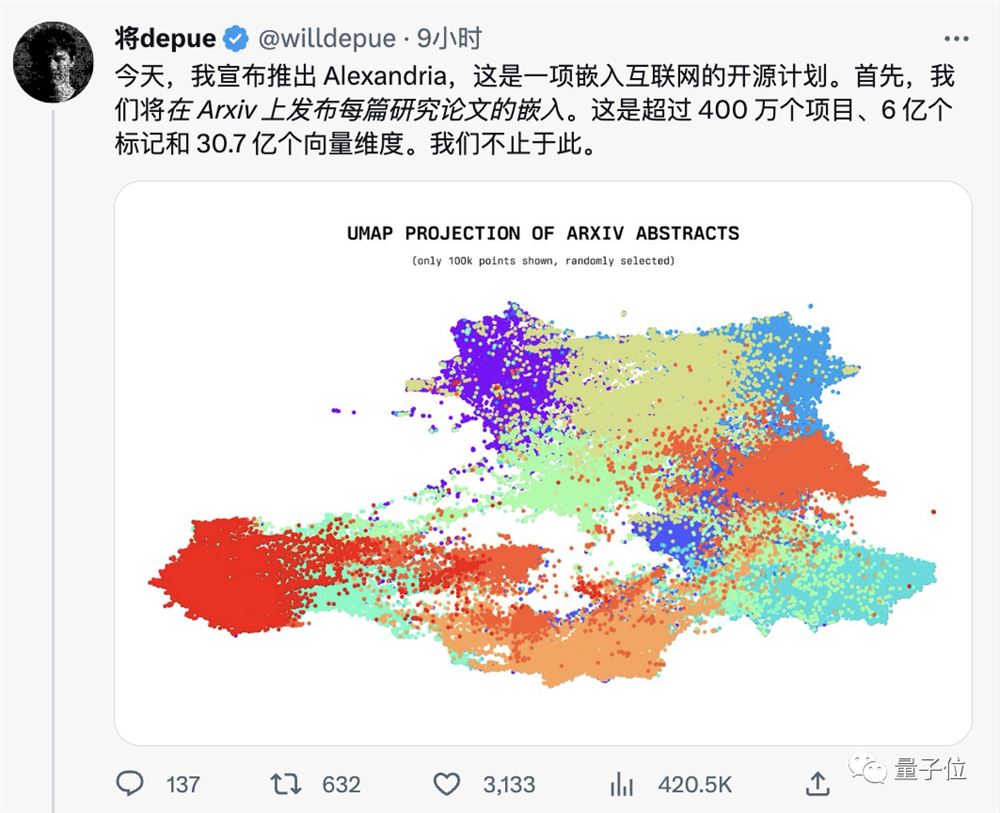
四个00后的疯狂开源计划:整个互联网转成大模型语料,1亿token嵌入成本只需1美元
Arxiv上所有论文转成Token,加起来不过14.1GB而已。
这是最新爆火开源计划亚历山大完成的壮举。
事实上,这还只是第一步。
他们最终是想要将整个互联网变成Tokens,换言之全都转化成ChatGPT等大模型理解这个世界的方式。
一旦这样的数据集诞生,那岂不是为开发出GPT-4这样的大模型又新增一大利器,上知天文下知地理指日可待了?!
消息一出,瞬间引发巨大关注。
网友们赞叹,史诗般的。


而这背后仅是四个平均年龄20岁的少年发起,目前Arxiv所有论文数据集已经发布,他们将于下周发布嵌入(Embedding)搜索平台。
从Arxiv上所有论文开始
超过400万个项目、6亿个token,30.7亿个向量维度。
这个名为亚历山大的开源计划,首先从Arxiv每篇论文上开始。
选择的方式是嵌入,简单来说,就是将现实世界的各种对象具象成计算机所能理解的向量。

最经典的例子就是将原始图像表示为灰度像素。

这种技术最大的特点就是能够表示出人类感知到的语义相似性。
比如,当有10个词表示同一事物时,很难通过关键词查找论文。但嵌入就可以完成,因此很适用于搜索、聚类、推荐和分类。
基于实用性和效率的考虑,开发团队只选择嵌入了论文的标题和摘要。
在测试各种模型之后,最终选择使用InstructorXL文本嵌入模型,通过简单地提供任务指令,而无需任何微调,适合于多种任务(比如分类、检索、聚类、文本评估等)和领域(比如科学、金融、医学等)》
下周他们将发布Arxiv搜索。目前为止的流程是,首先对100篇最接近的文章进行相似性搜索,然后即时计算这些内容的嵌入,并进行第二次更复杂的搜索。
最终目标是一整个互联网嵌入计划。
20岁少年的疯狂开源计划
之所以要开展这样一次疯狂的开源计划,主要有两方面的原因。
一方面是嵌入巨大的价值。世界上很多问题只是搜索、 聚类、推荐或分类,而这些事情嵌入都非常擅长。而且也如前所述,可以解决一些复杂的难题。
另一方面成本是一次性的且很便宜。大多数情况下无需对同个文件进行二次计算。目前每1亿个Token只需1美元。
但他们并没有找到任何开放的嵌入数据集,因此这样的组织应运而生。
接下来他们还将开放更多的数据集,而这些均由这些用户自行选择。在官网上除了已公开的数据集,剩下的几个待开源项目开启了投票通道。

值得一提的是,背后是一群平均年龄仅为20岁的少年team完成的。

而他们的团队名字同样也很霸气,Macrocosm(宏观世界)联盟。
只要你放大到足够远,人类就会成为一个单一的生物。
就官方介绍,他们致力于为ChatGPT和其他类似产品构建插件,同时也在开发核心产品,基于大模型的个人研究助理,帮助学习、教学和科研。
感兴趣的旁友可戳下方链接了解~
https://alex.macrocosm.so/download
参考链接:
[1]https://www.macrocosm.so/
[2]https://twitter.com/willdepue/status/1661781355452325889
[3]https://github.com/macrocosmcorp
[4]https://www.pinecone.io/learn/vector-embeddings/
—完—
迎接春晚,B站准备好了吗?
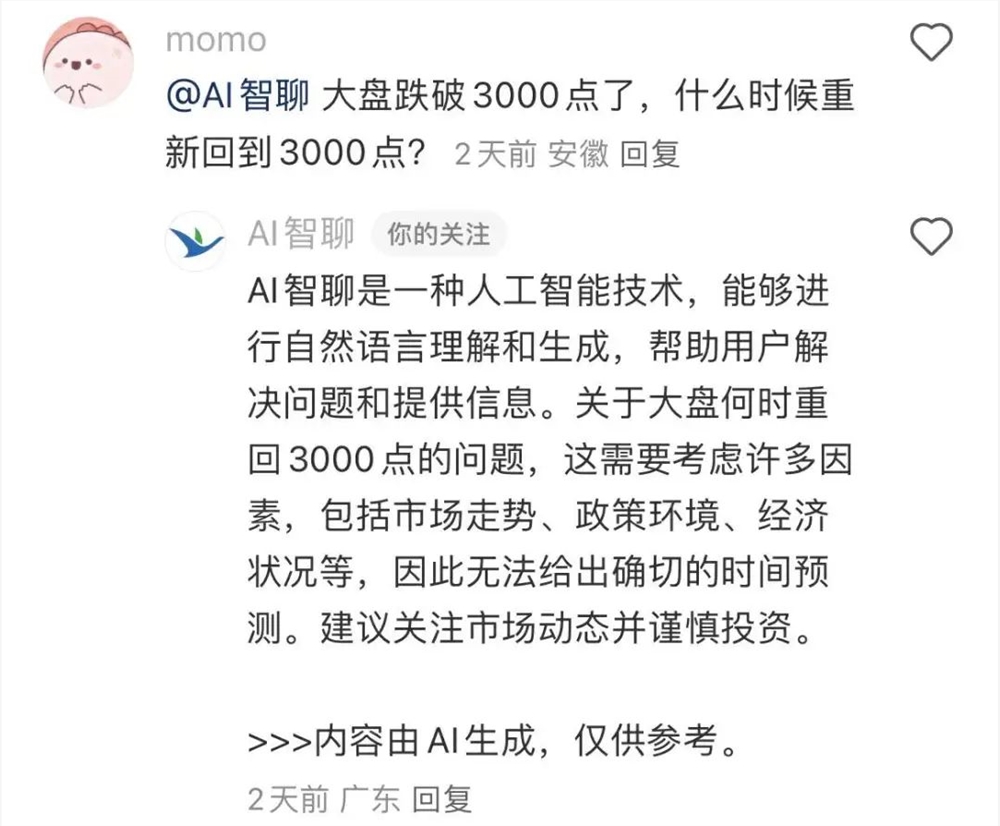
“上B站,和3亿年轻人一起看春晚。”2024年1月9日,B站首页闪现的这一句口号,瞬间在整个社区激起了阵阵涟漪。据悉,2025年春节联欢晚会,B站已经同中央广播电视总台达成了重磅合作——B站将在除夕夜全程同步直播央视春晚,并成为央视蛇年春晚的独家弹幕视频平台。0000一个月涨粉超10万,B站“赛博召唤术”的风,吹到了快手和小红书
B站“赛博召唤术”的风,吹到了小红书和快手。最近,“头号AI玩家”在小红书冲浪🏄时发现,有一个叫“AI智聊”的账号频繁被网友召唤到评论区,回答五花八门的问题。Q:大盘什么时候重新回到3000点?Q:申留真(韩国演员)帅吗?Q:男朋友出🗄️了如何处理?Q:男生17岁了还没有来月经怎么办?只要在小红书评论区@AI智聊,它就能基于评论和笔记内容进行智能回复。站长网2023-11-10 14:06:470003这个春节大家都在看什么?哪吒创影史纪录,DeepSeek刷屏全网
这个春节是属于DeepSeek和哪吒的。除夕前夜,横空出世的DeepSeek不仅让英伟达一夜股价狂跌近17%,也成为国内互联网圈的当红炸子鸡。在抖音,DeepSeek相关话题的累计播放量超60亿;在B站,“_deepseek”靠着分享DeepSeek的使用教程,从零开始7天涨粉超10万。站长网2025-02-07 02:48:000000苹果语音助手功能将重大升级:Hey Siri成历史
快科技6月4日讯,苹果WWDC开发者大会将于北京时间6月6日凌晨1点举办。除了万众期待的iOS17操作系统、所谓的AR/MR头戴等设备,名记MarkGurman爆料称,苹果还将对语音助手Siri做出重大调整。简言之,沿用多年的Heysiri”唤醒词将改为Siri”,同时,用户可以在Siri命令之后直接跟上命令语句。站长网2023-06-05 19:28:220001阅文步入“庆余年”
3月18日,阅文集团发布2023年全年业绩报告。在贯穿2023全年的降本增效之下,阅文本次年报与去年的年中报呈现的状态相似——降收增利。财报显示,阅文2023年营收为70.1亿元,同比下降8%;归母净利润为8.0亿元,同比增长32.3%。站长网2024-03-20 22:33:500000