突破算力限制!Meta开源“记忆层”,重塑Transformer架构大模型
今天凌晨3点,全球社交巨头Meta分享了一个创新研究——Memory layers(记忆层)。
目前,Transformer架构的预训练大模型在存储、查询数据时,随着参数的变大对算力的需求呈指数级增长。“记忆层”提出了新的高效查询机制替代了传统的查询方法,通过比较查询键与两个较小集合中的键,可以快速找到最相关的键,而无需遍历模型的整个记忆层。
这也就是说,可以在不增加算力的情况下显著增加大模型的参数。例如,研究人员在仅有1.3亿参数的模型中添加了128亿额外的记忆参数,其性能与Meta开源的Llama2-70相当,而算力却比它低了10倍左右。
开源地址:https://github.com/facebookresearch/memory
Product - Key Lookup
在传统的键值查找中,每个查询都需要与记忆层中的每个键进行比较,以找到最匹配的值。该方法在键的数量较少时是可行的,但随着记忆层规模的增长,这种暴力搜索的方式变得非常低效,需要消耗巨大算力和时间。
给大家举一个简单的例子,你想在一个巨大的图书馆里找一本书。这个图书馆有成千上万本书,每本书都有一个唯一的编号(相当于记忆层中的“键”)。如果你要找到一本特定的书(相当于查询),传统的方法是逐个检查每一本书的编号来查找你要的那一本。
这种方法在图书馆只有几百本本书时可能还行得通,当图书馆藏书量达到数万时,逐本查找方法就变得极其耗时和低效了。

Product - Key Lookup是“记忆层”的核心算法之一,使用了一种分而治之的策略,将传统的单一键集合分解为两个较小的键集合,通过两个阶段的查找来减少必要的比较次数,从而提高查找效率。
首先,查询键被分割为两个子查询,每个子查询分别与两个半键集合进行比较。由于每个半键集合的大小只有原始键集合的平方根大小,因此这个阶段的计算量大幅减少。在第一阶段,每个半键集合中找到与子查询最相似的k个键,这个过程称为top-k查找。
在第二阶段,两个半键集合中找到的top-k键被合并,以确定最终的top-k键。这一步骤涉及到对两个半键集合中找到的键进行综合评分,以确定它们与原始查询键的整体相似度。需要考虑到两个半键集合中的键的组合,以找到最佳的匹配。
除了计算效率之外,Product-Key Lookup模块还优化了内存和带宽的使用。由于每个GPU只需要处理一半的键,因此内存的使用量减少了一半。由于每个GPU只需要返回与自己处理的键相关的值,所以内存带宽的需求也得到了优化。
Product-Key Lookup算法不仅提高了记忆层的查询效率,还为记忆层的应用开辟了新的可能性,使得记忆层可以被应用于更大规模的数据集和更复杂的任务中,包括大规模知识图谱的查询、长文本的语义检索等。
并行记忆层和共享记忆参数
并行记忆层主要是用于对硬件GPU的优化。在传统的Transformer架构模型中,随着模型规模的增加,计算和内存需求也随之增长。特别是在处理大规模数据集时,单一的计算单元很难满足这种需求。并行记忆层通过在多个GPU之间分配任务,有效解决这一难题。
在并行记忆层的设计中,每个计算单元只负责处理一部分数据,这样可以减少单个计算单元的负担,同时提高整体的处理速度。这种设计允许模型在保持单个计算单元负载合理的同时,处理更大规模的记忆层。使得模型可以扩展到数十亿甚至数百亿的参数,而不会受到单个计算单元性能的限制。
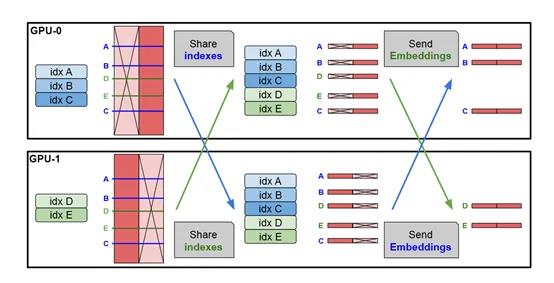
共享记忆参数则是另外一个重要优化方法,允许不同层的记忆层共享同一个参数集合。这种设计的优势在于,它减少了模型的总参数数量,同时提高了参数的利用率。
当一个记忆层接收到输入后,它会先从共享记忆池中查找最相似的记忆单元,然后根据查询结果生成输出。由于所有记忆层都指向同一个记忆池,因此它们可以在不影响彼此的情况下同时进行操作。
为了应对训练期间可能出现的变化,研究人员开发了一套动态调整策略。每当有新的键加入或旧有的键被更新时,系统会自动调整相应的子集,而无需对整个记忆池进行全面改造。这样的设计既简化了维护流程,又提高了系统的灵活性和适应性。
?签约OR孵化,MCN机构该如何平衡商业效率?
在刚刚过去的4月,由克劳锐出品的《2023中国内容机构(MCN)行业发展研究白皮书》重磅发布,白皮书在引发业内热议的同时也为中国MCN机构的发展给出了可能的方向。在白皮书发布后,克劳锐以“实现增长,路在何方”为主题发起系列直播,通过对话MCN机构创始人,探讨MCN机构们当前关注的重点行业问题。0000“日日新大模型”亮相奥运会,商汤科技AI应用成色几何?
AI技术对于商业模式未通的商汤科技而言,此番奔赴奥运赛场,或许只是追追热点、提升品牌知名度,而其应用场景落地与商业化进程,恐怕不会带来实质性的改变。AI黑科技加持的2024年巴黎奥运会,浪漫而时髦。各大模型厂商,也在趁着热点,在赛场内外秀肌肉、疯狂内卷。0000硬拼iPhone 15!华为Mate60系列全线缺货 消息称Pro系列出货量上调至2千万台
快科技9月14日消息,华为现在正在紧急生产Mate60系列,因为真的是太抢手了。今天早些时候我们报道称,富士康龙华做华为等手机品牌订单的富士康ACKN部门(现为FIH部门)还在高价招人,9月12日公布的小时工时薪26元。除做手机摄像头、需穿防尘服的WWW事业群外,这是富士康龙华目前最高薪招人的部门。0000360智脑-视觉大模型发布 周鸿祎:多模态大模型与物联网结合是风口
站长之家(ChinaZ.com)6月1日消息:周鸿祎在5月31日晚间的三六零智慧生活集团视觉大模型及AI硬件新品发布会上,发布了专业视觉及多模态大模型“360智脑-视觉大模型”。360智脑视觉大模型基于10亿级互联网图文数据进行清洗训练,并针对安防行业数据进行微调,融合千亿参数的"360智脑"大模型,从视觉感知能力角度进行打造。站长网2023-06-01 16:39:400000苹果全新iPhone首发3nm自研芯片,结果“华为发布会”冲上热搜第一…
就离谱!苹果发iPhone15,结果发着发着“华为发布会”冲上了热搜第一???哪怕是iPhone15全系告别11年闪电接口改用USB-C、经典静音键从Pro系列消失,这些库克“违背祖宗的决定”,都没抢到更多热度。网友们第一时间倒是吐槽吐出了花儿,社交媒体上一时间充满快活的气息。belike,iPhone15Pro采用了男士内裤配色。站长网2023-09-13 09:39:370000