达摩院发布一站式AI视频创作平台“寻光”,打造全新AI工作流
今年是 AI 视频生成爆发的元年,以 Sora 为代表的算法模型和产品应用不断涌现。短短几个月内,我们目睹了几十种视频生成工具的问世,基于 AI 的视频创作方式开始流行起来。
但新技术也引发更多的挑战与质疑,除了大家熟知的 “开盲盒”现象,AI 所生成的视频内容也因可控性差、处理工作流繁琐而频频被诟病。
OpenAI 曾经邀请专业视频制作团队对 Sora 进行了测试,其中来自于多伦多的 Shy Kids 团队,利用 Sora 制作了一个气球人主题的短片,把创意和 AI 技术进行了完美的结合,让人印象深刻。
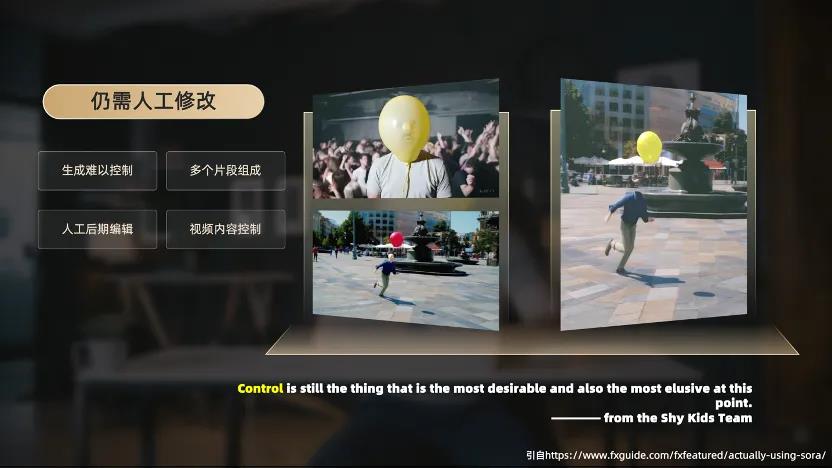
整个短片其实并不是 Sora 直接输出的结果,而是由多个视频片段组成,且 Sora 在生成不同视频时,很难保证主角的一致性。因此,在引入了大量的人工后期编辑,他们才呈现出最终的短片效果。Shy Kids 的主创们总结,“Sora 的技术很酷,但是它的生成过程很难控制。”
对生成内容的精准可控,是 AI 视频创作中的重要需求,也是今天算法面临的一大挑战。
为此,在刚结束的上海世界人工智能大会(WAIC)上,达摩院发布了一站式 AI 视频创作平台 “寻光”。
其定位为 PUGC 一站式 AI 视频创作平台,可辅助用户创作剧本、分镜图等,并通过工作流整合提升创作全流程的效率,支持对生成及上传素材进行丰富的 AI 编辑,提供人物控制、场景控制、风格迁移、运镜控制、目标新增 / 消除 / 修改等十多种 AI 编辑功能,让视频中的元素和对象精准可控。
达摩院希望借由寻光平台进一步提升 AI 视频创作的效率,目标是用 AI 能力重塑传统视频制作的整个流程,打造 AI 时代的全新视频工作流。
业界首次落地
基于图层的视频编辑
在寻光研发的初期,达摩院还与影视传媒从业者及创作者进行了广泛且密集调研,了解其对于视频 AIGC 创作的需求与痛点。他们发现,视频图层几乎是所有视频创作者们提到频次最高、最迫切的需求。
基于此,寻光平台首次在行业推出系统性的视频图层编辑功能。用户通过文本输入,即可生成符合文本描述且具有透明背景的视频,并且一键将其融合到其他背景视频当中。在传统视频生成能力的基础上,用图层这样一种更灵活的形式来产生内容。

寻光更提供图层拆解功能,轻轻一圈,选定目标立刻拆解为单独的图层视频,再丝滑嵌入不同的背景视频。

用户可以将不同的前景图层跟不同的背景进行图层融合,组合出更多新的视频。图层融合的能力进一步激发 AI 创作力和想象力,同时能够保持多个分镜头之间的场景和人物的一致性。

在达摩院看来,AI 不会取代创作者的工作,而是会优化视频创作的工作流,成为创意驱动的新引擎。
一站式 AI 创作平台
更简洁的交互,更丰富的编辑能力
剧本创作、分镜设计、素材编辑…… 传统的视频创作步骤分工明晰、周期冗长。在 AI 技术的加持下,原本分散在不同制作流程中的创作步骤,如今都可以在寻光平台上流畅完成。
“我们希望让视频编辑像操作 ppt 一样简洁直观,容易上手。” 达摩院视觉技术实验室高级算法专家陈威华在现场介绍,寻光平台的一大亮点在交互方面。
寻光平台在设计时便充分考虑到 AI 视频创作的特点,将每个视频项目抽象为多个分镜头画面,用户可根据剧本自动生成一组分镜头,也可以自己上传原始视频素材,由算法切分成多个分镜头。
在创作空间里,用户可以很方便的查看每一个分镜头,一个场景内的多个分镜头可以收起或者展开,场景之间可以通过拖拽来调整顺序,场景内的分镜头也可以进行拖拽。用户也可以在任意位置上进行分镜头的添加和新建,可调用图片生成或者视频生成能力去产生内容,也可以添加自己已有的各种素材。
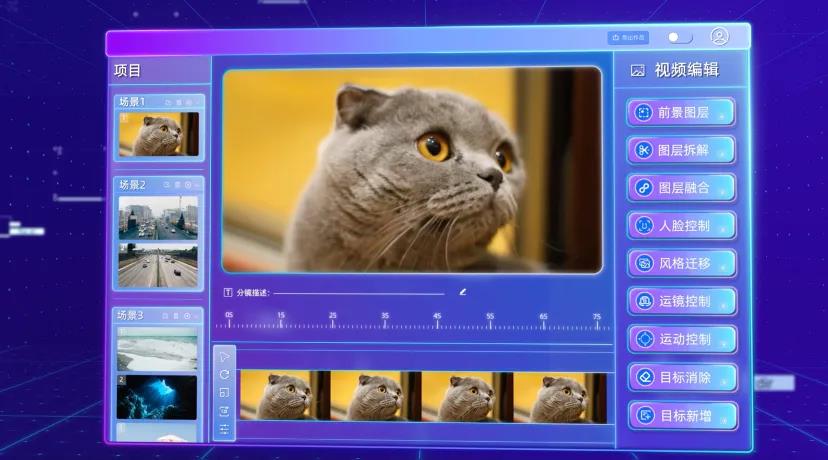
对于每个分镜头,寻光提供完整且智能的 AI 视频编辑能力进行处理,可依据用户意图,在语义层面而不是像素层面实现编辑。分镜头里的人体、人脸、前景、背景等任意局部目标,都可以进行精细化的编辑和修改。
比如,理解空间景深的运镜控制;

又比如,能够理解物体相对关系的目标消除 / 修改。

在对视频全局元素的编辑上,寻光平台提供了超过20种的风格迁移。

寻光也提供帧率控制、视频超分等实用的视频编辑功能。
“我们希望一个视频里的所有元素都是可编辑、可修改的,这样可以给用户的创作提供最大的自由度”,陈威华说。
写在最后
今天,我们正处在 AIGC 的变革浪潮之中,AI 有可能催生出新的视频工作流。无论是专业的影视从业者还是热爱创作的 UGC 用户,都将从中获益。
“工欲善其事,必先利其器”,达摩院希望寻光视频创作平台能够成为每一位创作者的专属视频工作室,实现 AI 与创作者之间更紧密、高效的协作,真正释放 AI 的生产力。
为此,达摩院视觉技术实验室已做了大量技术储备。该实验室致力于多模态视觉信号的理解与生成技术研究,当前的重点研究方向包括更加精准的图像 / 视频 /3D 内容生成,更加可控的图像 / 视频 /3D 内容编辑,更加高效的生成框架,多模态的理解 - 生成框架等。
陈威华表示,“寻光”将于近期开放内测,持续迭代,优化交互,欢迎创作者们来定制属于自己的 AI 工作流。
内测申请地址:
https://xunguang.damo-vision.com/
明星批量起诉自媒体侵权,2张图索赔3.5万元,创作者应该怎么办?
2张图,索赔35000元,这让头部娱乐博主“E姐狼小蓓”感到愤怒。2020年,她曾在一篇“讲述疫情期间香港艺人积极生活”的文章中使用了一位香港艺人的照片,时隔三年后收到律师函,因肖像侵权被索赔35000元。法律保护肖像权无可厚非,明星也没有让自媒体免费使用肖像的义务,但E姐认为这其中存在“无差别讹诈”,她在微博公开发问:“香港甘草艺人和绿叶艺人到底还需不需要内地自媒体关注和评论?”站长网2023-07-31 13:58:230000AI导致失业,人类是否应该得到补偿?
人类为人工智能(AI)的训练提供了各式各样的数据,但是到头来可能会因为AI失去饭碗。那么,AI是否应该给人们提供补偿呢?这就牵扯到了先进技术对人类的替代问题。新一波生成式AI的兴起,再度引发了人类对失业的恐慌。未来,AI等先进技术将会消除更多工作岗位,从律师、记者、艺术家、软件工程师等白领和创造性岗位,到蓝领工人。那么,有什么方法可以补偿人类为AI做出的贡献,保证他们的生存呢?全民基本收入站长网2023-04-24 14:35:000000GitHub发布嵌入式数据库txtai:集成语义搜索、LLM编排和工作流
GitHub最近发布了一款名为txtai的全新工具,这是一款嵌入式数据库,它具有语义搜索、LLM编排和语言模型工作流的综合功能。这个工具可以将多种功能和应用程序集成在一起,为开发人员提供一个全新的、一体化的解决方案。通过txtai,开发者可以更方便地进行复杂的语义搜索,进行高效的语言模型工作流设计和管理。项目地址:https://github.com/neuml/txtai站长网2023-08-22 14:14:320000孟羽童发声 称所有烦恼都与外界无关
凌晨时分,孟羽童在社交媒体上发表了一篇文章,题目为“内心圆满,人间便无憾”。在文章中,她分享了自己在东北旅行时的感悟。孟羽童对东北的热爱溢于言表,她形容这里的人们总是笑容满面,性格豁达,热情开朗,仿佛尘世的纷扰都与这片土地无关。当她问及一位司机师傅有什么烦心事时,师傅轻松地回答:“能有啥烦恼,不就那点事嘛。”这一回答让她意识到,所有的烦恼其实都是自己的内心课题,与外界无关。站长网2023-12-29 10:48:090000