OpenAI放王炸,Sora无限使用!3大新功能,2024最大惊喜!
今天凌晨2点,OpenAI开启了第三天技术直播,正式发布了期待已久的产品——Sora Turbo。
与早期版本相比,Turbo的生成效率更快,能通过文本直接生成最多20秒1080P视频,这是目前全球生成时长最高的视频模型之一,同时支持文本 图片/视频,生成特定视频内容,使得模型的生成效果更加可控。
例如,你想在一段普通的视频中加上梵高《星夜》的效果,只需要上传原视频然后用文本描述就能轻松实现。也就是说,即便你不会使用AE、Nuke、C4D等专业视频软件,通过Sora也能为视频轻松添加特效了。
目前,Sora已经正式进入使用阶段没有任何限制,最让人惊喜的是ChatGPT Plus和Pro会员无需额外费用就能使用,这么良心是万万没想到的。
OpenAI为了更好的让用户使用Sora还开发了全新UI,同时提供社区分享服务,用户可以把自己生成的视频分享给其他人,或者借鉴其他人的提示效果来完善自己作品。
知名艺术家Emi Kusano通过Sora制作了一个怀旧的日式舞蹈风格视频。虽然还存在一些瑕疵,但整个视频里的人数、颜色复杂程度、物理模拟、场景融合都表现出了非常好的效果。
Emi表示,Sora最神奇的是,可以让她很多只存在脑海中的概念、抽象场景成为了现实,同时在生成的过程中又创造了很多意想不到的场景,帮助她打开了新的创作思路。
一个机器人走在一个赛博朋克风格的街道。
一个充满鲸鱼、鲨鱼的海洋世界。
一只变色龙变成了孔雀。
Sam Altman曾兴奋的说过,今天将是一场非常炸裂的产品发布会。雪藏10个月的Sora终于与大家见面了,没有辜负期望依然是那个能打的王者,2024年生成式AI领域最大惊喜非它莫属。
Sora技术原理简单介绍
Sora的核心技术之一便是对Patch的应用。它允许Sora在大量的图像和视频数据上进行密集训练。从每一个存在的视频中剪出的Patch,可以被堆叠起来并输入到模型中。
这种基于Patch而非视频全帧的训练方式,使得Sora能够处理任何大小的视频或图片,无需进行裁剪。这不仅增加了用于训练的数据量,也提高了输出质量。
为了进一步提升效率和效果,Sora采用了视频压缩网络,这是一种专门设计用来降低视觉数据维度的神经网络。通过该网络,原始视频被转换成一个在时间和空间上都经过压缩的潜在表示。Sora在这个压缩后的潜在空间内接受训练,并学习如何生成新的视频内容。同时,还训练了一个解码器模型,用于将生成的潜在表示映射回像素空间,恢复为可视化的视频帧。
对于时空潜伏斑块,在获取压缩输入视频后,OpenAI 从中提取出一系列时空 Patch 作为转换标记。基于这种 Patch 表示法,Sora 得以在各类视频和图像数据上进行训练,无论是不同分辨率、时长还是长宽比的素材都能轻松应对。在推理阶段,通过在适宜大小的网格中合理排列随机初始化的 Patch,便能精准控制生成视频的尺寸规格。
在模型架构设计方面,Sora 巧妙地融合了扩散模型与 Transformer 架构。这种融合方式达成了高效且高质量的视频内容生成效果。
同时,Sora 采用创新的扩散式转换器方法,取代了传统的U - Net 架构,这一举措有效提升了对输入图像与文本标签之间分布关系的捕捉能力。Sora 还运用描述性合成描述符展开训练,这些描述符对于模拟现实场景以及规划未来行动发挥重要作用。
由于训练视频模型对大量带有相应字幕的视频有着强烈需求,OpenAI 将 DALL・E3的重新字幕技术引入到 Sora 体系之中。
首先训练出一个具备高度描述性的字幕模型,接着利用该模型为训练集中的所有视频创建文本字幕。OpenAI 坚信,在这种高度描述性的视频字幕基础上开展训练,能够有效提升文本的保真度以及视频的整体质量。
与 DALL - E3类似,OpenAI 借助 GPT 将简短的用户提示转换为篇幅更长且内容详细的字幕信息,然后将其传输给视频模型。通过这一系列技术手段的协同运作,Sora 能够精准地依据用户的文本提示,生成高质量的长视频内容。
目前,Sora已经启用了全新域名https://sora.com/ 可以制作各种视频了。
网信办发布关于加强自媒体管理的通知 加大对MCN机构管理力度
今日,中央网信办发布《关于加强“自媒体”管理的通知》提出,加大对“自媒体”所属MCN机构管理力度。通知称,网站平台应当健全MCN机构管理制度,对MCN机构及其签约账号实行集中统一管理。在“自媒体”账号主页,以显著方式展示该账号所属MCN机构名称。对于利用签约账号联动炒作、多次出现违规行为的MCN机构,网站平台应当采取暂停营利权限、限制提供服务、入驻清退等处置措施。以下为具体内容:站长网2023-07-10 17:07:030000特斯拉Cybertruck开启国内首次直播 即将启动全国巡展
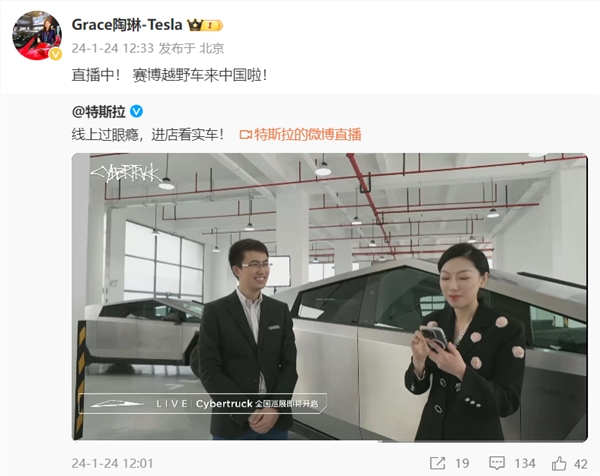
站长之家(ChinaZ.com)1月24日消息:特斯拉旗下纯电皮卡Cybertruck已空运至国内,准备启动全国巡展。在正式巡展之前,特斯拉决定通过直播让网友提前一睹Cybertruck的风采。根据特斯拉官方信息,Cybertruck的直播将在三个时间段进行,分别是12:00-14:00、15:00-17:00和18:00-20:00。网友可以通过直播链接观看Cybertruck的详细介绍。站长网2024-01-24 15:01:010000从肌肉猛男到科目三,最卷的赛道整出了最好的活
回看2023年的营销热点,食品饮料品牌和餐饮行业依然占据了最多的出圈镜头。去年年底,“科目三”这个原本专属于驾考的考试科目,“莫名其妙”地变成了一种“广西社会摇”和“东北摇花手”的魔性舞蹈。在广泛流传的互联网调侃中,广西人的“科目一”是唱山歌,“科目二”是嗦粉,“科目三”就是摇花手。如今“科目三”的流行,很难不让人怀疑,再过二十年,广西地区的民族舞是否会有“科目三”的一席之地。站长网2024-02-02 13:58:190001美团上线剧场频道,内容能否建立“护城河”?
近日,美团App短视频界面再次升级,新增了剧场频道。用户进入该频道后,会看到电影以及电视剧解说内容,博主们会将一部影视作品分成多集进行讲解。经过本次改版,美团短视频界面被划分为关注、本地、剧场以及推荐四个板块。美团为何会在短视频界面单独推出剧场板块?通过不断加码短视频和直播,美团的内容化战略成效几何?美团能否守住本地生活老大哥的地位?美团加码短视频,意在用户留存站长网2024-03-19 19:48:080000Stack Overflow 网站因 ChatGPT 人工智能崛起而裁员 28% 员工
站长之家(ChinaZ.com)10月17日消息:StackOverflow的网站帮助软件工程师获得技术问题的答案,根据首席执行官PrashanthChandrasekar周一发布的博客文章,该网站已解雇了约28%的员工。图片来自StackOverflow此举可能是迄今为止OpenAI的ChatGPT(也为同类问题提供答案)如何颠覆数字业务的最有力迹象。站长网2023-10-18 21:18:040001