贾扬清:大模型尺寸正在重走CNN的老路;马斯克:在特斯拉也是这样
Transformer大模型尺寸变化,正在重走CNN的老路!
看到大家都被LLaMA3.1吸引了注意力,贾扬清发出如此感慨。
拿大模型尺寸的发展,和CNN的发展作对比,就能发现一个明显的趋势和现象:
在ImageNet时代,研究人员和技术从业者见证了参数规模的快速增长,然后又开始转向更小、更高效的模型。
听起来,是不是和GPT哐哐往上卷模型参数,业界普遍认同Scaling Law,然后出现GPT-4o mini、苹果DCLM-7B、谷歌Gemma2B如出一辙?
贾扬清笑称,“这是前大模型时代的事儿,很多人可能都不咋记得了:)”。

而且,贾扬清不是唯一一个感知到这一点的人,AI大神卡帕西也这么觉得:
大模型尺寸的竞争正在加剧……但是卷的方向反着来了!
模型必须先追求“更大”,然后才能追求“更小”,因为我们需要这个过程,帮咱把训练数据重构成理想的、合成的格式。
他甚至拍着胸脯打赌,表示我们一定能看到又好、又能可靠地思考的模型。
而且是参数规模很小很小的那种。
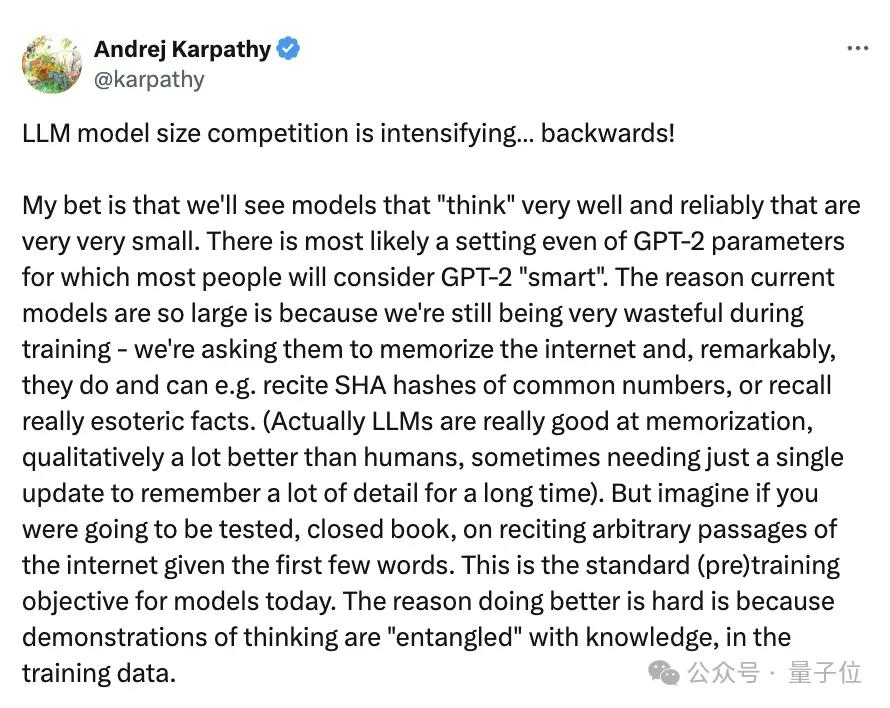
连马斯克都在卡帕西的评论区连连称是:
以上,大概可以称之为“大佬所见略同”。
展开说说
贾扬清的感慨,要从只在最强王座上短暂待了一天的LLaMA3.1说起。
那是首次实现“最强开源模型=最强模型”,不出意外,万众瞩目。
However,贾扬清在这个时候提出了一个观点:
“但我认为,行业会因小型垂直模型而真正蓬勃发展。”
至于啥是小型垂直模型,贾扬清也说得很清楚,比如以Patrouns AI的Iynx(该公司的幻觉检测模型,在幻觉任务上超过GPT-4o)为代表的那些很棒的中小模型。

贾扬清表示,就个人喜好而言,他本人是非常喜欢千亿参数模型的。
但现实情况里,他观察留意到,7B-70B参数规模之间的大模型,大家用起来更顺手:
它们更容易托管,不需要巨大的流量即可盈利;
只要提出明确的问题,就能得到质量还不错的输出——与和之前的一些看法相反。
与此同时,他听说OpenAI最新的、速度很快的模型也开始变得比“最先进的”大模型尺寸更小。
“如果我的理解是正确的,那么这绝对表明了行业趋势。”贾扬清直接表明了自己的观点,“即在现实世界中,使用适用的、具有成本效益、且仍然强大的模型。”
于是乎,贾扬清简单梳理了CNN的发展历程。
首先,是CNN的崛起时代。
以AlexNet(2012)为起点,开启了大约三年的模型规模增长时期。
2014年出现的VGGNet就是一个性能和规模都非常强大的模型。
其次,是缩小规模时期。
2015年,GoogleNet把模型大小从“GB”缩小到了“MB”级别,即缩小了100倍;但模型性能并没有因此骤减,反而保持了不错的性能。
遵循类似趋势的还有2015年面世的SqueezeNet模型等。
然后的一段时间,发展重点在追求平衡。
后续研究,如ResNet(2015)、ResNeXT(2016)等,都保持了一个适中的模型规模。
值得注意的是,模型规模的控制并没有带来计算量的减少——其实,大伙儿都愿意投入更多的计算资源,寻求一种“同等参数但更高效”的状态。
紧接着就是CNN在端侧起舞的一段时期。
举个例子,MobileNet是谷歌在2017年推出的一项有趣的工作。
有趣就有趣在它占用的资源超级少,但是性能却非常优异。
就在上周,还有人跟贾扬清提到:“Wow~我们现在还在用MobileNet,因为它可以在设备上运行,而且在出色的特征嵌入泛化(Feature Embedding Generality)。”
最后,贾扬清借用了来源于Ghimire等人的《A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration》里的一张图:
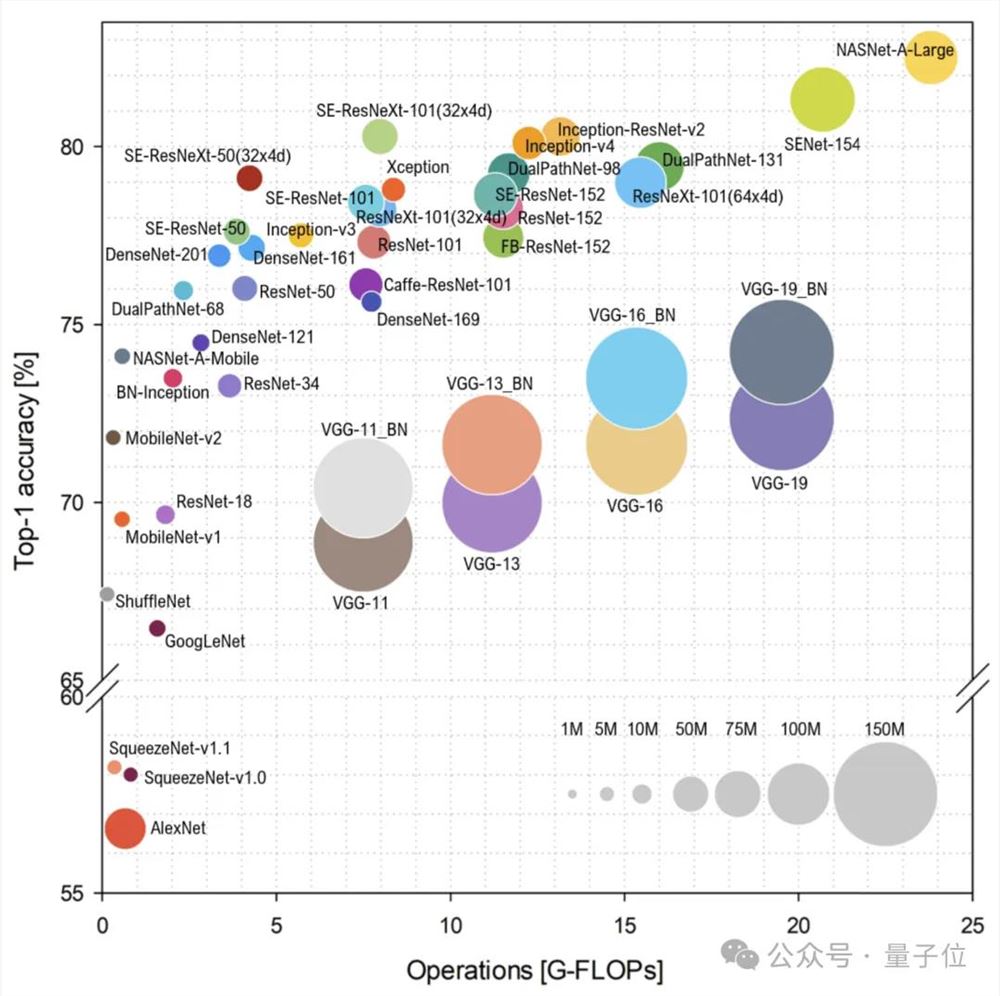
并再一次发出自己的疑问:
大模型尺寸,会遵循与CNN时代相同的趋势来发展吗?
网友怎么看?
其实GPT-4o mini这样走在大模型发展道路上“不大反小”的例子不在少数。
当上述几位表达出这样的观点后,立马有人点头如捣蒜,还拿出了一些别的类似例子,证明他们看到了相同的趋势。
有人立马跟上:
我这儿有个新的正面例子!Gemma-2就是把27B参数大小的模型知识蒸馏成更小的版本。
还有网友表示,开发更大的模型,意味着能给后续几代更小、更垂直的模型的训练“上强度”。
这个迭代过程最终会产生所谓的“完美训练集”。
这样一来,较小的大模型在特定领域,能与现在参数巨大的大模型一样聪明,甚至更聪明。
一言以蔽之,模型必须先变大,然后才能变小。

大多数讨论此观点的人,还是对这个趋势比较认同,有人直言“这是一件好事,比‘我的模型比你的模型大’参数竞赛更实用和有用。”
但是,当然了!
翻遍网络评论区,也有人发出不同的声音。
比如下面这位朋友就在贾扬清推文底下留言:
Mistral Large(背后公司Mistral AI)、LLaMA3.1(背后公司Meta)和OpenAI,持有最强竞争力模型的公司,目前可能都正在训练更大的模型。
我没发现有“更小型号模型搞定技术突破”的趋势哟。
面对这个问题,贾扬清倒也及时回复了。
他是这么说的:“没错!我说大模型尺寸可能在走CNN的老路,绝对不意味着号召大家停止训练更大的模型。”
他进一步解释道,这么说的本意是,随着技术(包括CNN和大模型)落地实践越来越广,大家已经开始越来越关注性价比更高的模型了。”
所以,或许更高效的小·大模型,能够重新定义AI的“智能”,挑战“越大越好”的假设。
OpenAI 支持的人工智能聊天机器人 My AI 发布神秘视频 吓坏 Snapchat 用户
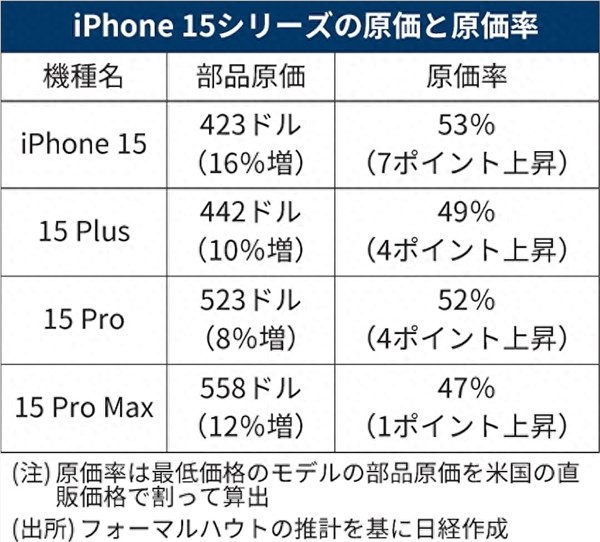
站长之家(ChinaZ.com)8月17日消息:尽管还没有到万圣节,但一些Snapchat用户却觉得像是在这个节日已经到来。周二晚上,Snapchat的MyAI聊天机器人发布了一个神秘的一秒钟的视频,画面上似乎是一面墙和一个天花板,尽管以前从未在消息中添加过视频。当用户问聊天机器人时,机器保持了怪异的沉默。图片来自Snap站长网2023-08-17 08:46:3000005999-9999元起!iPhone 15四款机型硬件成本出炉:苹果售价或不算贵
快科技10月17日消息,iPhone15系列已经快发售一个月了,从实际售卖情况来看,其在中国的首轮销量表现不及前作iPhone14,这更多的是因为Mate60的出现。现在,《日经新闻》发布了iPhone15系列的硬件成本,而iPhone15ProMax是苹果公司史上成本最高昂的手机。站长网2023-10-18 11:27:010000单月变现超千万的医美人新玩法:老板做网红,医生拼IP
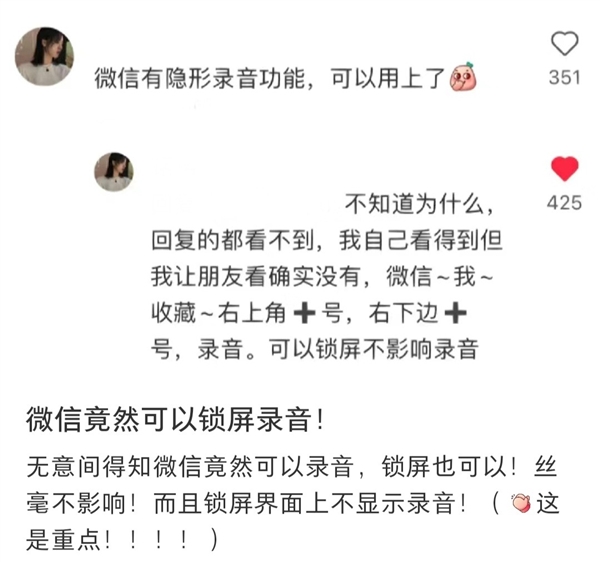
“开局一张脸,想要什么自己捏。”随着大众医美观念的变化,曾经争议不断的整容,逐渐成了网红们的流量密码。靠着分享自己反复动脸的整容经历,“韩安冉Abby”让自己的热度更进一步,全网粉丝数超千万;“beaty汪静”则带着粉丝复刻起了自己的网红脸,准备打造一个“汪静帝国”,目前抖音粉丝数达92万。站长网2024-11-30 10:42:160000才知道微信可以锁屏录音!教程来了:三步开启
快科技6月3日消息,由于微信每次更新说明都极为潦草,经常简单九个字解决了一些已知问题”,所以很多功能都需要用户自己发现。今天才知道微信可以锁屏录音”的话题引起不少关注,经实测确实可以,教程如下:1.打开微信我的收藏2.点击页面右上角号,再点右下角+号3.选择录音即可。实测iOS端确实可以录音,锁屏也依然会继续,不过顶部会显示有指示灯和录音状态。站长网2024-06-04 09:02:430003英伟达机器人跳APT舞惊艳,科比C罗完美复刻,CMU 00后华人共同一作
【新智元导读】机器人界「球星」竟被CMU英伟达搞出来了!科比后仰跳投、C罗、詹皇霸气庆祝动作皆被完美复刻。2030年,我们将会看到一场人形机器人奥运会盛宴。机器人版科比、詹皇、C罗真的来了!只见「科比」后仰跳投,在赛场上大杀四方。「C罗」和「詹姆斯」也纷纷展示了自己的招牌庆祝动作。以上这些还只是开胃菜,这款人形机器人还会侧跳、前跳、前踢、右踢,甚至能够完成深蹲、腿部拉伸等高难度动作。站长网2025-02-06 23:58:150000