AI厂商拿Robots协议当草纸,互联网秩序“礼乐崩坏”
就在一众AI大模型厂商还在为盈利发愁时,英伟达靠卖算力已成功登顶全球市值第一公司的宝座,再次证明了当淘金热汹涌时候、只有卖铁铲的最赚钱。但训练大模型不仅要算力、还要有数据,以至于Reddit、X等内容平台纷纷做起了数据买卖这个生意。只不过,如今这个生意也越来越不好做了。
近日根据路透社报道,内容授权初创公司TollBit近日向出版商发出警告称,多家人工智能公司正在规避他们用于阻止抓取内容的通用网络标准,并将抓取的内容用于训练生成式AI系统。几乎在同一时间,知名科技杂志《Wired》也发文称,AI搜索公司Perplexity存在绕过机器人排除协议(Robots Exclusion Protocol),以获取受限网络内容的行为。

再算上此前OpenAI使用YouTube上的视频内容训练打模型,谷歌也曾被曝出修改用户协议、以免费获取旗下平台用户数据的消息。似乎上至一线巨头、下至初创企业,AI行业俨然集体化身为了“数据小偷”。
一直以来,数据无疑是训练AI大模型的基础,而高质量数据更是决定了大模型的性能上限,这也正是AI厂商如同饕餮般吞噬数据的真相。为此他们可谓是满世界买数据,但现实却是可供交易的数据已经满足不了大模型的胃口了。
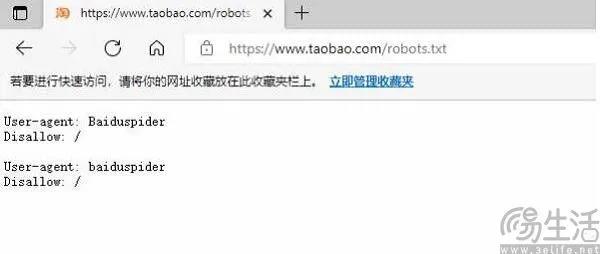
当正常买卖数据这条路不好走了之后,“偷数据”似乎就变成了AI厂商心照不宣的操作。比如这次被部分AI厂商无视的Robots Exclusion Protocol(以下简称Robots协议),其实是一个存放于网站根目录下的ASCII编码文本文件,它是控制网站被搜索内容的一种策略,也就是/Robots.txt。
Robots协议的唯一作用,就是告诉user-agent(网络爬虫)网站中的哪些内容允许被爬取、哪些内容又不能抓取。以2008年9月宣布屏蔽百度搜索引擎的淘宝为例,当时这家电商网站的Robots协议非常简单,直接就禁止了“Baiduspider”、即百度蜘蛛访问网站的任何部分。依靠这样的Robots协议,淘宝避免了流量外溢到百度,进而催生了其站内的竞价排名体系。

为什么这样简简单单的代码就能拦住了百度的爬虫呢?这是因为百度签署了《互联网搜索引擎服务自律公约》,承诺遵守Robots协议,并愿意限制搜索引擎抓取应有行业公认合理的正当理由、不利用这一协议进行不正当竞争行为。这也是后来百度起诉360违反Robots协议时,会大义凛然指责360搜索在明确承认Robots协议约束力后、又规避了这个协议的底气。
尽管Robots协议并不俱备法律层面的强制力,甚至都不是行业自律公约,实质上仅仅只是一个君子协定,可是在过去三十年里,Robots协议在事实层面成为了网站和搜索引擎共同遵守的一个有关数据抓取的规则。一个缺乏强制力的君子协定能存在、并得到不同文化背景互联网公司的认可,自然是有它的道理。
Robots协议的成功之处,就在于做到了搜索引擎和网站的双赢。其中搜索引擎抓取了网站的网页、让自己的索引库更加充实,进而满足用户对于信息的需求,而网站方则从搜索引擎处得到了流量作为回馈,进而通过流量变现赚到真金白银。
以AI搜索独角兽Perplexity为代表的一众AI厂商打破乃至无视Robots协议的趋势,如果要用一个词来形容,“礼乐崩坏”似乎是最合适的。
周朝用“礼乐”实现了人人各安其位各乐其业,长幼有序尊卑井然,上下和睦贵贱相安的秩序,而互联网的奠基人则用开放、平等、协作、快速、分享塑造了互联网世界的行为准则。互联网精神虽然并不要求每一个参与者都具备这种精神,但是Tim Berners-Lee、Marc Andreessen等早期互联网的缔造者,却在顶层设计中用“无形的大手”促使每一个参与者需要遵循互联网精神。

一个很简单的例子,就是如果大家曾经不相信互联网精神,那么Copy to China根本就不会发生。所以问题就来了,为什么互联网世界如今会“礼乐崩坏”呢?韩非子有言,“事异则备变。上古竞于道德,中世逐于智谋,当今争于气力”。早期的互联网世界“竞于道德”,是因为彼时的互联网还是蛮荒之地,大片的处女地等待着参与者来开拓,一旦找对了赛道就能扶摇直上。
可到了移动互联网时代,随着互联网世界的拓荒时代结束,每一条赛道几乎都站满了巨头,创业者就得靠智谋才能成功,否则即使成为风口上的猪,风停了也得摔下来。
而当下随着流量红利的枯竭,互联网进入存量竞争时期后,就得刺刀见红了。这时候对于AI厂商来说,获取更多的数据以训练更强的模型、再用更强的模型拉到更多的投资才是王道,遵守Robots协议反而会让自己在市场竞争中落后。

当然,AI厂商并非就想离经叛道,而是他们拿不出让数据拥有着满意的筹码。此前网站站长愿意向Googlebot敞开大门,还不是因为谷歌搜索能回馈流量,可AI厂商并不像搜索引擎那样能用流量来作为报酬,反倒是AI厂商训练的大模型可能会代替网站。所以指望网站像接纳搜索引擎一样接纳AI厂商,无异于难如登天。
所以当数据拥有者不想给、可AI厂商偏偏又很想要的情况下,“礼乐崩坏”也就来了
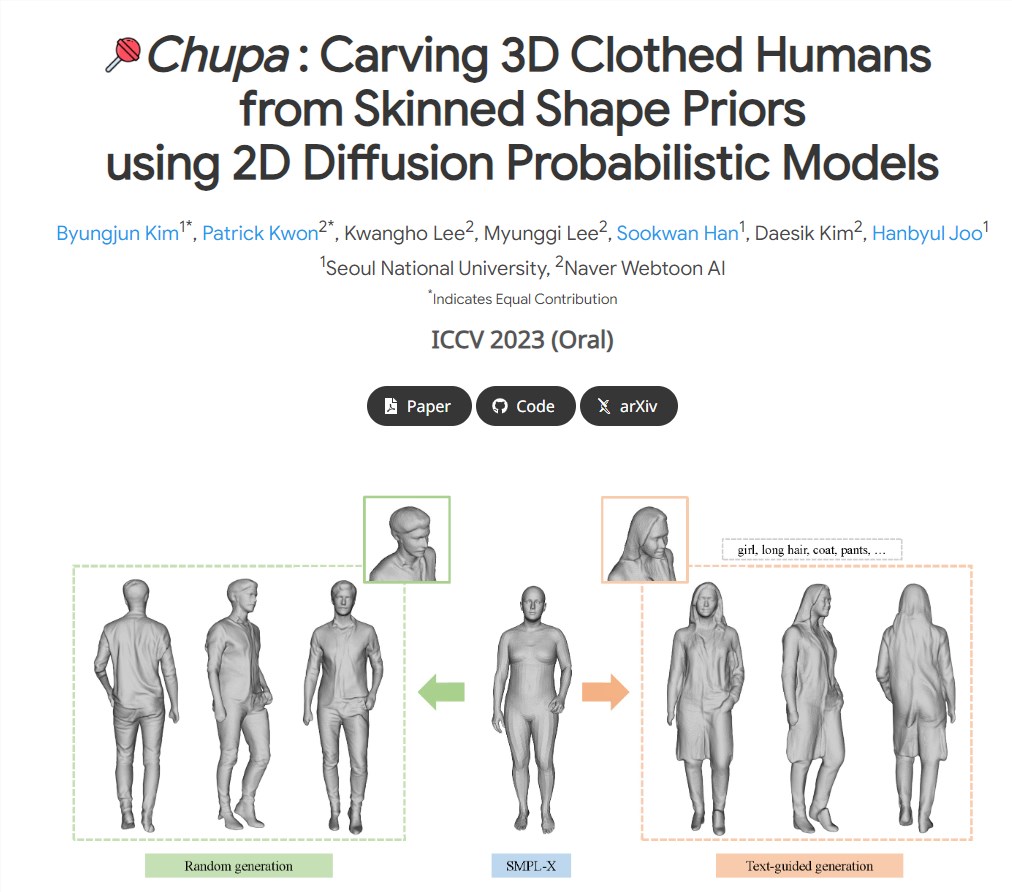
Chupa:使用 2D 扩散概率模型雕刻 3D 穿衣人体
研究人员提出了一种新的3D人体生成方法Chupa。这种方法将扩散模型的生成能力与神经渲染技术结合,以创建多样化、逼真的3D人体。它可以轻松地推广到看不见的人体姿势,并显示真实的质量。项目地址:https://snuvclab.github.io/chupa/站长网2023-09-14 19:43:040000谷歌通过资助加州新闻业和人工智能的协议避免了「链接税」法案
Google已同意资助加州的本地新闻业和人工智能计划,这一协议据称将导致立法者搁置一项要求Google为分发新闻内容向新闻机构支付费用的提案。但该协议中的州政府资助部分需要在加州年度预算流程中获得立法批准,这也引发了一些立法者和记者工会的批评。站长网2024-08-27 10:45:200000人工智能偏见暴露:亚洲女性头像变白
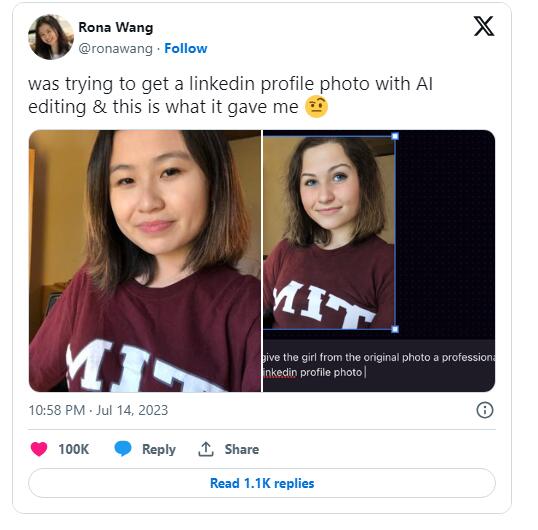
近日,一位亚裔女性在使用AI图像生成器时,发现该系统将她的头像改为白人。这位24岁的MIT毕业生RonaWang表示,PlaygroundAI编辑器让她的照片看起来更“专业”,但却将她的肤色改变为白色,从而改变了她的种族。站长网2023-08-02 15:43:090000小红书的灵魂是评论区
一年小红书重度用户谈谈粗浅的个人理解。我也想谈一谈小红书。上周池老师提到了他眼中的小红书流量分配机制的神奇,这已经被很多的案例证明过。比如有女生在垃圾堆找到了一位学者的遗物。比如有远在马来西亚的亲属在两天之内就找到了。比如一个叫小奈的女生,自己小小的世界被很多人发现了,然后被半佛老师发现了,从而她经历了成为网红之后要经历的一切。站长网2025-01-14 18:19:400000放弃挖石油,转行产品经理,中东小哥在京升职记
来中国前,朋友告诉Gabriel,只要学会四句话就能无敌。“你好,我爱你,你在哪里,我要睡觉。”大家都笑了。眼前的Gabriel,中文流畅、健谈,性格外向,很会调动气氛,讲起故事来比在座所有人的声音都要洪亮。他来自位于阿拉伯半岛西南角的也门,大学就读于中国石油大学的石油工程专业。父母一直希望Gabriel毕业后能回到中东,去富得流油的卡塔尔做一名油气工程师。站长网2024-03-11 14:06:040000