next-token被淘汰!Meta实测「多token」训练方法,推理提速3倍,性能大涨10%+
【新智元导读】研究人员提出了一种新的大型语言模型训练方法,通过一次性预测多个未来tokens来提高样本效率和模型性能,在代码和自然语言生成任务上均表现出显著优势,且不会增加训练时间,推理速度还能提升至三倍。
当前,大型语言模型,例如GPT和Llama,主要是根据「前文的单词序列」对「下一个token」进行预测的方式来训练。
但你有没有想过一个问题,为什么不对后文的tokens同时进行预测呢?
最近,Meta、巴黎高科路桥大学、巴黎萨克雷大学的研究人员就联合提出了一种新的训练方法,即一次性预测多个未来tokens,可以提高模型的样本效率。

论文链接:https://arxiv.org/pdf/2404.19737
具体来说,在训练语料库的每一个位置,要求模型使用n个独立的输出头网络来预测紧随其后的n个token,其中所有输出头都基于同一个模型主干。
研究人员将多token预测视作是一种辅助训练任务,实验发现该方法不仅能够提升模型在各种下游任务上的表现,而且不会增加训练时间,对代码生成和自然语言生成任务都是有益的。
随着模型尺寸的增大,该方法的优势变得更加明显,尤其是在进行多epochs训练时。
在编程等生成性任务的基准测试中,使用多token预测训练的模型的性能提升尤为显著,能够稳定地超过传统单token预测模型。
例如,13B参数的模型在HumanEval基准测试中解决问题的能力比同等规模的单token模型高出12%,在MBPP基准测试中高出17%
此外,通过在小型算法任务上的实验,研究人员发现多token预测对于提升模型的归纳头(induction heads)和算法推理能力是有益的。
而且,使用多token预测训练的模型在推理时速度更快,最高可达三倍,即便是在处理大规模数据批次时也是如此。
标准语言模型通过执行一个「下一个token预测」任务来对大型文本语料库进行学习,任务目标是最小化交叉熵损失,其中模型需要最大化「在给定之前token序列历史的条件下,预测下一个token」的概率。

研究人员将「单token预测」任务泛化为「多token预测」,在训练预料上的每个位置,模型需要一次性预测未来n个tokens,交叉熵损失改写为:

为了使问题可解,假设大型语言模型使用一个共享的主干网络来生成观察到的上下文的潜表征z,然后再把该表征送入到n个独立的头网络,以并行的方式预测每一个未来token
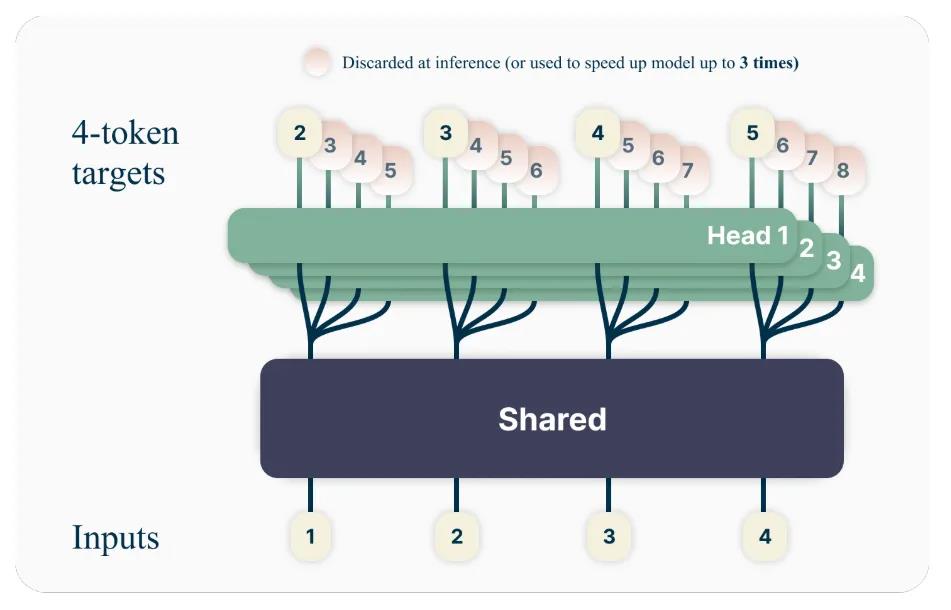
多token预测的交叉熵损失可以分解为两部分:在给定token序列下的潜表征,以及在该潜表征条件下,预测n个未来token
在实践中,该架构包括一个共享Transformer主干模型,根据上下文词序列来生成潜表征,n个独立的、基于Transformer层的输出头,以及一个共享的unembedding矩阵。

节省内存
在训练多token预测器时,一个关键问题是GPU显存占用过多。
在当前的大型语言模型(LLMs)中,词汇表的大小V通常远远大于潜在表示的维度d,因此logit vectors就成了GPU内存使用的瓶颈。
如果简单地实现多token预测器,将所有的logit vectors及其梯度都存储在内存中,会导致内存使用量迅速增加,因为每个向量的形状都是 (n, V),这种方式会极大地限制模型可同时处理的批次大小,并增加GPU显存的平均使用量。
研究人员提出了一种内存高效的实现方法,通过调整前向传播和反向传播操作的顺序来减少内存使用。
具体来说,在通过共享主干网络fs 完成前向传播后,模型会按顺序对每个独立的输出头部fi 执行前向和反向传播,并在主干网络处累积梯度,每个输出头部fi的logit向量和梯度在计算后就会被释放,无需一直占用内存,直到所有头部的计算完成。

这意味着,除了主干网络的梯度外,不需要长期存储其他任何梯度,从而显著降低了GPU内存的使用。
通过这种方式,模型的内存复杂度从O(nV d)降低到了O(V d),在不牺牲运行时间的情况下,显著减少了GPU的峰值内存使用。
推理阶段Inference
在推理时,该模型的最基础用法是使用「下一个token预测头」(next-token prediction head)进行「基本next-token自回归预测」,同时丢弃所有其他头网络。
也可以利用额外的输出头网络进行自推理解码,对从下一个token预测头网络的解码进行加速:
1. 区块并行解码(blockwise parallel decoding),一种推理解码的变体方法,可以并行地预测多个token,而不需要额外的草稿模型;
2. 使用类似美杜莎(Medusa)树注意力机制的推测解码,可以提高解码速度和效率。
研究人员总共进行了七个大规模实验来证明多token预测损失的有效性。
为了公平对比next-token预测器和n-token预测器,实验中的模型参数量均相同,也就是说,在预测未来头网络中添加n-1层时,同时也会从共享模型主干中移除n-1层。
1. 性能随模型尺寸增大而提升
为了研究模型尺寸的影响,研究人员从零开始训练了「六个」模型,尺寸范围覆盖了从300M到13B参数量,至少使用了91B tokens的代码。

从评估结果中可以看到,在MBPP和HumanEval上的实验表明,在相同的计算量下,使用多token预测,可以在固定数据集上获得更好的性能。
研究人员认为,该特性只有在大规模数据、大尺寸模型上才能体现出来,这也可能是多token预测一直没有在大型语言模型训练上广泛应用的原因。
2. 更快的推理速度
研究人员使用异构批量大小的xFormers实现贪婪自我推测解码(self-speculative decoding),并测量了最佳的4-tokens预测模型(7B参数)在补全代码和自然语言数据时的解码速度。

可以看到,该方法在代码生成任务上速度提升了3.0倍,文本生成的速度提升了2.7倍,在8字节预测模型上,推理速度提升了6.4倍。
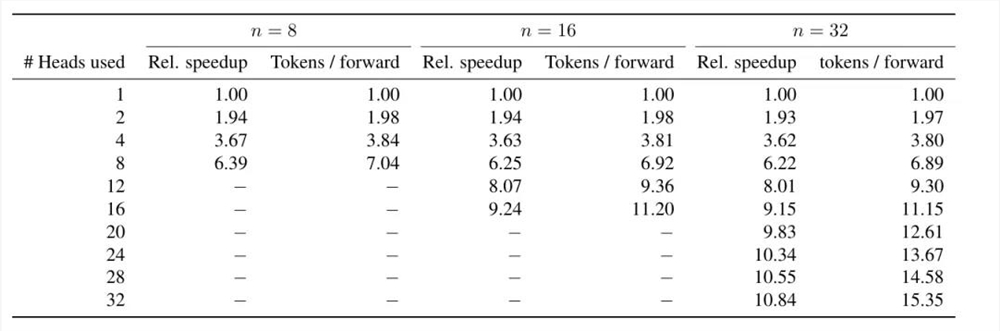
使用多token预测进行预训练时,额外的头网络可以比单个next-token预测模型的微调更准确,从而让模型充分发挥自推测解码的全部潜力。
3. 用多字节预测来学习全局pattern
为了展示next-token预测任务能够捕捉到局部模式,研究人员采取了极端情况,即字节级分词(byte-level tokenization),通过训练一个7B参数的字节级Transformer模型来处理314B个byte,大约相当于116B个tokens
8-byte预测模型与next-byte预测相比取得了显著的性能提升,在MBPP pass@1上解决了超过67%的问题,在HumanEval pass@1上解决了20%的问题。
因此,多字节预测是一个非常有前景的方法,可以让字节级模型的训练更高效。
自推测解码可以实现8字节预测模型的6倍速度提升,完全弥补了在推理时「更长字节序列」的成本,甚至比next-token预测模型快近两倍。
尽管训练所用的数据量少了1.7倍,但8字节预测模型的性能仍然能接近基于token的模型。
4. 寻找最优的n值
为了更好地理解预测token数量的影响,研究人员在7B尺寸的模型(训练数据包含了200B个代码token)上进行了全面的消融实验,在不同实验设置中尝试了 n =1,2,4,6和8
实验结果显示,使用4个未来token进行训练时,在HumanEval和MBPP的所有pass at1,10和100指标上均超越了其他对比模型:MBPP的改进分别为 3.8%, 2.1%和 3.2%,HumanEval的改进分别为 1.2%, 3.7%和 4.1%
有趣的是,在APPS/Intro上,n =6时的性能提升分别为 0.7%, 3.0%和 5.3%
最佳的窗口尺寸很可能取决于输入数据的分布。至于字节级模型,最佳窗口大小在基准测试中更为一致(8字节)。
5. 多epochs训练
在进行机器学习模型训练时,多tokens训练方法在处理相同数据集的多个训练周期时,对于预测下一个token的任务仍然显示出了优势。
虽然随着训练周期的增加,优势略有下降,但在MBPP数据集上的pass@1指标上,仍然观察到了2.4%的提升;在HumanEval数据集上的pass@100指标上,提升更是达到了3.2%
结果表明,即使在多次训练后,多tokens训练方法仍然能够带来一定的性能提升。
但对于APPS/Intro数据集来说,当训练token数量达到200B时,使用窗口大小为4的训练方法已经不再是最优的选择,可能需要调整窗口大小或采用其他策略来进一步提高模型性能。
6. 微调多token预测器
在机器学习领域,预训练模型通过多token预测损失函数进行训练,相较于传统的单token预测模型,该方法在后续的微调阶段展现出了更好的性能。
研究人员在CodeContests数据集上对具有7B参数的模型进行了微调测试,将一个能够预测接下来4个token的模型与基础的单token预测模型进行了比较,并尝试了一种将4tokens预测模型去除额外预测头后,按照传统的单token预测目标进行微调的设置。

实验结果显示,在pass@k指标上,无论采用哪种微调方式,4-tokens预测模型的表现都超过了单token预测模型,也表明4-tokens预测模型在理解任务、解决问题以及产生多样化答案的能力上更为出色。
实验结果还表明,在4-tokens预测预训练的基础上进行单token预测微调,可能是一个综合性能最佳的策略,与先使用辅助任务进行预训练,然后进行特定任务微调的经典机器学习范式相吻合。
7. 在自然语言上的多token预测
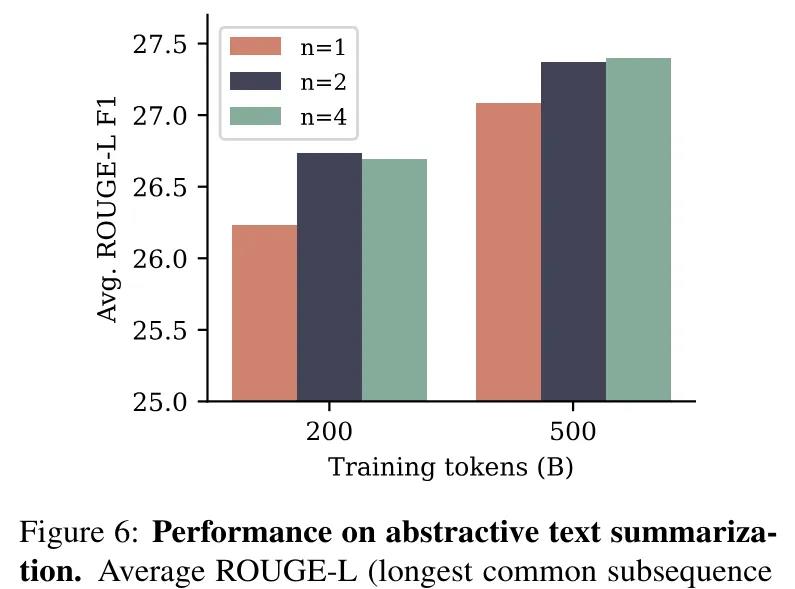
研究人员训练了参数量为7B的模型,并使用了三种不同的预测损失方法:预测4token、2-token以及单个token,并在6个标准的自然语言处理(NLP)基准测试中进行了性能评估。

在摘要任务中,使用了8个不同的基准测试,并通过ROUGE指标来自动评估生成文本的质量,结果显示,2-token和4-token的性能都比单token预测基线的表现更好。
参考资料:
https://go.fb.me/wty7gj
OPPO A2明天首销 售价1699元起
OPPO官微宣布,OPPOA2将于11月11日正式上市,12GB256GB1699元,12GB512GB1799元,并提供了静海黑、冰晶紫、清波翠三款配色供消费者选择。在首销期间,OPPO提供了电池换新服务,为购买并激活电子保修卡的用户提供四年电池保权益。站长网2023-11-10 14:28:010000华为发布面向AI大模型的存储产品 加速AI训练
华为发布面向大模型的存储产品,包括OceanStorA310深度学习数据湖存储和FusionCubeA3000训/推超融合一体机。这两款产品性能密度创新纪录,具备高效率和高性能的特点。华为数据存储团队中的“天才少年”张霁透露了他正在推进的研究课题,包括向量存储、数据方舱、近存计算等。华为在大模型时代下,注重解决数据存储问题,从而加速AI训练。站长网2023-07-20 12:59:29000010块钱解决两餐饭,年轻人爱上“剩菜盲盒”
在望京凯德Mall地下一层的一家餐厅里,每晚9点以后,角落的餐台上会规整地摆上五包封口的袋子,里面的食物原价在100~110元不等,但到了9点以后,它们被统一定价为39.9元,会在一小时内完成售卖,并被起了一个时髦的名字——剩菜盲盒。“剩菜盲盒”里的剩菜不是客人吃剩下的残羹冷炙,而是未出过后厨的餐品,或者是烘焙糕点、咖啡、寿司等简餐食物。站长网2023-05-24 14:01:400000Flyme AI大模型加持!魅族Flyme 10.5引入全新智能助手Aicy
魅族宣布,Flyme10.5将引入全新的智能助手Aicy,通过FlymeAI大模型的加持,Aicy能够发挥出强大的能力。首先,Aicy能够作为即问即答的百科全书,回答包括自然科学、生活知识、健康常识、情感问答等各类问题。其次,Aicy还能帮助用户撰写各种文本,包括微博动态、感谢信、年会发言稿等。站长网2023-11-30 15:40:470000国庆假期,消失的网红城市
火热的十一长假已经接近尾声,但奇怪的是,今年的长假却很少能看到网红城市爆火的身影。《百度地图2024年十一假期出行锦囊》数据显示,杭州千岛湖、阿坝四姑娘山为国内热门景区TOP10,甘肃甘南、云南腾冲为全国小众旅游城市TOP10。图源:《百度地图2024年十一假期出行锦囊》不少过去蹿红的网红城市,在今年国庆假期客流量虽有所增长,但和巅峰时期相比仍有很大差距。站长网2024-10-09 03:33:270000