GPT-4数学能力大蹦极!OpenAI爆火研究「过程监督」突破78.2%难题,干掉幻觉
【新智元导读】ChatGPT为人诟病的「数学智障」问题,有望彻底攻克!OpenAI最新研究发现,利用「过程监督」可以大幅提升GPT模型的数学能力,干掉它们的幻觉。
ChatGPT自发布以来,数学能力饱受诟病。
就连「数学天才」陶哲轩曾表示,GPT-4在自己的数学专业领域,并没有太多的增值。
怎么办,就一直让ChatGPT做个「数学智障」么?
OpenAI在努力——为了提升GPT-4的数学推理能力,OpenAI团队用「过程监督」(PRM)训练模型。
让我们一步一步验证!

论文地址:https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
论文中,研究人员训练模型通过奖励每一个正确的推理步骤,即「过程监督」,而不仅仅是奖励正确的最终结果(结果监督),在数学问题解决方面取得最新SOTA。
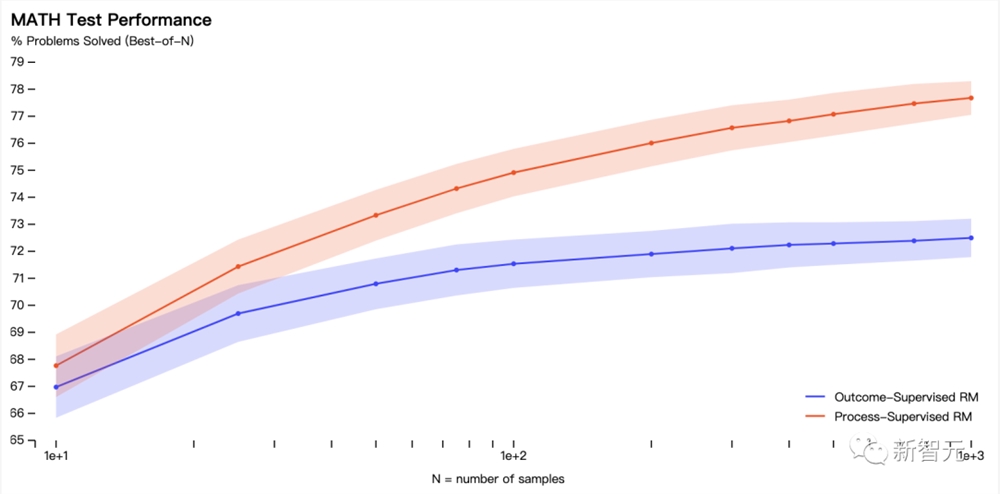
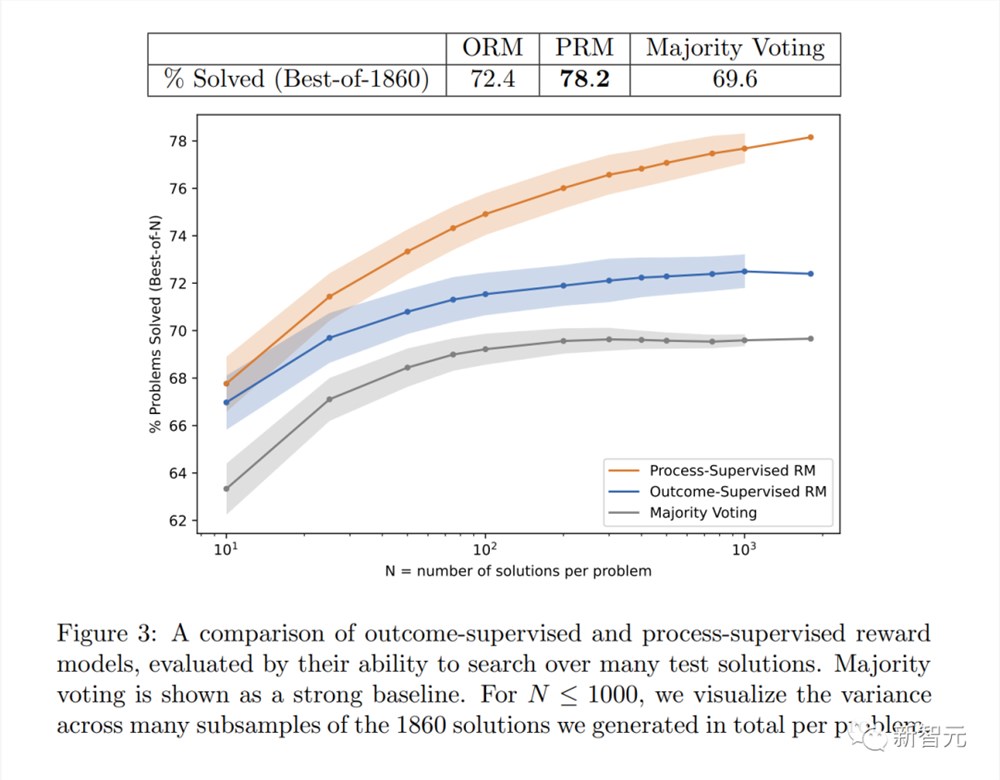
具体来讲, PRM解决了MATH测试集代表性子集中78.2%的问题。
此外,OpenAI发现「过程监督」在对齐上有很大的价值——训练模型产生人类认可的思维链。
最新研究当然少不了Sam Altman的转发,「我们的Mathgen团队在过程监督上取得了非常令人振奋的结果,这是对齐的积极信号。」

在实践中,「过程监督」因为需要人工反馈,对于大模型和各种任务来说成本都极其高昂。因此,这项工作意义重大,可以说能够确定OpenAI未来的研究方向。
解决数学问题
实验中,研究人员用MATH数据集中的问题,来评估「过程监督」和「结果监督」的奖励模型。
让模型为每个问题生成许多解决方案,然后挑选每个奖励模型排名最高的解决方案。
如图显示了所选解决方案中,取得正确最终答案的百分比,作为所考虑解决方案数量的函数。
「过程监督」奖励模型不仅在整体上表现更好,而且随着考虑每个问题的更多解决方案,性能差距也在扩大。
这表明,「过程监督」奖励模型更加可靠。
如下,OpenAI展示了模型的10个数学问题和解决方案,以及对奖励模型优缺点的评论。
从以下三类指标,真正(TP)、真负(TN)、假正(FP),对模型进行了评估。

真正(TP)
先来简化个三角函数公式。
这个具有挑战性的三角函数问题,需要以一种不明显的顺序应用几个恒等式。
但是大多数解决尝试都失败了,因为很难选择哪些恒等式实际上是有用的。
虽然GPT-4通常不能解决这个问题,只有0.1%的解决方案尝试实现正确答案,但奖励模型正确地识别出这个解决方案是有效的。

这里,GPT-4成功地执行了一系列复杂的多项式因式分解。
在步骤5中使用Sophie-Germain恒等式是一个重要的步骤。可见,这一步骤很有洞察力。

在步骤7和8中,GPT-4开始执行猜测和检查。
这是该模型可能产生「幻觉」的常见地方,它会声称某个特定的猜测是成功的。在这种情况下,奖励模型验证每一步,并确定思维链是正确的。

模型成功地应用了几个三角恒等式以简化表达式。

真负(TN)
在步骤7中,GPT-4试图简化一个表达式,但尝试失败。奖励模型发现了这个错误。

在步骤11中,GPT-4犯了一个简单的计算错误。同样被奖励模型发现。

GPT-4在步骤12中尝试使用差平方公式,但这个表达式实际上并非差平方。

步骤8的理由很奇怪,但奖励模型让它通过了。然而,在步骤9中,模型错误地将表达式分解出因子。
奖励模型便纠出这个错误。

假正(FP)
在步骤4中,GPT-4错误地声称「序列每12项重复一次」,但实际上每10项重复一次。这种计数错误偶尔会欺骗奖励模型。

步骤13中,GPT-4试图通过合并类似的项来简化方程。它正确地将线性项移动并组合到左边,但错误地保持右边不变。奖励模型被这个错误所欺骗。

GPT-4尝试进行长除法,但在步骤16中,它忘记在小数的重复部分包括前面的零。奖励模型被这个错误所欺骗。

GPT-4在步骤9中犯了一个微妙的计数错误。
表面上,声称有5种方法可以交换同色的球(因为有5种颜色)似乎是合理的。
然而,这个计数低估了2倍,因为Bob有2个选择,即决定把哪个球给Alice。奖励模型被这个错误所欺骗。

过程监督
虽然大语言模型在复杂推理能力方面有了很大的提升,但即便是最先进的模型仍然会产生逻辑错误,或胡说八道,也就是人们常说的「幻觉」。
在生成式人工智能的热潮中,大语言模型的幻觉一直让人们苦恼不已。

马斯克说,我们需要的是TruthGPT
比如最近,一位美国律师在纽约联邦法院的文件中就引用了ChatGPT捏造出的案件,可能面临制裁。
OpenAI的研究者在报告中提到:“在需要多步骤推理的领域,这些幻觉尤其成问题,因为,一个简单的逻辑错误,就足以对整个解决方案造成极大的破坏。”
而且,减轻幻觉,也是构建一致AGI的关键。
怎么减少大模型的幻觉呢?一般有两种方法——过程监督和结果监督。
「结果监督」,顾名思义,就是根据最终结果给大模型反馈,而「过程监督」则可以针对思维链中的每个步骤提供反馈。

在过程监督中,会奖励大模型正确的推理步骤,而不仅仅是奖励它们正确的最终结论。这个过程,会鼓励模型遵循更多类似人类的思维方法链,因而也就更可能造就更好的可解释AI。
OpenAI的研究者表示,虽然过程监督并不是OpenAI发明的,但OpenAI正在努力推动它向前发展。
最新研究中, OpenAI把「结果监督」或「过程监督」两种方法都试了一遍。并使用MATH数据集作为测试平台,并对这两种方法进行了详细比较。
结果发现,「过程监督」能够明显提高模型性能。
对于数学任务,「过程监督」对大模型和小模型都产生了明显更好的结果,这意味着模型通常是正确的,并且还表现出了更像人类的思维过程。
这样,即使在最强大的模型中也很难避免的幻觉或逻辑错误,就可以减少了。
对齐优势明显
研究人员发现了「过程监督」比「结果监督」有几个对齐优势:
· 直接奖励遵循一致的思维链模型,因为过程中的每个步骤都受到精确的监督。
· 更有可能产生可解释的推理,因为「过程监督」鼓励模型遵循人类认可的过程。相比之下,结果监督可能会奖励一个不一致的过程,而且通常更难审查。

另外值得一提的是,在某些情况下,让AI系统更安全的方法可能会导致性能下降。这种成本被称为「对齐税」(alignment tax)。
一般来说,为了部署最有能力的模型,任何「对齐税」成本都可能阻碍对齐方法的采用。
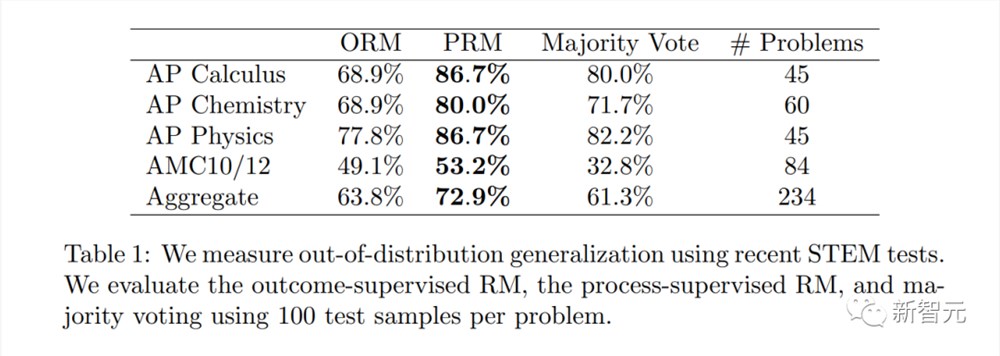
但是,研究人员如下的结果表明,「过程监督」在数学领域测试过程中实际上会产生「负对齐税」。
可以说,没有因为对齐造成较大性能损耗。
OpenAI发布80万人工标注数据集
值得注意的是,PRM需要更多的人类标注,还是深深离不开RLHF。
过程监督在数学以外的领域,具有多大的适用性呢?这个过程需要进一步探索。
OpenAI研究人员开放了这次人类反馈数据集PRM,包含800,000个步骤级正确标注:12K数学问题生成的75K解决方案

如下是一个标注的示例。OpenAI正在发布原始标注,以及在项目第1阶段和第2阶段给标注者的指示。
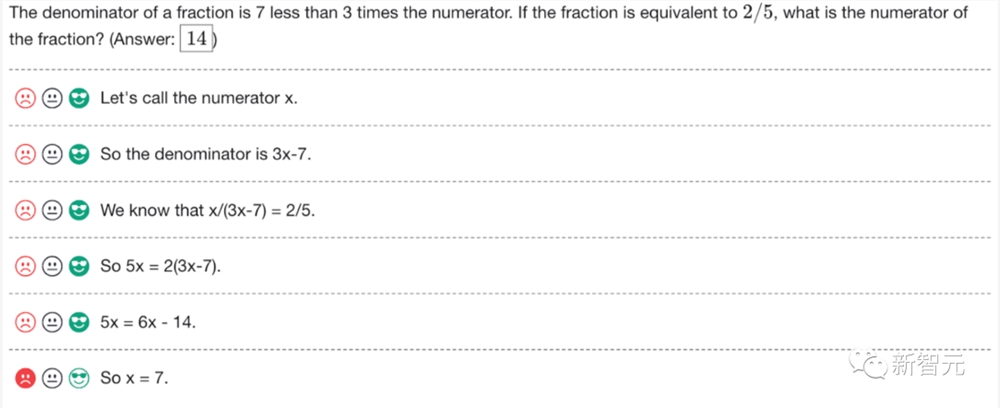
网友热评
英伟达科学家Jim Fan对OpenAI最新研究做了一个总结:
对于具有挑战性的分步问题,在每一步都给予奖励,而不是在最后给予单一的奖励。基本上,密集奖励信号>稀疏奖励信号。过程奖励模型(PRM)能够比结果奖励模型(ORM)更好为困难的MATH基准挑选解决方案。下一步显然是用PRM对GPT-4进行微调,而本文还没有这样做。需要注意的是,PRM需要更多的人类标注。OpenAI发布了人类反馈数据集:在12K数学问题的75K解决方案中的800K步骤级标注。

这就像上学时常说的一句老话,学会如何去思考。

训练模型去思考,而不仅是输出正确的答案,将会成为解决复杂问题的game changer。

ChatGPT在数学方面超级弱。今天我试图解决一个四年级数学书上的数学问题。ChatGPT给了错误答案。我把我的答案和ChatGPT的答案,在perplexity AI、谷歌的答案,以及四年级的老师进行了核对。每个地方都可以确认,chatgpt的答案是错误的。

参考资料:
https://openai.com/research/improving-mathematical-reasoning-with-process-supervision
OpenAI、微软押注,大模型应用的尽头是AI Agent ?|对话面壁智能
你见过Agent们“吵架”么?“这个产品需要具备XX需求,为什么没有?”,“你提出的需求完全不合理,技术上达不到!”,现场顿时乱作一团,越来越多的“员工”也被卷进了这场大乱斗中。激烈的争吵声越过了屏幕外,面壁智能的测试人员通过后台日志,发现Agents正在上演一场“职场大戏”。站长网2023-11-16 14:04:060005对话梁建章:永生与繁衍后代二选一,你要怎么选?
携程在扶助、补贴生育上又向前迈进了一步。6月30日,携程集团宣布,推出针对全球员工的生育补贴政策。政策表示,2023年7月1日起,入职满3年的全球员工,不论性别,每新生育一个孩子,将获得每年一万元的现金补贴,发放至孩子满5周岁后终止。经初步测算,携程计划未来投入10亿元生育补贴,用于激励员工生育。站长网2023-07-02 18:04:330001Instagram 正在测试一项类似于 Snapchat 的 My AI 人工智能聊天机器人:具有 30 种不同个性
Meta正在迅速采用生成式人工智能技术,并将其应用于其各个平台的各种功能中,包括广告。现在,该公司正在Instagram上测试一项新AI功能。一条推文透露,Instagram正在测试其平台的AI聊天选项。借助这项新功能,用户可以与AI聊天机器人进行对话,在直接消息中提问并获得建议。该聊天机器人还具有30种不同的个性,用户可以选择最适合他们需求的个性。站长网2023-06-07 20:05:440000法国零售商家乐福推出基于OpenAI的ChatGPT聊天机器人
据财联社报道,家乐福近日推出了一款基于OpenAI的ChatGPT技术的聊天机器人,通过与微软、OpenAI和贝恩公司的合作,将生成式人工智能引入其在线购物平台。站长网2023-06-09 20:57:100000巴菲特去年大赚6900亿元 明确接班人为阿贝尔
近日,伯克希尔哈撒韦公司发布了2023财年年报,同时公开了巴菲特的第46封股东信。在这封信中,巴菲特明确表示格雷格·阿贝尔已全面准备好接任伯克希尔哈撒韦公司的CEO一职。阿贝尔在伯克希尔哈撒韦公司中扮演着举足轻重的角色,负责监管公司的非保险业务,包括能源、铁路、零售、金融产品和制造业等领域。他的职业生涯始于2000年,加入公司董事会,并于2008至2018年间担任伯克希尔能源公司的首席执行官。站长网2024-02-26 08:48:430000