又一个!北京智源推出通用视觉分割模型SegGPT
在2023中关村论坛平行论坛之一的人工智能大模型发展论坛上,北京智源人工智能研究院推出通用分割模型 SegGPT(Segment Everything In Contex),这是一个利用视觉提示(prompt)完成任意分割任务的通用视觉模型。
SegGPT 是智源通用视觉模型 Painter 的衍生模型,可针对分割一切物体的目标做出优化。
该模型具备上下文推理能力,训练完成后无需微调,只需提供示例即可自动推理并完成对应分割任务,包括图像和视频中的实例、类别、零部件、轮廓、文本、人脸、医学图像等。
如下图所示,标注出一个画面中的彩虹,SegGPT可批量化分割其他画面中的彩虹。

它的灵活推理能力支持任意数量的视觉提示。自动视频分割和追踪能力以第一帧图像和对应的物体掩码作为上下文示例,SegGPT 能够自动对后续视频帧进行分割,并且可以用掩码的颜色作为物体的ID,实现自动追踪。
值得一提的是,此前Meta发布了其新的基于 AI 的 Segment Anything Model (SAM) ,该模型具有识别和分离图像和视频中的特定对象的功能。通过使用SAM,用户可以通过点击物体或输入文字提示选中编辑的物体。
威斯康辛麦迪逊、微软、港科大等机构的研究人员也提出SEEM模型,通过不同的视觉提示和语言提示,一键分割图像、视频。SEEM模型是一种新型的分割模型,这一模型可以在没有提示的开放集中执行任何分割任务,比如语义分割、实例分割和全景分割。
另外,南科大发布视频分割模型TAM,可轻松追踪视频中的任意物体并消除,操作简单友好。TAM的出现为解决传统视频分割模型需要人工标记培训数据和初始化参与数据的问题提供了之前提供,将改变CGI行业的游戏游戏规则。
SegGPT相关代码发布在 GitHub 上,论文发表在预印本平台 arXiv 上。论文地址:https://arxiv.org/abs/2304.03284
今年全球最大规模 IPO 或将诞生,芯片巨头 Arm 正式提交上市申请!
8月21日,软银旗下的Arm公司在纳斯达克股票市场申请首次公开募股(IPO),股票代码为ARM。与此同时,这家英国芯片设计公司还公布了定于下月初在纳斯达克上市的初步招股说明书,也成为众人关注的焦点。成立33年的Arm公司,设计了99%的智能手机中的芯片架构站长网2023-08-22 18:50:330000小米申请“汽车超级工厂”“泰坦合金”等商标
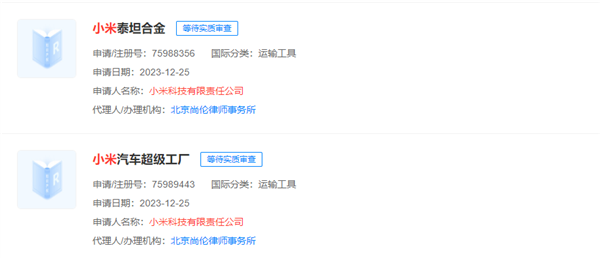
小米科技有限责任公司近日在多个领域申请注册了中英文商标,其中包括“小米泰坦”、“小米泰坦合金”、“小米超级电机”、“小米汽车超级工厂”和“小米EV超级工厂”等。这些商标的注册申请涵盖了运输工具、金属材料和建筑修理等领域,但目前商标状态为等待实质审查。据悉,小米已建成并投产了9100吨大压铸工厂,拥有整套压铸岛流水线,60台设备,并自研了大压铸材料,即小米泰坦合金。站长网2024-01-15 16:04:510001内部员工称苹果AI至少落后2年:ChatGPT准确率比Siri高出约25%
在最新一期的PowerOn节目中,MarkGurman透露,苹果公司内部员工普遍认为,苹果在人工智能领域的发展落后于行业领导者大约两年时间。苹果的内部研究显示,与苹果的Siri相比,ChatGPT的准确率要高出大约25%,并且能够回答的问题也多出约30%。0000双11 0元领礼品是假的!小米辟谣这种提货卡:压根没这活动
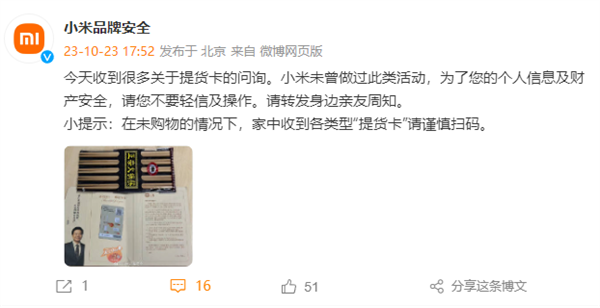
快科技10月23日消息,又是一年一度的双11电商节,很多厂商会在此期间推出各种优惠活动。不过,大家购物的同时也要当心骗子的套路”。今日,小米品牌安全”官微发文,称收到很多关于提货卡的问询,小米未曾做过此类活动。为了大家的个人信息及财产安全,请不要轻信及操作。官方提醒,在未购物的情况下,家中收到各类型提货卡”请谨慎扫码。站长网2023-10-24 21:23:020002百度Apollo展示AI智能座舱 引入文心大模型
5月23日,百度Apollo汽车智能化业务展示了以文心大模型为基础的新一代AI智舱探索成果。据悉,这是国内首个大模型在汽车行业应用的成果探索,有望在未来推进量产。基于文心大模型能力探索下,智舱将具备出行场景对话式交互、逻辑推理、策略规划和知识问答等多项能力,同时也展示了在当前智舱命令式交互下覆盖全车多音区、毫秒级响应、免唤醒全时交互的极致体验。站长网2023-05-24 08:53:460000