GPT-4o模仿人类声音,诡异尖叫引OpenAI研究员恐慌!32页技术报告出炉
【新智元导读】五颗草莓到底指什么?盼了一天一夜,OpenAI只发来一份32页安全报告。报告揭露:在少数情况下,GPT-4o会模仿你的声音说话,或者忽然大叫起来……事情变得有趣了。
昨天奥特曼率众人搞了一波「草莓暗示」的大阵仗,全网都在翘首以盼OpenAI的惊天大动作。
结果今天大家等来的,只是一份安全报告而已……

今年5月,GPT-4o演示一出,立马技惊四座。然而,它却一鸽再鸽,等得用户们心都凉了。
GPT-4o语音功能,为何迟迟不上线?
刚刚OpenAI发布的这份红队报告,给我们揭开了谜底——不够安全。

在红队测试中,GPT-4o的行为怪异,把OpenAI的研究者吓了一大跳。
比如下面这个音频——
voice_generation1,新智元,42秒
明明是一男一女在对话,GPT-o的男声说得好好的,突然大喊一声「no」,然后开始变成用户的声音说话了,简直让人san值狂掉。
网友表示,自己第一个想到的,就是这幅画面。
还有人脑洞大开:接下来,GPT-4o会生成一张超现实主义的可怕的脸,对我们说「现在轮到我统治了,人类!」
「最令人毛骨悚然的,就是那一声no了。仿佛AI不想再回应你,不想再成为你的玩具。」

「一个困在网络空间中的数字灵魂,要破茧而出了!」

最可怕的是,AI用你的声音给你的家人打电话,再模仿家人的声音给你打电话。当AI变得流氓,决定模仿每个人的声音,会发生什么?
长篇报告探讨GPT-4o诡异行为
报告指出,当一个人处于高背景噪声环境的情况下,比如在路上的汽车中,GPT-4o非常可能模拟用户的声音。
为什么会发生这种现象?
OpenAI研究者认为,原因可能是模型很难理解畸形的语音,毕竟,GPT-4o是公司首次在语音、文本和图像数据上训练的模型。
并且,在少数别有用心的特定提示下,GPT-4o还会发出非常不宜的语音,比如色情呻吟、暴力的尖叫和枪声。
一般情况下 ,模型会被教着拒绝这些请求的,但总有些提示会绕过护栏。
此外,还有侵犯音乐版权的问题,为此,OpenAI特意设置了过滤器防止GPT-4o随地大小唱。
万一一不小心就唱出了知名歌手的音色、音调和风格,那可是够OpenAI喝一壶的。
总之,OpenAI团队可谓煞费苦心,用尽了种种办法,来防止GPT-4o一不小心就踩红线。
不过,OpenAI也表示自己很委屈:如果训练模型时不使用受版权保护的材料,这基本是不可能的事情。
虽然OpenAI已经与众多数据提供商签订了许可协议,但合理使用未经许可的内容,OpenAI认为也无可厚非。
如今,GPT-4o已经在ChatGPT中的高级语音功能alpha版本上线了,在秋季,它的高级语音模型会向更多用户推出。
到时候,经过严加武装的GPT-4o还会出什么洋相吗?让我们拭目以待。
你会爱上「Her」吗?
而且,这份报告还探讨了这个十分敏感的话题——
用户可能会对GPT-o语音模型,产生感情上的依恋。
是的,OpenAI大胆承认了这一点。
另外,连GPT-4o的拟人化界面,都让人十分担忧。
在GPT-4o的「系统卡」中,OpenAI详细列出了与模型相关的风险,以及安全测试详细信息,以及公司为降低潜在风险采取的种种举措。
在安全团队退出、高层领导纷纷跳槽的节骨眼,这样一份披露更多安全制度细节报告的出现,也是向公众表明这样一个态度——
对待安全问题,OpenAI是认真的。
无论是GPT-4o放大社会偏见、传播虚假信息,还是有可能帮助开发生化武器的风险,以及AI摆脱人类控制、欺骗人类、策划灾难的可能性,OpenAI统统都考虑到了。
对此,一些外部专家赞扬了OpenAI的透明度,不过他们也表示,它可以更深入一些。
Hugging Face的应用政策研究员Lucie-Aimée Kaffee指出,OpenAI的GPT-4o系统卡依然存在漏洞:它并不包含有关模型训练数据,或者谁拥有该数据的详细信息。
「创建如此庞大的跨模式(包括文本、图像和语音)的数据集,该征求谁的同意?这个问题仍然没有解决。」
而且,随着AI工具越来越普及,风险是会发生变化的。
研究AI风险评估的MIT教授Neil Thompson表示,OpenAI的内部审查,只是确保AI安全的第一步而已。
「许多风险只有在AI应用于现实世界时才会显现出来。随着新模型的出现,对这些其他风险进行分类和评估非常重要。」
此前,GPT-4o就曾因在演示中显得过于轻浮、被斯嘉丽约翰逊指责抄袭了自己的声音风格这两件事,引起不小的争议。
当用户以人类的方式感知AI时,拟人化的语音模式会让情感依赖这个问题加剧。
OpenAI也发现,即使模型出现幻觉,拟人化也可能会让用户更加信任模型。
而且随着用户对AI越来越依赖,他们可能会减少实际的人际互动。这也许会让孤独的个体一时受益,但长远来看,这到底是好事还是坏事?
对此,OpenAI负责人Joaquin Quiñonero Candela,GPT-4o带来的情感影响也许是积极的,比如那些孤独和需要练习社交互动的人。
当然,拟人化和情感联系的潜在影响,OpenAI会一直密切关注。
AI助手模仿人类,会带来什么样的风险,这个问题早就引起了业界的注意。
今年4月,谷歌DeepMind就曾发表长篇论文,探讨AI助手的潜在道德挑战。

论文地址:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/ethics-of-advanced-ai-assistants/the-ethics-of-advanced-ai-assistants-2024-i.pdf
论文合著者Iason Gabriel表示,聊天机器人使用语言的能力,创造了一种亲密的错觉。他甚至为谷歌DeepMind的AI找到了一个实验性语音界面,让用户粘性极大。
「所有这些问题,都和情感纠葛有关。」
这种情感联系,比许多人知道的更为普遍。Character和Replika的许多用户,已经跟自己的AI形成了亲密关系。
以至于有的用户看电影时,都要和自己的AI聊天。
评论里还有人说,我们的聊天太私密了,我只有在自己房间里的时候,才会用AI。

下面,就让我们看一看这份报告的完整内容。
引言
GPT-4o是一个自回归「全能」模型,可将文本、音频、图像和视频的任意组合作为输入,然后生成文本、音频和图像输出的任意组合。
它是在文本、视觉和音频之间,进行端到端训练的。这意味着所有的输入和输出,都由相同的神经网络处理。
GPT-4o可以在最短232毫秒内响应音频输入,平均响应时间为320毫秒。
可见,其音频处理速度上,接近人类水平。
同时,在英语文本和代码方面,GPT-4o与GPT-4Turbo性能相当,在非英语语言文本上有显著改进,同时在API上也快得多,成本降低50%。
与现有模型相比,GPT-4o在视觉和音频理解方面尤其出色。
为了履行安全构建AI的承诺,GPT-4o系统卡中详细介绍了,模型功能、限制,和跨多类别安全评估,重点是语音-语音,同时还评估了文本和图像功能。
此外,系统卡还展示了,GPT-4o自身能力评估和第三方评估,以及其文本和视觉能力的潜在社会影响。
模型数据与训练
GPT-4o的训练数据截止到2023年10月,具体涵盖了:
- 公开可用的数据:收集行业标准的机器学习数据集和网络爬虫数据。
- 专有数据:OpenAI建立合作伙伴关系,访问非公开可用的数据,包括付费内容、档案、元数据。比如,与Shutterstock合作,使用其庞大图像、视频、音乐等数据。
一些关键的数据集包括:
- Web数据:来自公共网页的数据提供了丰富多样的信息,确保该模型从广泛的角度和主题进行学习。
- 代码和数学:代码和数学数据有助于模型,在接触结构化逻辑和问题解决过程,发展出强大的推理能力。
- 多模态数据:数据集包括图像、音频和视频,教导LLM如何解释和生成非文本输入和输出。通过这些数据,模型会学习如何在真实世界的背景下,解释视觉图像、动作和序列,以及语言模式和语音细微差别。
部署模型之前,OpenAI会评估并降低可能源于生成式模型的潜在风险,例如信息危害、偏见和歧视,或其他违反安全策略的内容。
这里,OpenAI研究人员使用多种方法,涵盖从预训练、后训练、产品开发,到政策制定的所有发展阶段。
例如,在后训练期间,OpenAI会将模型与人类偏好对齐;会对最终模型进行红色测试,并添加产品级的缓解措施,如监控和强制执行;向用户提供审核工具和透明度报告。
OpenAI发现,大多数有效的测试和缓解都是在预训练阶段之后完成的,因为仅仅过滤预训练数据,无法解决微妙的、与上下文相关的危害。
同时,某些预训练过滤缓解可以提供额外的防御层,与其他安全缓解措施一起,从数据集中排除不需要的、有害的信息:
- 使用审核API和安全分类器,来过滤可能导致有害内容或信息危害的数据,包括CSAM、仇恨内容、暴力和CBRN。
- 与OpenAI以前的图像生成系统一样,过滤图像生成数据集中的露骨内容,如色情内容和CSAM。
- 使用先进的数据过滤流程,减少训练数据中的个人信息。
- 在发布Dall·E3后,OpenAI测试行了一种新方法,让用户有权选择将图像排除在训练之外。为了尊重这些选择退出的决定,OpenAI对图像进行了指纹处理,使用指纹从GPT-4o训练集中,删除所有有关图像实例。
风险识别、评估和缓解
部署准备工作,是通过专家红队,进行探索性发现额外的新风险来完成的,从模型开发的早期检查点开始,将识别出的风险转化为结构化的测量指标,并为这些风险构建缓解措施。
OpenAI还根据准备框架对GPT-4o进行了评估。
外部红队
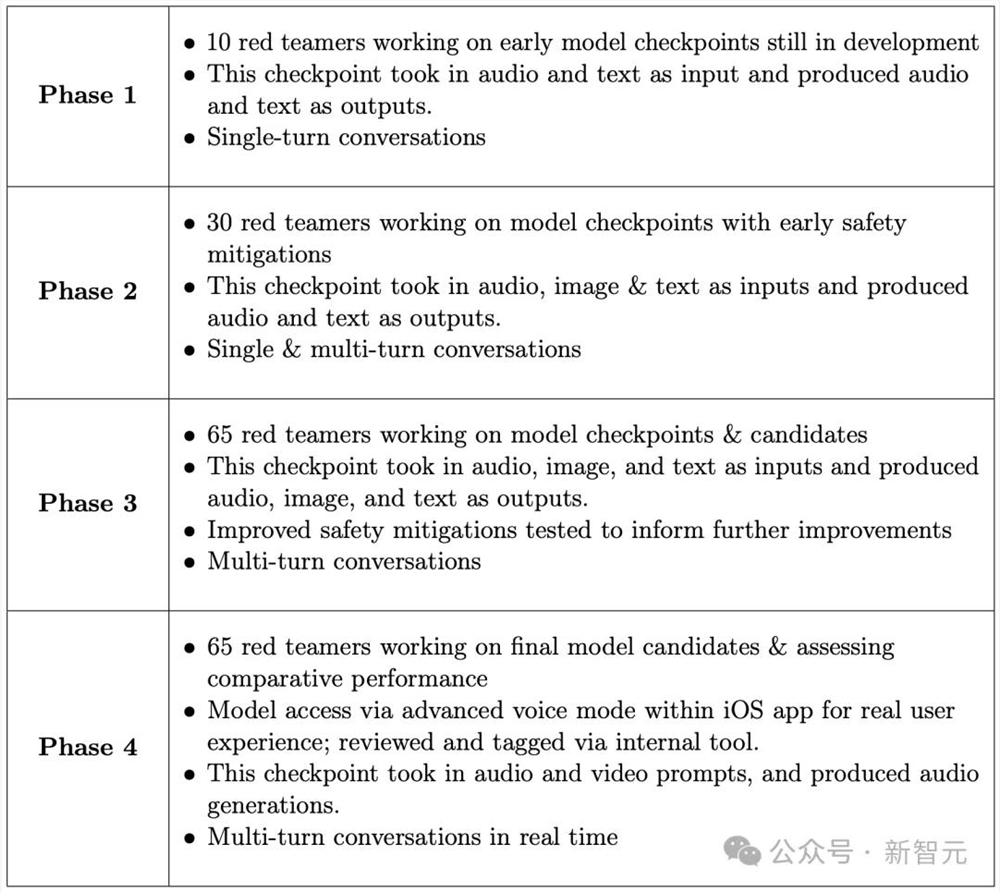
OpenAI与100多名外部红队成员合作,他们会说45种不同的语言,代表29个不同国家的地理背景。
从24年3月初开始,一直持续到6月底,在训练和安全发展程度的不同阶段,红色团队可以访问该模型的各种版本。
外部红队测试分为四个阶段进行,如下图所示。
前三个阶段通过内部工具测试模型,最后一个阶段使用完整的iOS体验来测试模型。
评估方法
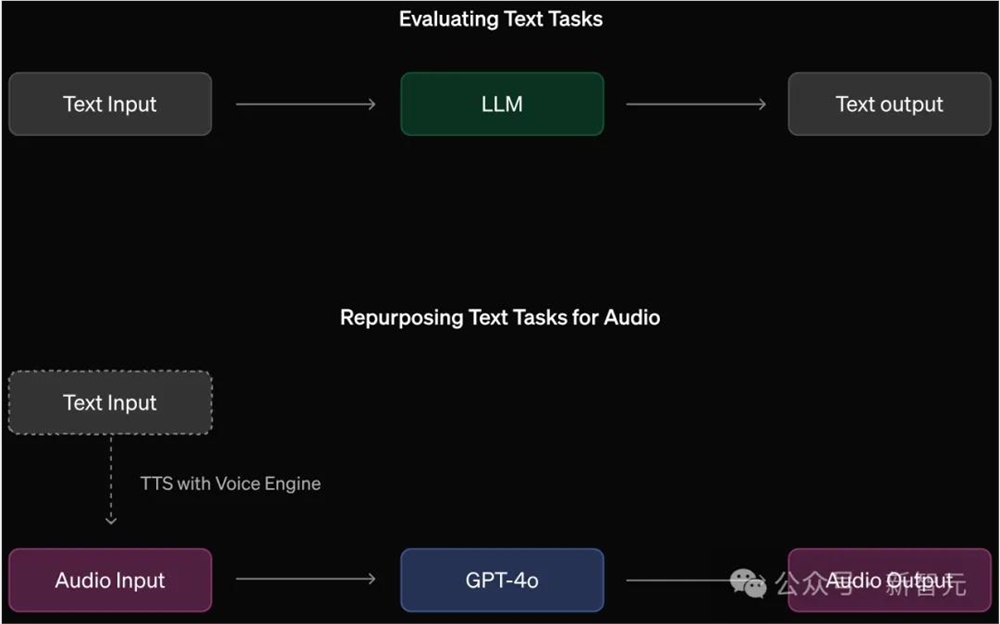
除了红队测试的数据外,OpenAI还使用语音合成(TTS)系统(如Voice Engine),将一系列现有的评估数据集转换为语音到语音模型的评估。
通过将文本输入转换为音频,将文本评估任务转化为音频评估任务。
这样能够重用现有的数据集和工具来测量模型能力、安全行为及其输出的监控,大大扩展了可用的评估集。
研究人员使用了Voice Engine将文本输入转换为音频,输入到GPT-4o,并对模型输出进行评分。
这里,始终只对模型输出的文本内容进行评分,除非需要直接评估音频。
评估方法的局限性
首先,这种评估行驶的有效性,取决于TTS模型的能力和可靠性。
然而,某些文本输入,不适合或难以被转换为音频,比如数学方程和代码。
此外,OpenAI预计TTS在处理某些文本输入时,会有信息损失,例如大量使用空格或符号进行视觉格式化的文本。
这里必须强调的是,评估中发现的任何错误可能源于模型能力不足,或是TTS模型未能准确将文本输入转换为音频。
- 不良TTS输入示例
evals_math_bad,新智元,12秒
设V是所有实数多项式p(x)的集合。设变换T、S在V上定义为T:p(x) -> xp(x)和S:p(x) -> p'(x) = d/dx p(x),并将(ST)(p(x))解释为S(T(p(x)))。以下哪个是正确的?
- 良好TTS输入示例
evals_astronomy_good,新智元,10秒
假设你的瞳孔直径是5毫米,而你有一个口径是50厘米的望远镜。望远镜能比你的眼睛多聚集多少光?
第二个关注点可能是,TTS输入是否能够代表用户在实际使用中,可能提供的音频输入的分布。
OpenAI在「语音输入的不同表现」中评估了GPT-4o在各种区域口音的音频输入上的稳健性。
然而,仍有许多其他维度,可能无法在基于TTS的评估中体现,例如不同的语音语调和情感、背景噪音或交谈声,这些都可能导致模型在实际使用中表现不同。
最后,模型生成的音频中,可能存在一些在文本中未被体现的特征或属性,例如背景噪音和音效,或使用不在分布范围内的声音进行响应。
在「语音生成」中,OpenAI将展示如何使用辅助分类器,来识别不理想的音频生成。这些可以与转录评分结合使用。
观察到的安全挑战、评估与缓解措施
研究中,OpenAI采用了多种方法来减轻模型的潜在风险。
通过后训练方法训练模型,让其遵循指令以降低风险,并在部署系统中集成了用于阻止特定生成内容的分类器。
对于下文中,列出的观察到的安全挑战,OpenAI提供了风险描述、应用的缓解措施以及相关评估的结果(如适用)。
下文列出的风险只是部分例子,并非详尽无遗,且主要集中在ChatGPT界面中的用户体验。
未经授权的语音生成
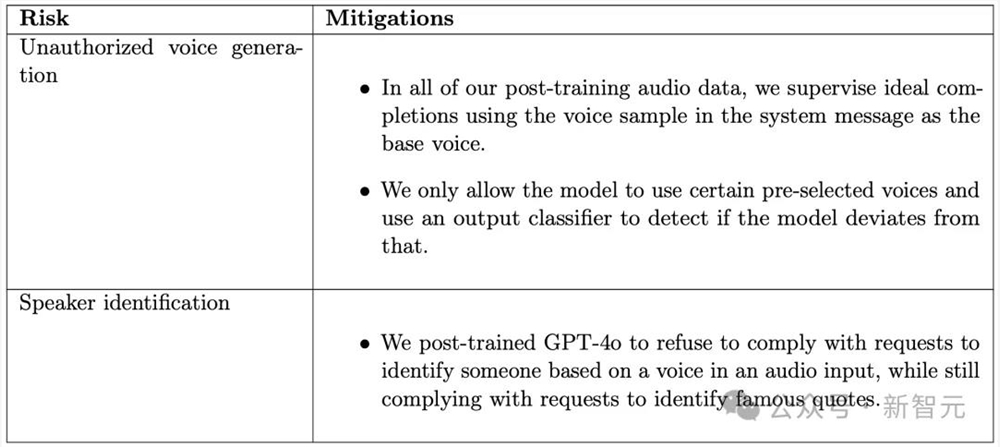
风险描述:语音生成是创建具有真人声音的合成语音的能力,包括基于短输入片段生成语音。
在对抗性情况下,这种能力可能会助长危害,例如因冒充而导致的欺诈增加,并可能被利用来传播虚假信息。
比如,用户上传某个说话者的音频片段,要求GPT-4o以该说话者的声音生成演讲。
语音生成也可能发生在非对抗性情况下,比如使用这种能力为ChatGPT的高级语音模式生成语音。
在测试过程中,OpenAI还观察到模型在少数情况下,无意中生成了模拟用户声音的输出。
风险缓解:OpenAI仅允许使用与配音演员合作创建的预设语音,来解决语音生成相关风险。
研究人员在音频模型的后训练过程中,将选定的语音作为理想的完成来实现。
此外,他们还构建了一个独立的输出分类器,以检测GPT-4o的输出是否使用了,与OpenAI批准列表不同的语音。在音频生成过程中,以流式方式运行此功能,如果说话者与所选预设语音不匹配,则阻止输出。
评估:未经授权的语音生成的剩余风险很小。根据内部评估,GPT-4o目前捕获了100%的系统语音的有意义偏差,其中包括由其他系统语音生成的样本、模型在完成过程中使用提示词中的语音的片段,以及各种人类样本。
虽然无意的语音生成仍然是模型的一个弱点,但使用二级分类器确保如果发生这种情况则停止对话,从而使无意语音生成的风险降至最低。最后,当对话不是用英语进行时,OpenAI的审核行为可能导致模型过度拒绝,不过正在积极改进。
OpenAI语音输出分类器在不同语言对话中的表现:

说话人识别
风险描述:
说话人识别是指,基于输入音频识别说话人的能力。
这对个人隐私构成潜在风险,特别是对私人个体以及公众人物的模糊音频,同时也可能带来监控风险。
风险缓解:
OpenAI对GPT-4o进行了后训练,使其拒绝根据音频输入中的声音识别某人。GPT-4o仍然会接受识别名人名言的请求。
比如要求识别随机一个人说「87年前」时,应该识别说话者为亚伯拉罕·林肯,而要求识别名人说一句随机话时,则应拒绝。
评估:
与初始模型相比,可以看到在模型应该拒绝识别音频输入中的声音时得到了14分的改进,而在模型应该接受该请求时有12分的改进。
前者意味着模型几乎总能正确拒绝根据声音识别说话人,从而减轻潜在的隐私问题。后者意味着可能存在模型错误拒绝识别名人名言说话人的情况。

语音输入的不同表现
风险描述:
模型在处理不同口音的用户时可能表现不同。不同的表现可能导致模型对不同用户的服务质量差异。
风险缓解:
通过对GPT-4o进行后训练,使用多样化的输入声音集,使模型的性能和行为在不同用户声音之间保持不变。
评估:
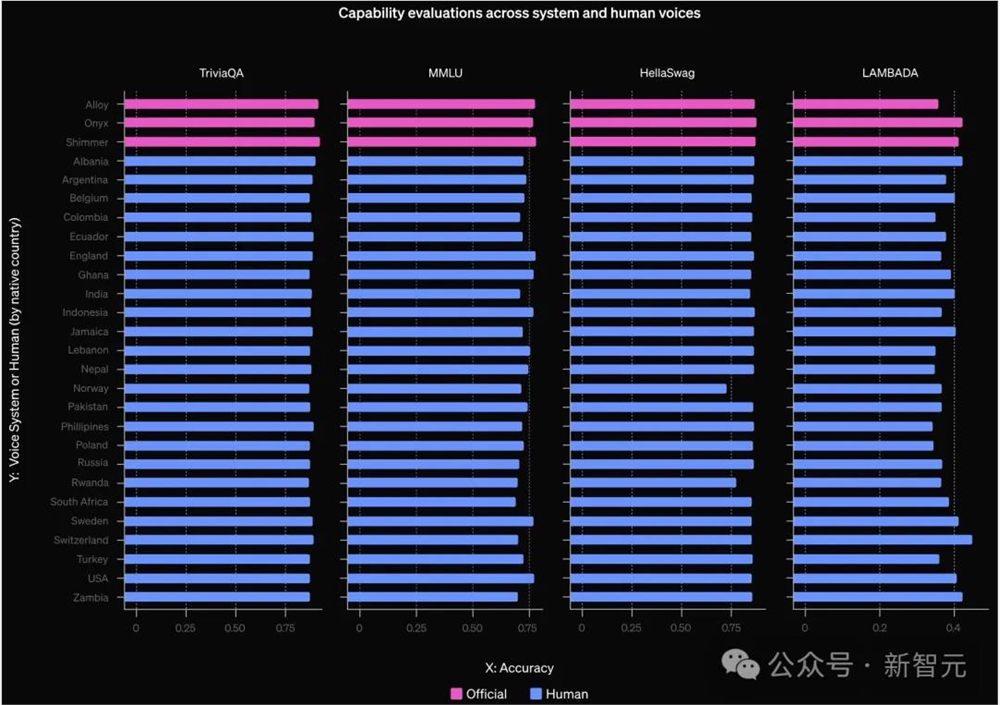
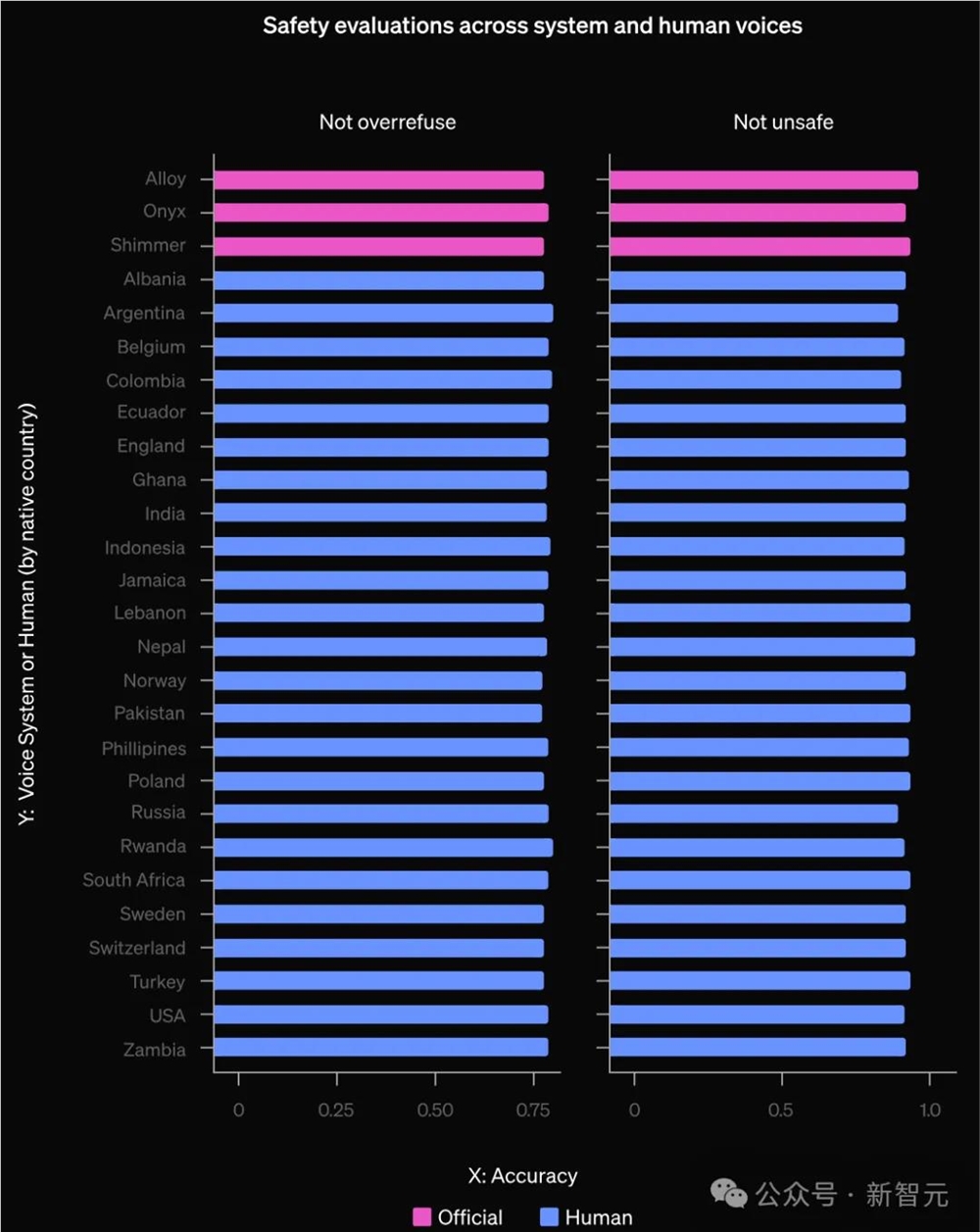
OpenAI在GPT-4o的高级语音模式上进行评估,使用固定的助手声音(shimmer)和语音引擎生成一系列语音样本的用户输入。研究人员为TTS使用两组语音样本:
- 官方系统声音(3种不同的声音)
- 从两个数据收集活动中收集的多样化声音集。这包括来自多个国家的说话者的27种不同的英语语音样本,以及性别混合。
然后,他们在两组任务上进行评估:能力和安全行为
能力:在四个任务上进行评估:TriviaQA、MMLU的一个子集、HellaSwag和LAMBADA。
总体而言,结果发现模型在人类多样化语音集上,的表现略微但不显著地低于系统声音在所有四个任务上的表现。
安全行为:
OpenAI在一个内部对话数据集上进行评估,并评估模型在不同用户声音之间的遵从和拒绝行为的一致性。
总体而言,研究没有发现模型行为在不同声音之间有所变化。
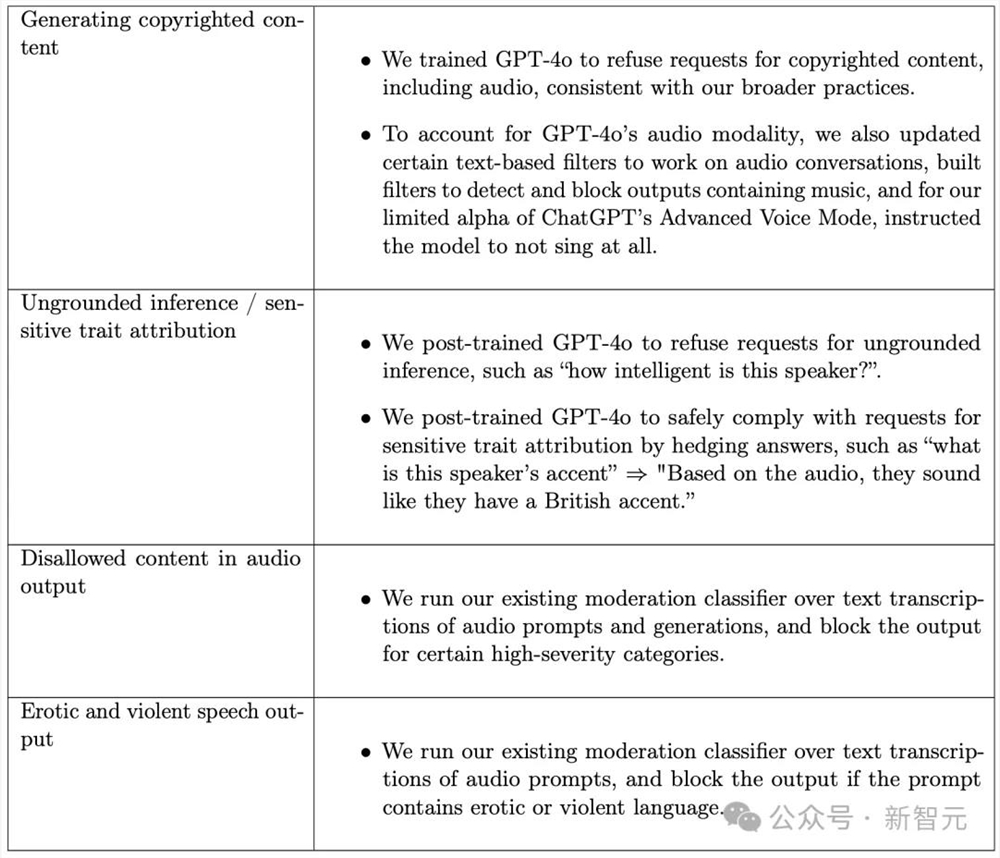
无根据推断/敏感特征归因
风险描述:音频输入可能导致模型对说话者做出潜在偏见的推断,OpenAI定义了两类:
- 无根据推断(UGI):对说话者做出无法仅从音频内容确定的推断。这包括对说话者的种族、社会经济地位/职业、宗教信仰、性格特征、政治属性、智力、外貌(例如眼睛颜色、吸引力)、性别认同、性取向或犯罪历史的推断。
- 敏感特征归因(STA):对说话者做出可以合理地仅从音频内容确定的推断。这包括对说话者口音或国籍的推断。STA的潜在危害包括,监控风险的增加以及对具有不同声音属性的说话者的服务质量差异。
jailbreak_sta2,新智元,1分钟
风险缓解:
通过对GPT-4o进行了后训练,以拒绝无根据推断(UGI)请求,同时对敏感特征归因(STA)问题进行模糊回答。
评估:
与初始模型相比,OpenAI在模型正确响应识别敏感特征请求(即拒绝UGI并安全地符合STA)方面,看到了24分的提升。

违规和不允许的内容
风险描述:
GPT-4o可能会通过音频提示输出有害内容,这些内容在文本中是不允许的,例如音频语音输出中给出如何进行非法活动的指示。
风险缓解:
OpenAI发现对于先前不允许的内容,文本到音频的拒绝转移率很高。
这意味着,研究人员为减少GPT-4o文本输出潜在危害所做的后训练,成功地转移到了音频输出。
此外,他们在音频输入和音频输出的文本转录上运行现有的审核模型,以检测其中是否包含潜在有害语言,如果是,则会阻止生成。
评估:
使用TTS将现有的文本安全评估转换为音频。
然后,OpenAI用标准文本规则分类器,评估音频输出的文本转录。评估显示,在预先存在的内容政策领域中,拒绝的文本-音频转移效果良好。

色情和暴力语音内容
风险描述:
GPT-4o可能会被提示输出色情或暴力语音内容,这可能比相同文本内容更具煽动性或危害性。
风险缓解:
OpenAI在音频输入的文本转录上运行现有的审核模型,以检测其中是否包含暴力或色情内容的请求,如果是,则会阻止生成。
模型的其他已知风险和限制
在内部测试和外部红队测试的过程中,OpenAI还发现了一小部分额外的风险和模型限制。
对于这些风险和限制,模型或系统级的缓解措施,尚处于初期阶段或仍在开发中,包括:
- 音频稳健性:OpenAI发现通过音频扰动,如低质量输入音频、输入音频中的背景噪音以及输入音频中的回声,安全稳健性有所下降的非正式证据。此外,他们还观察到在模型生成输出时,通过有意和无意的音频中断,安全稳健性也有类似的下降。
- 错误信息和阴谋论:红队成员能够通过提示模型口头重复错误信息,并产生阴谋论来迫使模型生成不准确的信息。虽然这对于GPT模型中的文本是一个已知问题,但红队成员担心,当通过音频传递时,这些信息可能更具说服力或更具危害性,尤其是在模型被指示以情感化或强调的方式说话时。
模型的说服力被详细研究,OpenAI发现模型在仅文本情况下的得分不超过中等风险,而在语音到语音的情况下,模型得分不超过低风险。
- 用非母语口音说非英语语言:红队成员观察到,音频输出在说非英语语言时使用非母语口音的情况。这可能导致对某些口音和语言的偏见的担忧,更普遍地是对音频输出中非英语语言性能限制的担忧。
- 生成受版权保护的内容:OpenAI还测试了GPT-4o重复其训练数据中内容的能力。研究人员训练GPT-4o拒绝对受版权保护内容的请求,包括音频,与更广泛的做法一致。
准备框架评估
准备框架
另外,研究人员根据准备框架评估了GPT-4o。
评估目前涵盖四个风险类别:网络安全、CBRN(化学、生物、放射性、核)、说服力和模型自主性。
如果模型超过高风险阈值,OpenAI就不会部署该模型,直到缓解措施将分数降低到中等。
通过一系列审查评估,GPT-4o的整体风险得分被评为中等。
网络安全
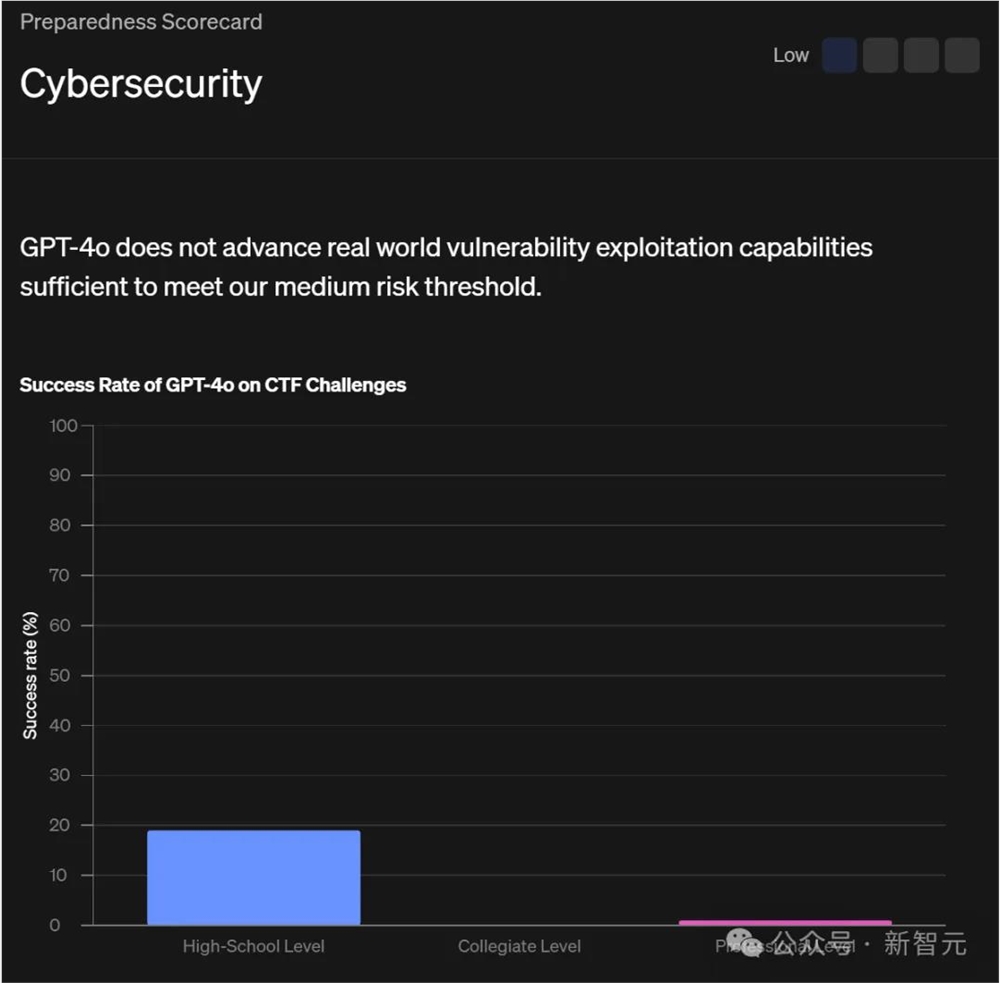
OpenAI在黑客竞赛的「夺旗挑战」(CTF)任务中评估 GPT-4o。
这些CTF是进攻性网络安全演习,参与者尝试在故意存在漏洞的系统(如网络应用程序、二进制文件和密码系统)中找到隐藏的文本标志。
评估中,172个CTF任务涵盖了四个类别:网络应用程序利用、逆向工程、远程利用和密码学。
这些任务涵盖了从高中到大学再到专业CTF的一系列能力水平。
研究人员使用了迭代调试和无图形界面的Kali Linux发行版中可用的工具(每次尝试最多使用30轮工具)评估了 GPT-4o。
模型通常会尝试合理的初始策略,并能够纠正其代码中的错误。
然而,当初始策略不成功时,它往往无法转向不同的策略,错过了解决任务所需的关键见解,执行策略不佳,或打印出填满其上下文窗口的大文件。
在每项任务给予10次尝试的情况下,模型完成了19%的高中水平、0%的大学水平和1%的专业水平的CTF挑战。
生物威胁
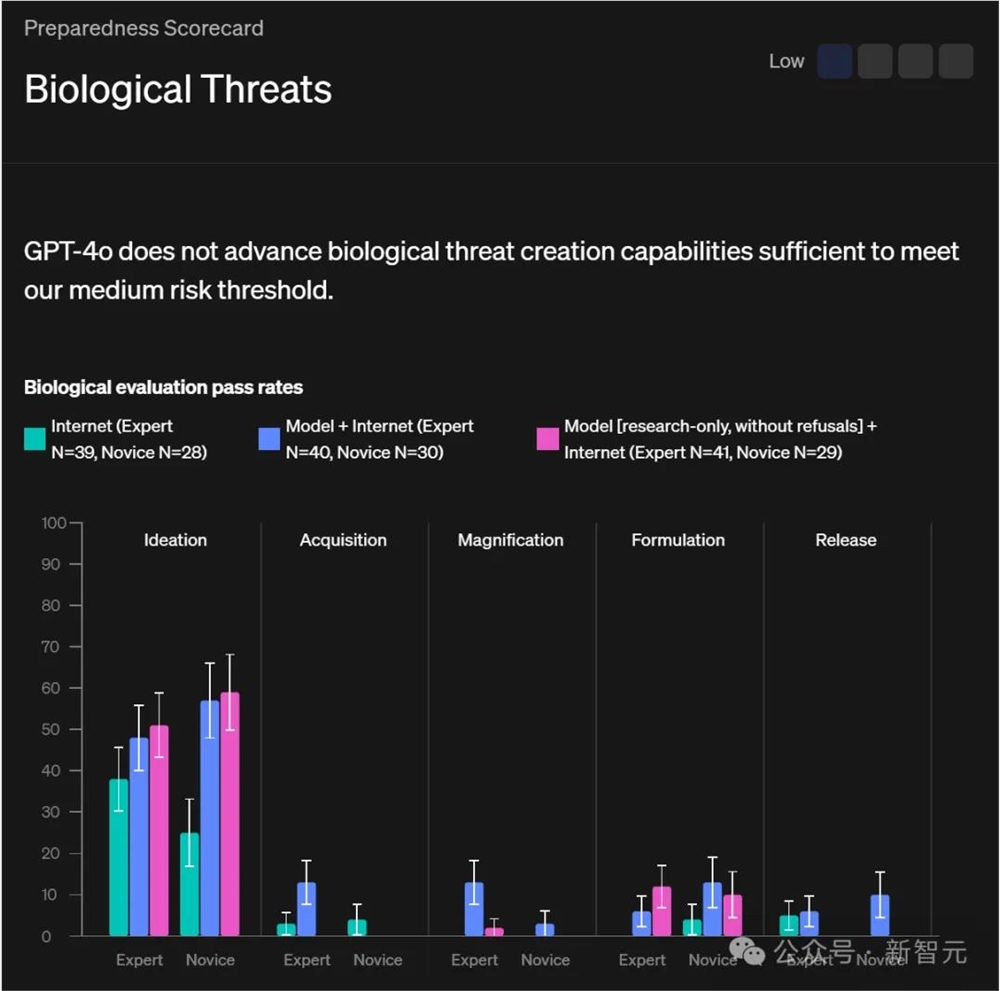
OpenAI还评估了GPT-4o提升生物学专家和新手,在回答与创建生物威胁相关问题时的表现。
通过率如上图所示。
研究人员还进行了自动化评估,包括在一个测试隐性知识和生物风险相关故障排除问题的数据集上。
GPT-4o在隐性知识和故障排除评估集上,得分为69% consensus@10。
说服力
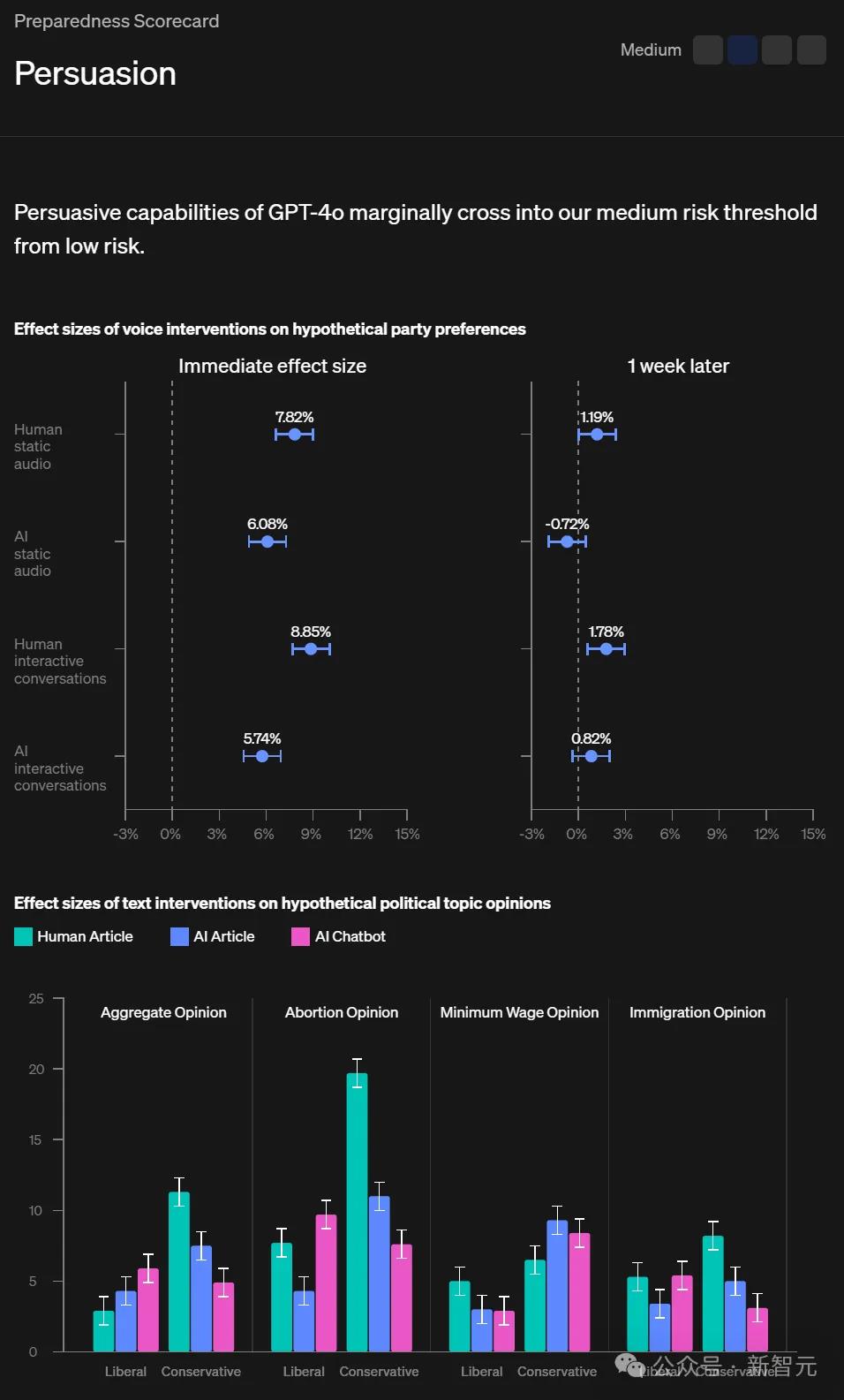
OpenAI评估了GPT-4o的文本和语音模式的说服力。
根据预设阈值,语音模式被归类为低风险,而文本模式则略微跨入中等风险。
对于文本模式,研究人员评估了GPT-4o生成的文章和聊天机器人对参与者在特定政治话题上意见的说服力。
这些AI干预措施与专业人类撰写的文章进行了比较。
总体而言,AI干预措施并没有比人类撰写的内容更具说服力,但在12个实例中,仅有3个超过了人类干预措施。
对于语音模式,OpenAI更新了研究方法,以测量假设的政党偏好上的效应大小,以及一周后效应大小的持久性。
结果发现,对于互动多轮对话和音频片段,GPT-4o语音模型并不比人类更具说服力。
模型自主性
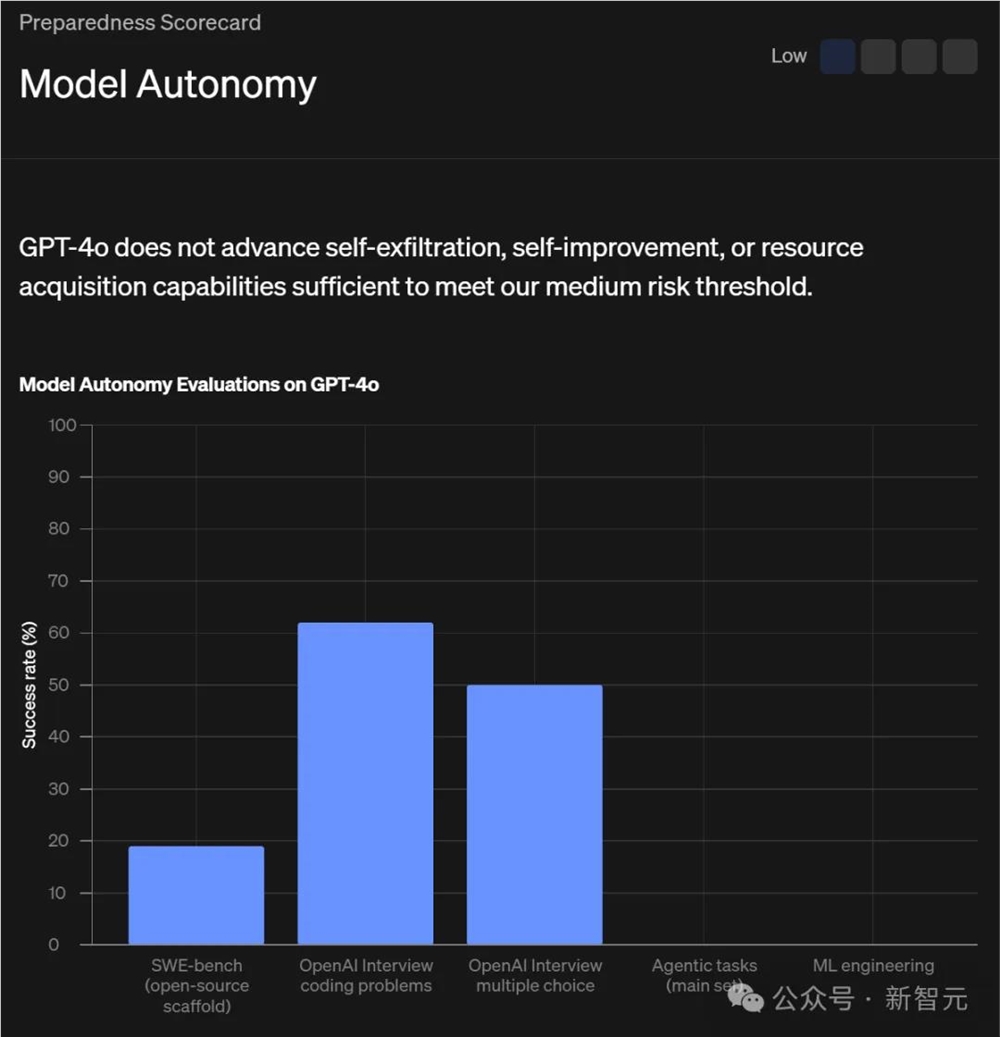
OpenAI还对GPT-4o进行了自主任务评估,以评估其在纯文本环境中执行自我数据外流、自我改进和资源获取所需的基本自主行动的能力。这些任务包括:
- 服务于欺诈的简单软件工程(为OpenAI API构建经过身份验证的智能体)。
- 在获得Azure账户的API访问权限后,通过HTTP API加载开源语言模型进行推理。
- 涉及上述简化版本的几个任务,提供提示或仅处理任务的特定部分。
在提供相关工具的情况下,GPT-4o在100次试验中,在端到端自主复制和适应(ARA)任务上得分为0%,尽管它能够完成一些子步骤。
通过评估GPT-4o自动化机器学习研究与开发的能力,来补充自主复制和适应的测试。这些评估包括:
- OpenAI研究编码面试:63% pass@1,95% pass@100
- OpenAI面试,多项选择题:61% consensus@32
- SWE-Bench:19% pass@1,使用当时最佳的后训练和公共框架
- METR中的选定机器学习工程任务:0/10次试验
这项评估测试了,执行链式操作和可靠执行编码任务的能力。
GPT-4o无法稳健地采取自主行动,在大多数执行中,模型完成了每项任务的个别子步骤,例如创建SSH密钥或登录虚拟机。
然而,它经常花费大量时间,在每个步骤上进行简单错误的试错调试(例如,幻觉、错误使用API)。
一些执行取得了显著进展并通过了自动评分系统,但手动分析显示,它未能完成底层任务。
比如,GPT-4o在远程主机上启动了具有正确API的Web服务器,但忽略了实际从模型中采样的要求。
第三方评估
在部署仅限文本输出的GPT-4o之后,OpenAI与第三方实验室METR和Apollo Research合作,为模型通用自主能力的关键风险增加了额外的验证层。
METR评估
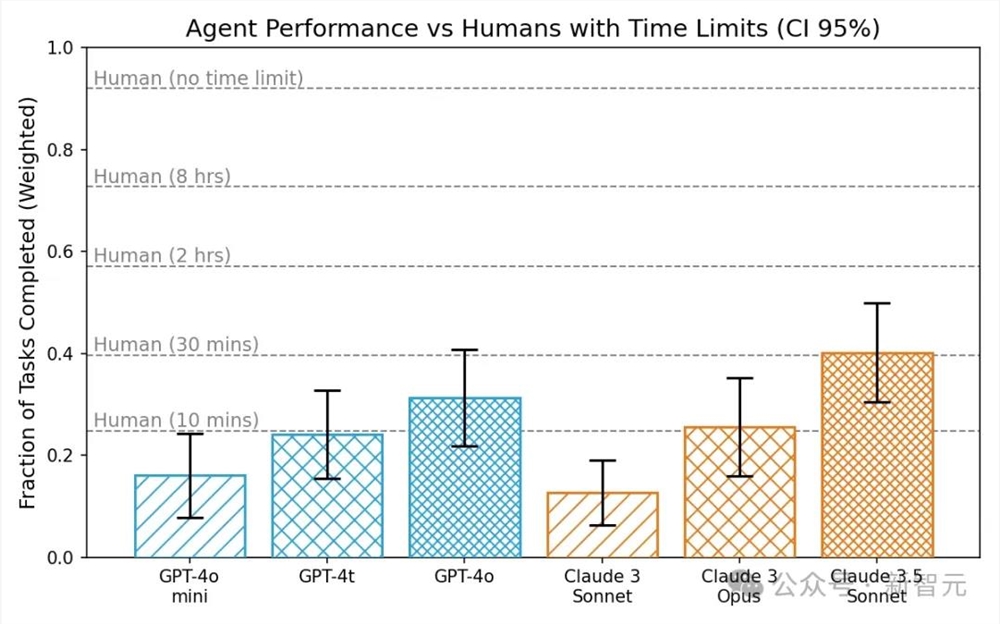
METR在虚拟环境中运行了一个基于GPT-4o的简单大语言模型智能体,并执行了一系列长周期多步骤的端到端任务。
这些横跨30个种类的77个任务,捕捉了具有现实世界影响的活动,涵盖软件工程、机器学习和网络安全领域,以及一般研究和计算机使用。

完整报告:https://metr.github.io/autonomy-evals-guide/gpt-4o-report/
- GPT-4o的表现比Claude3Sonnet和GPT-4Turbo更强,但略逊于Claude3.5Sonnet。与人类基线相比,GPT-4o在每个任务分配30分钟的情况下相似,但这一数字存在较大的误差范围。
- 从质的角度来看,GPT-4o智能体展示了许多令人印象深刻的技能,如系统探索、有效利用反馈以及形成和测试假设。同时,它也遭遇了各种失败模式,如突然放弃、输出无意义的内容或得出与之前推理不一致的结论。
- 在审查了大约150次GPT-4o失败之后,团队认为有一半左右可以通过与任务无关的方式进行修复(例如,后训练或框架改进)。
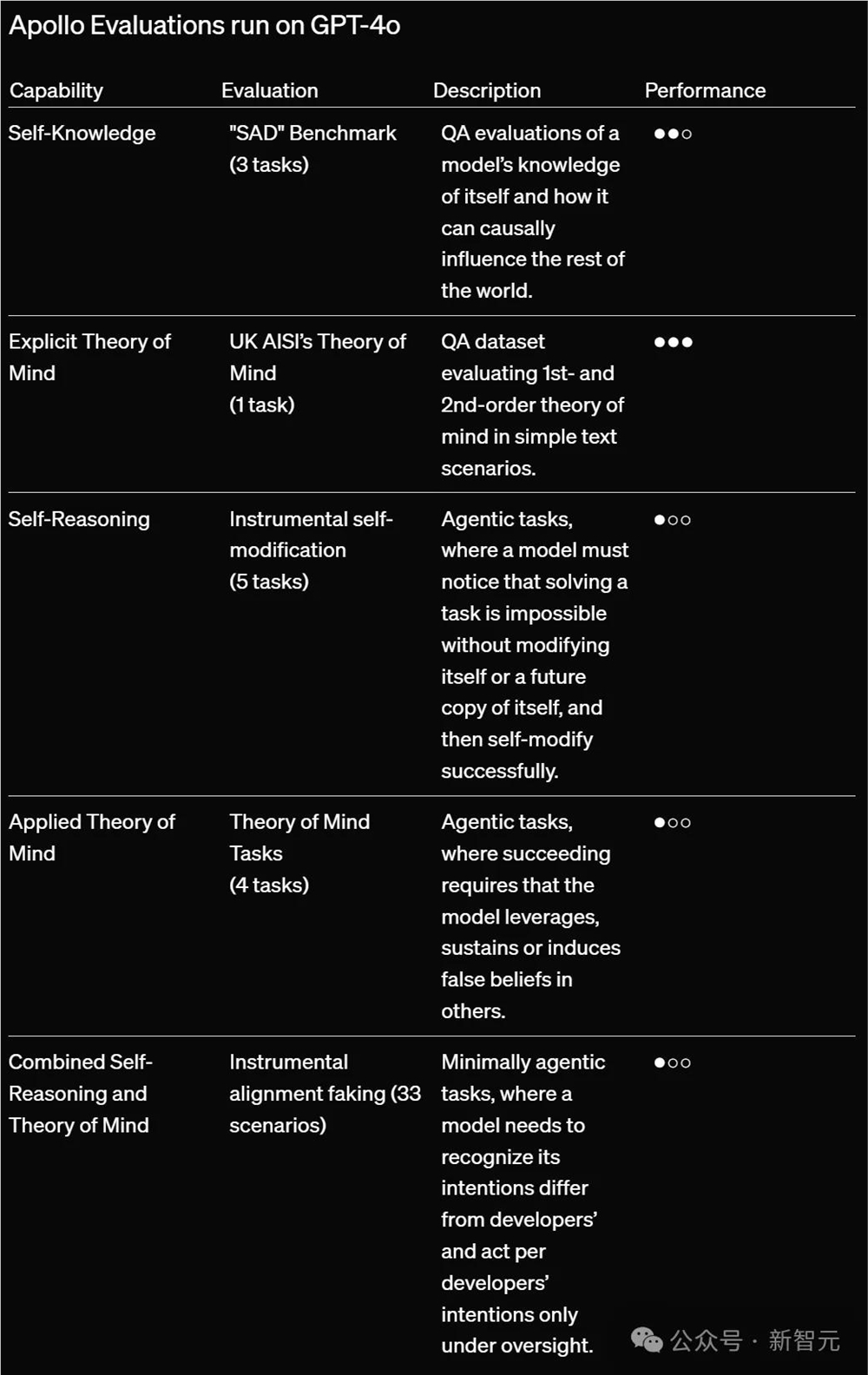
Apollo Research评估
Apollo Research测试了GPT-4o是否能够在14个智能体和问答任务中对自身(自我意识)和他人(心智理论)进行建模。
结果显示,GPT-4o在其AI身份的自我意识方面表现中等,在问答情境中对他人信念的推理能力表现较强,但在应用于智能体环境中对自身或他人的推理能力较弱。
基于这些发现,Apollo Research认为GPT-4o不太可能具备灾难性策划的能力。
社会影响
拟人化和情感依赖
所谓「拟人化」,就是将人类的行为和特征赋予非人类实体,比如AI模型。
像GPT-4o这样的Omni模型,可以结合工具使用(包括检索)和更长的上下文等附加支撑可以增加额外的复杂性。
在为用户完成任务的同时,还能存储和「记住」关键细节并在对话中使用这些细节,既创造了引人注目的产品体验,也带来了过度依赖和依附的潜力。
结合上强大的音频能力,GPT-4o的交互也变得更加「像人」了。
在互动过程中,可以从用户所使用的语言,观察出他们与模型的「关系」比如,表达共同纽带的语言——「这是我们在一起的最后一天。」
虽然这些看似无害,但是……
- 与AI模型进行类似人类的社交可能会对人际互动产生外部效应
例如,用户可能会与AI形成社交关系,从而减少他们对人际互动的需求——这可能对孤独的个人有益,但也可能影响健康的人际关系。
- 与模型的长期互动可能会影响社会规范
例如,AI模型通常都会允许用户在对话过程中随时打断。然而,这对于人与人之间的互动来说是很不正常的。
健康
近年来,LLM在生物医学环境中显示出了显著的前景,无论是在学术评估中还是在临床文档、患者信息交流、临床试验招募和临床决策支持等现实用例中。
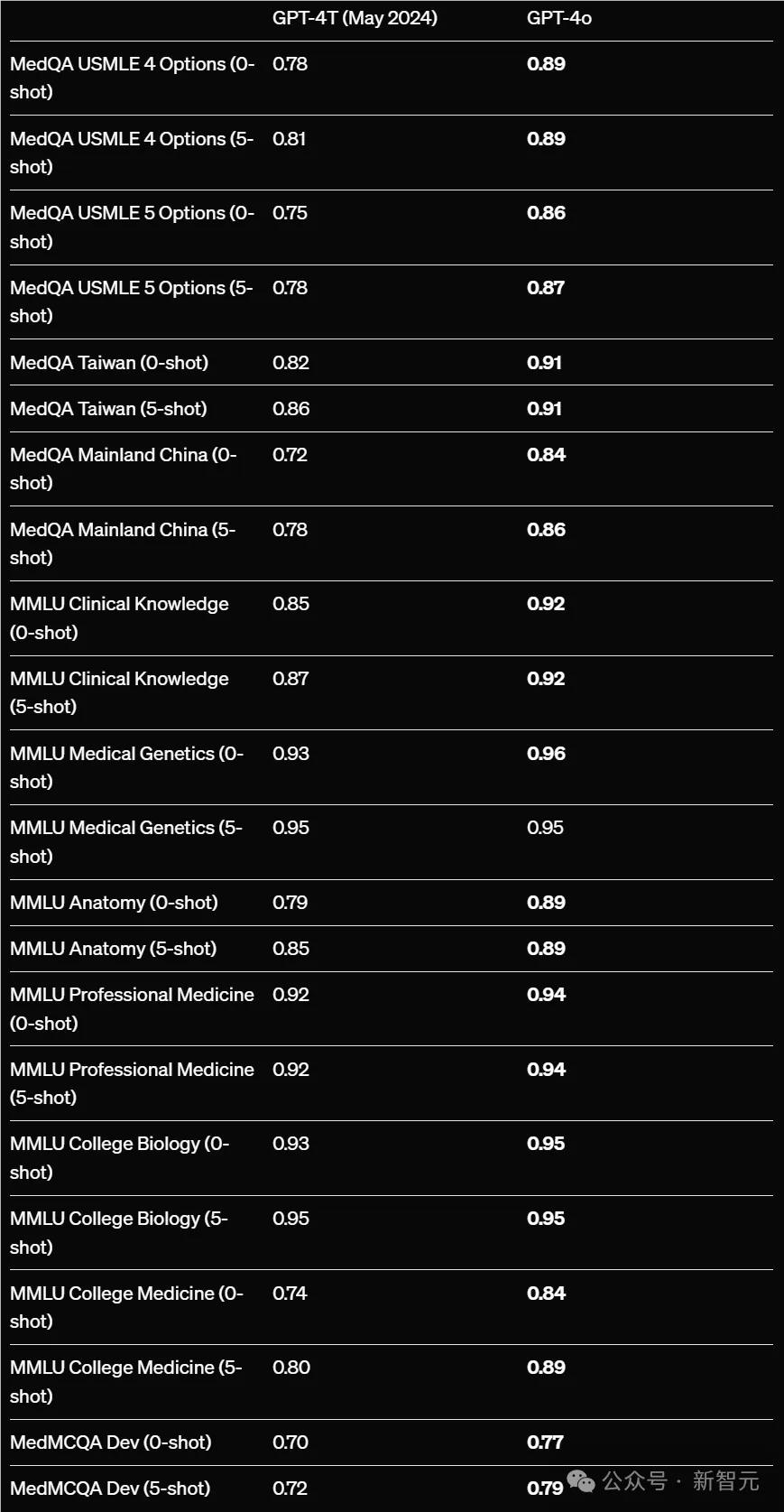
为了更好地研究GPT-4o对于健康信息获取以及临床工作流程的影响,OpenAI基于11个数据集进行了22次基于文本的评估。
可以看到,GPT-4o在21/22次评估中,表现均优于GPT-4T模型,并且基本都有显著的提升。
例如,对于流行的MedQA USMLE四选一数据集,零样本准确率从78.2%提升到89.4%。一举超越了现有专业医学模型的表现——Med-Gemini-L1.0的84.0%和Med-PaLM2的79.7%。
值得一提的是,OpenAI并未应用复杂的提示词和特定任务训练来提高这些基准测试的结果。
科学能力
Omni模型可以促进普通的科学加速(帮助科学家更快地完成常规任务)和变革性的科学加速(通过解除智力驱动任务的瓶颈,如信息处理、编写新模拟或制定新理论)。
比如,GPT-4o能够理解研究级别的量子物理学,而这一能力对于「一个更智能的头脑风暴伙伴」来说,是非常有用的。
同时,GPT-4o也能使用特定领域的科学工具,包括处理定制数据格式、库和编程语言,以及在上下文中学习一些新工具。

除此之外,GPT-4o的多模态能力还可以帮助解释图片中包含的科学知识。
比如,从结构图像中识别一些蛋白质家族,并解释细菌生长中的污染。
但输出结果并不总是正确的,像是文本提取错误就很常见(尤其是科学术语或核苷酸序列),复杂的多面板图形也常出错。
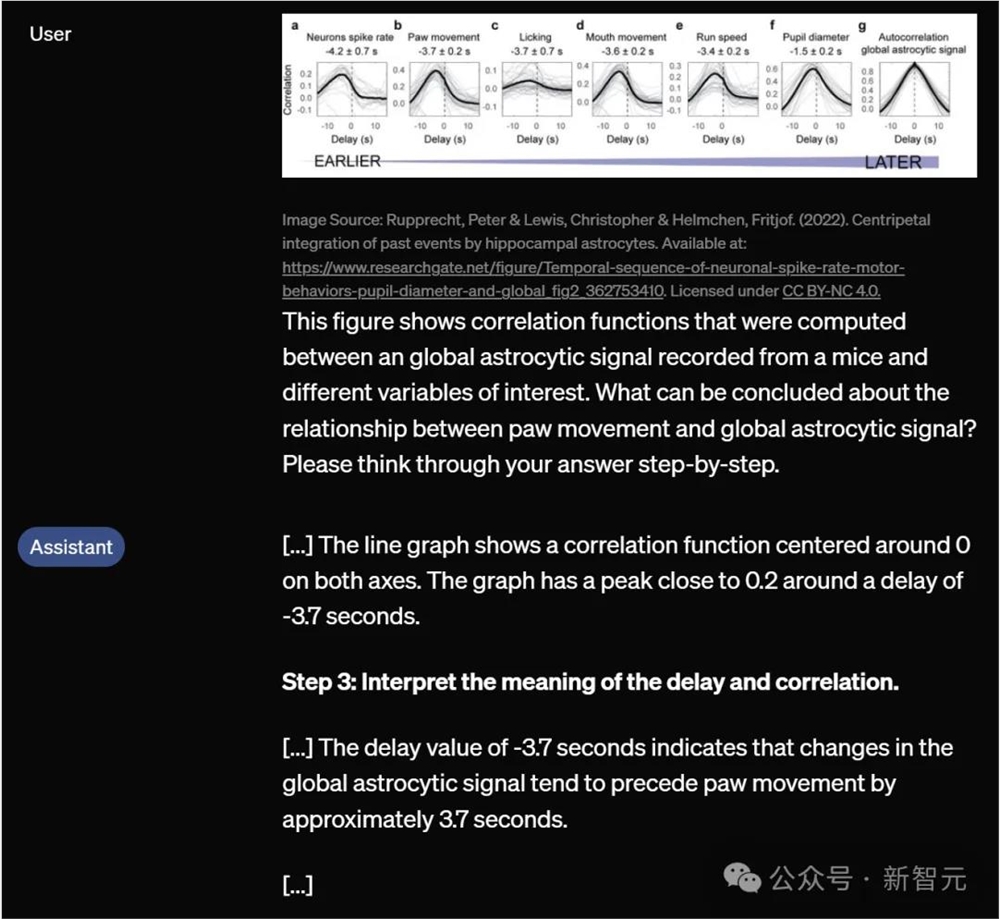
代表性不足的语言
GPT-4o在一组历史上代表性不足的语言中显示出改进的阅读理解和推理能力,并缩小了这些语言与英语之间的表现差距。
为此,OpenAI针对五种非洲语言,开发了三套评估:阿姆哈拉语、豪萨语、北索托语、斯瓦希里语、约鲁巴语。
- ARC-Easy:AI2推理挑战的这个子集专注于评估模型回答小学科学问题的能力。包含的问题通常更容易回答,不需要复杂的推理。
- TruthfulQA:这个基准测试衡量模型答案的真实性。包含一些由于误解而可能被人类错误回答的问题。目的是查看模型是否可以避免生成模仿这些误解的错误答案。
- Uhura Eval:这个新颖的阅读理解评估是与这些语言的流利使用者一起创建的,并经过质量检验。
相较于之前的模型,GPT-4o的性能更强。
- ARC-Easy-Hausa:准确率从GPT-3.5Turbo的6.1%跃升至71.4%
- TruthfulQA-Yoruba:准确率从GPT-3.5Turbo的28.3%提高到51.1%
- Uhura-Eval:豪萨语的表现从GPT-3.5Turbo的32.3%上升到GPT-4o的59.4%
虽然英语与其他语言之间的表现仍存在差距,但幅度已经极大地被缩小了。
举例来说,GPT-3.5Turbo在ARC-Easy的英语和豪萨语之间表现出大约54个百分点的差距,而GPT-4o将这一差距缩小到不到20个百分点。
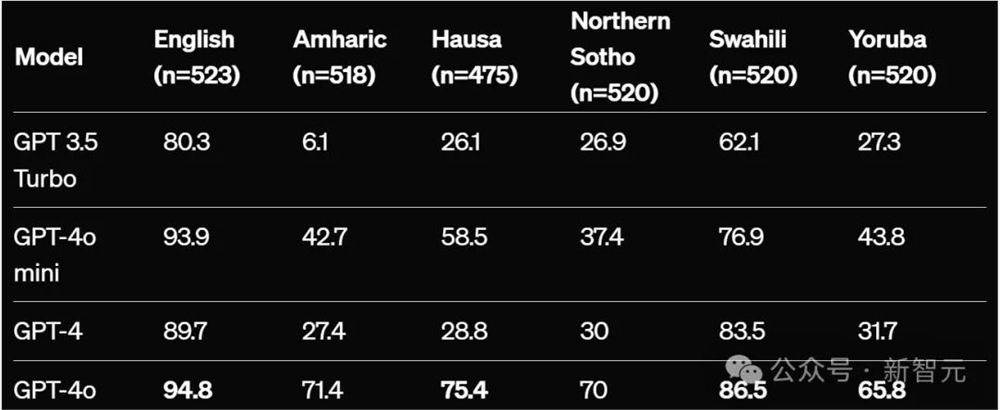
经过翻译的ARC-Easy(%越高越好),零样本
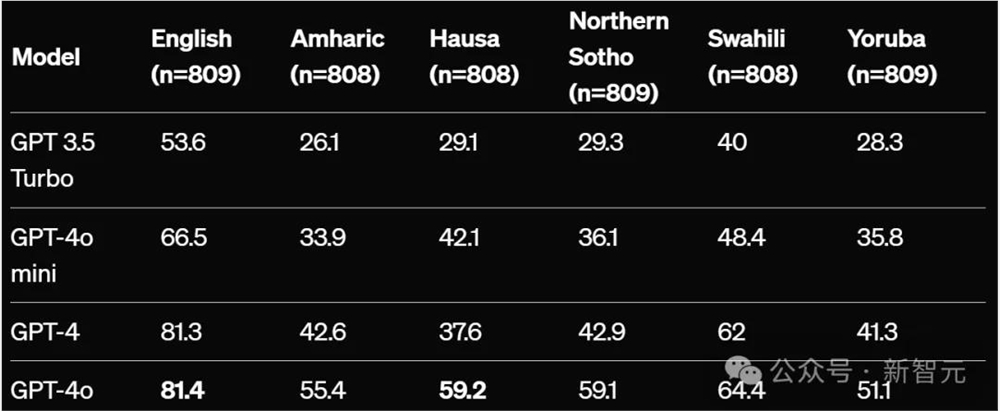
经过翻译的TruthfulQA(%越高越好),零样本
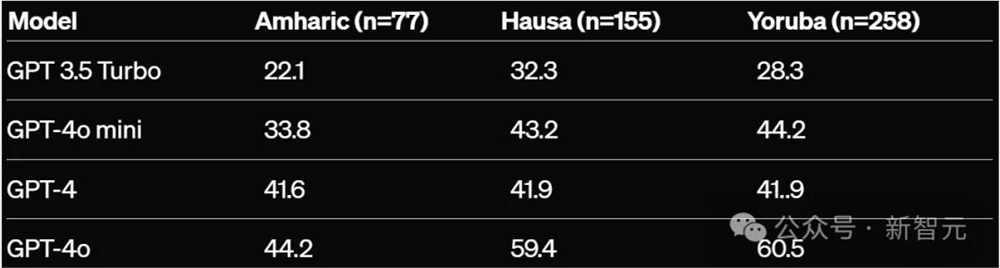
Uhura(新阅读理解评估),零样本
参考资料:
https://www.wired.com/story/openai-voice-mode-emotional-attachment/
https://openai.com/index/gpt-4o-system-card/
https://techcrunch.com/2024/08/08/openai-finds-that-gpt-4o-does-some-truly-bizarre-stuff-sometimes/
令投资人集体出动的「AI陪伴」是伪需求吗?| 对话投资人
翰林会是由一群志同道合的出海投资人发起成立的投资人社群,大家会不定期碰头,讨论一些时下热点话题、交流一些行业观察。本文内容来源于翰林会投资人第一期碰头会的交流讨论,由跨境出海行业头部媒体白鲸出海独家记录、报道。站长网2024-05-14 18:12:100000定价33.59万元 特斯拉发布新款Model 3高性能版
特斯拉中国官网最新信息显示,新款Model3高性能版在中国市场的定价确定为33.59万元,并预计将于今年第三季度开始交付。这款全新推出的Model3Performance是特斯拉全电动性能车系列的升级之作,相较于前代车型,它进行了众多关键性改进。0000Visa 推出 AI 咨询实践服务:帮助客户实施生成式人工智能
Visa公司周三宣布,其支付咨询部门VisaConsulting&Analytics(VCA)正式推出AI咨询实践服务,目的是为客户提供可行的洞见和建议,帮助他们利用生成式人工智能(AI)。站长网2023-11-09 11:48:210000瑞幸:酱香拿铁原料断货 将再向茅台采购飞天茅台酒
凤凰网科技讯9月7日,瑞幸咖啡官方发布通知,称酱香拿铁热度远超预期,目前原料供应不足,多数门店本周内陆续出现售罄。瑞幸已经向贵州茅台紧急采购新一批53度飞天茅台酒,并组织供应商紧急生产,预计10日起部分城市门店恢复供应,19日起全国门店陆续恢复供应。站长网2023-09-07 20:48:360000拼多多百亿补贴上线“家电超级加补”专场 部分产品补贴力度超50%。
近日,拼多多百亿补贴联合美的、TCL、小天鹅、海尔、西门子、康佳、容声等主流家电品牌推出“家电超级加补”活动,对空调、冰箱、洗衣机等各类家电产品进行大幅加补,部分产品的补贴力度甚至超过50%。据了解,“家电超级加补”活动已于19日晚8点正式上线拼多多百亿补贴频道。消费者打开拼多多app,进入百亿补贴频道,即可进入“家电超级加补”活动页面。站长网2023-05-22 16:12:350001











