5秒完成3D生成,真香合成数据集已开源,上交港中文新框架超越Instant3D
使用大模型合成的数据,就能显著提升3D生成能力?
来自上海交大、香港中文大学等团队还真做到了。

他们推出Bootstrap3D框架,结合微调的具备3D感知能力的多模态大模型。这个框架能够自动生成任意数量的高质量的多视角图片数据,助力多视图扩散模型的训练。
结果表明,新的合成数据能够显著提高现有3D生成模型的生成物体的美学质量和文本prompt的控制能力。
目前,Bootstrap3D的数据集已经全面开源。
用大模型合成数据
近年来,3D内容生成技术迎来了飞速发展。然而,相对于2D图片生成,生成高质量的3D物体仍面临诸多挑战。
其中核心的瓶颈即在于3D数据,尤其是高质量数据的不足。
为了解决这一问题,研究团队推出Bootstrap3D框架,通过自动生成多视图图像数据来解决3D内容生成中高质量数据不足的问题。
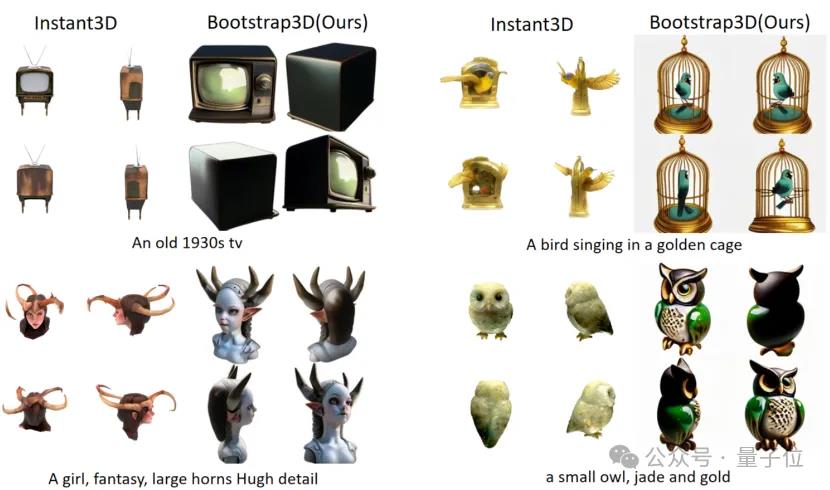
具体来说,这个框架采用了2D和视频扩散模型来生成多视图图像,并利用一个经过微调的3D多模态大模型对生成的数据进行质量筛选和描述重写。
通过这种方式,Bootstrap3D能够自动产生大量高质量的3D图像数据,从而“自举”出一个足够大的数据集,辅助训练更优秀的多视图扩散模型。
这里插一嘴,在计算机科学和机器学习领域,“Bootstrap”通常指的是一种通过自举方法解决问题的技术。
数据构建Pipeline
具体来说,数据构建Pipeline是本次框架的核心创新之一,旨在自动生成高质量的多视图图像数据,并附带详细的描述文本。
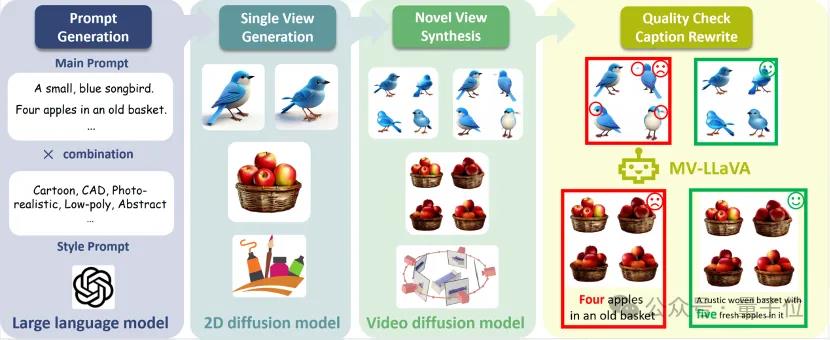
主要分为以下几个步骤:
文本提示生成:首先,使用强大的大语言模型(如GPT-4)生成大量富有创意和多样化的文本提示。这些文本提示涵盖了各种场景和物体,为后续的图像生成提供了丰富的素材。
图像生成:利用2D扩散模型和视频扩散模型,根据生成的文本提示创建单视图图像。通过结合2D和视频扩散模型的优势,生成的图像具有更高的初始质量和多样性。
多视图合成:使用视频扩散模型将单视图图像扩展为多视图图像,生成不同角度的视图。这一步骤确保了每个对象在不同视角下的一致性,解决了传统方法中视图不一致的问题。
质量筛选和描述重写:通过我们微调的3D感知模型MV-LLaVA,对生成的多视图图像进行严格的质量筛选。筛选过程不仅过滤掉低质量的数据,还重写描述文本,使其更加准确和详细。
通过这个数据构建Pipeline,Bootstrap3D能够生成大量高质量的3D图像数据,为多视图扩散模型的训练提供了坚实的基础。
这一创新不仅解决了3D数据稀缺的问题,还显著提升了模型的生成效果和对文本提示的响应能力。
训练timestep重安排(TTR)
团队还提出了一种创新的训练timestep重新安排策略(TTR),以解决多视图扩散模型训练中的图像质量和视图一致性问题。
TTR策略的核心理念是在训练过程中灵活调整合成数据和真实数据的训练时间步,从而优化去噪过程的不同阶段。
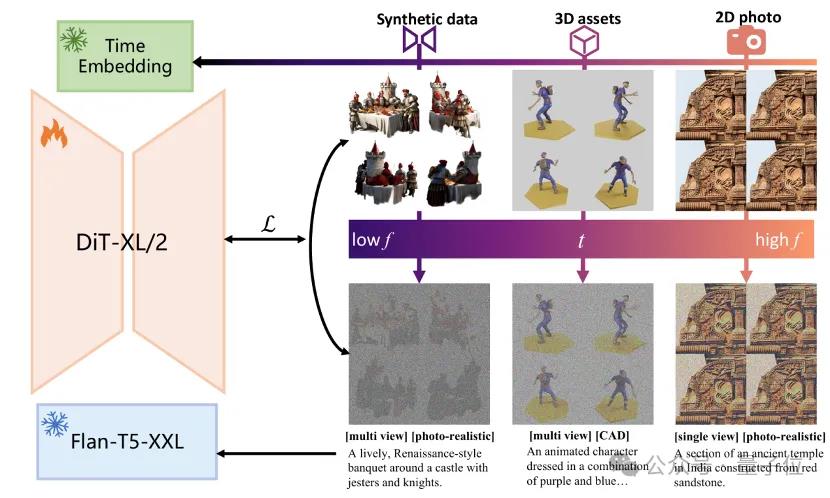
去噪过程的阶段性特征:在扩散模型中,去噪过程通常分为不同的时间步。在早期时间步,去噪过程主要关注图像的整体结构和形状(低频成分);在后期时间步,则主要生成图像的细节和纹理(高频成分)。这种阶段性特征为我们提供了调整训练策略的机会。
限制合成数据的训练时间步:由于合成数据可能存在一些模糊和失真,我们在训练时限制其时间步范围。具体来说,我们让合成数据主要参与早期的去噪阶段,确保它们对整体结构的贡献,而将后期的细节生成留给质量更高的真实数据。
分阶段训练策略:通过将合成数据限制在较大的时间步范围内(如200到1000步),我们确保这些数据在去噪过程中主要影响图像的低频成分,从而保持视图一致性。同时,真实数据则参与所有时间步的训练,以提供高频细节和真实感。这样的分阶段训练策略有效平衡了图像质量和视图一致性。
实验证明效果显著:广泛的实验结果表明,使用TTR策略的多视图扩散模型在图像-文本对齐、图像质量和视图一致性方面均表现优异。该策略不仅保留了原始2D扩散模型的优点,还显著提升了多视图生成的效果。
通过训练时间步重新安排策略(TTR),Bootstrap3D框架成功解决了合成数据质量参差不齐的问题,显著提升了多视图扩散模型的性能,为高质量3D内容生成奠定了坚实基础。
好了,Bootstrap3D生成的数据集已经全面开源,任何研究人员和开发者都可以免费访问和使用。
论文地址:
https://arxiv.org/abs/2406.00093/
项目主页:
https://sunzey.github.io/Bootstrap3D/
数据集地址:
https://huggingface.co/datasets/Zery/BS-Objaverse/
淘宝免单bug上热搜 有用户意外收到 51 元红包短信
今日,微博平台上关于“淘宝免单Bug”的话题迅速攀升至热搜榜前列。该事件源于今日中午12点左右,淘宝疑似出现系统漏洞,导致多名用户收到了神秘的“淘宝免单短信”。据用户反馈,这些短信中明确指出,用户当天在淘宝下单的商品已被免单处理,并且用户账户内已收到51元的免单红包。然而,截至发稿前,淘宝官方尚未就此事件作出任何官方回应。这一事件迅速在社交网络上引发广泛讨论。站长网2024-05-06 17:40:120000交个朋友上市后首个业绩公告:上半年GMV超50亿元
交友平台交个朋友上市后发布上半年业绩报告,GMV超过50亿元交友平台交个朋友控股(01450.HK)发布了其上市后的首份业绩报告,显示公司上半年总GMV超过50亿元。预计公司2023年中期净利润将不少于4000万元人民币,调整后净利润预计不低于9000万元人民币。与去年同期相比,公司净亏损得到扭转,呈现盈利态势。站长网2023-07-29 10:09:330000美团大众点评开始测试“智能小助手”AI功能 搜索结果由用户评价综合生成
站长之家发现,近日,美团大众点评开始悄然测试“智能小助手”功能,用户在搜索部分问题时,搜索结果页面的头部将出现“小助手”测试版,智能回答用户提问。据官方介绍,大众点评“智能小助手”功能目前处于内测阶段,只能回答部分问题,更多问题和功能正开发中,“智能小助手”回答的结果由用户评价自动综合生成。站长网2023-09-12 09:12:060001天涯进了ICU,前总编开启“搏命式”带货
一个网站突然上不去了,在如今是件寻常事。服务器宕机,或是巨大流量瞬间涌入,都有可能导致系统崩溃。成立于1999年的天涯社区(以下简称“天涯”),在它运营的24年里,发生过大大小小,太多次的宕机事件。以往的宕机,就像“头疼脑热”,是场小病,熬几天也就过去了。而天涯从4月初开始的这一场停运,已经持续快两个月。按多名天涯高管、前员工的说法,天涯没死,但“全身瘫痪”。站长网2023-05-25 09:10:250001DeepMind新AI模型AlphaMissense可预测遗传疾病
文章概要:1.AlphaMissense是GoogleDeepMind团队的新型人工智能模型,专注于分析DNA突变的影响,可加速罕见疾病研究。它以高准确度预测错义变异致病性,为医学研究提供了新工具。2.该模型结合了自然语言处理和生物学知识,可为遗传学家和医生提供有关患者DNA中潜在基因突变的重要信息,帮助更快诊断和治疗遗传性疾病。站长网2023-09-20 10:23:390000