ControlNet作者推新项目Omost 一句话变构图小作文 再也不用为写提示词头疼了
近日,ControlNet的作者推出了一个全新的项目——Omost。这个项目对现有图像模型的提示词理解有着巨大的帮助。通过很短的提示词,就可以生成非常详细并且空间表现很准确的图片。
Omost通过预定义的位置、偏移量和区域三大参数来简化图像元素的描述。这使得用户能够更直观地指定图像中各个元素的位置和大小,从而生成高质量、符合预期的图像。
使用Omost,你只需要输入简单的提示词,LLM就可以生成图像每个区域的简单提示和位置信息。然后针对图像九宫格的简单提示词继续扩展,保证了每一部分都有非常详细的描述。
比如,我输入创建一个梦幻的空中城堡,然后它给我返回了一段非常详细的图像描述:
这张照片展示了一座漂浮在高空的梦幻空中城堡,
“城堡完全由玻璃和闪闪发光的金属制成,反射出耀眼的阳光。”,
“精致的桥梁连接着各种塔,每座塔都装饰着复杂的雕刻和发光的符文。”,
“城堡周围的天空是柔和柔和色调的渐变,从黎明的粉红色过渡到黄昏的蓝色。”,
“下面是郁郁葱葱的森林、波光粼粼的河流和连绵起伏的山丘。”,
“整个场景笼罩在一种神奇的氛围中,柔和空灵的光束照亮了城堡,营造出一种奇妙和迷人的感觉。”
然后点击生成图像,它就会将上面的提示转化为图像返给你:
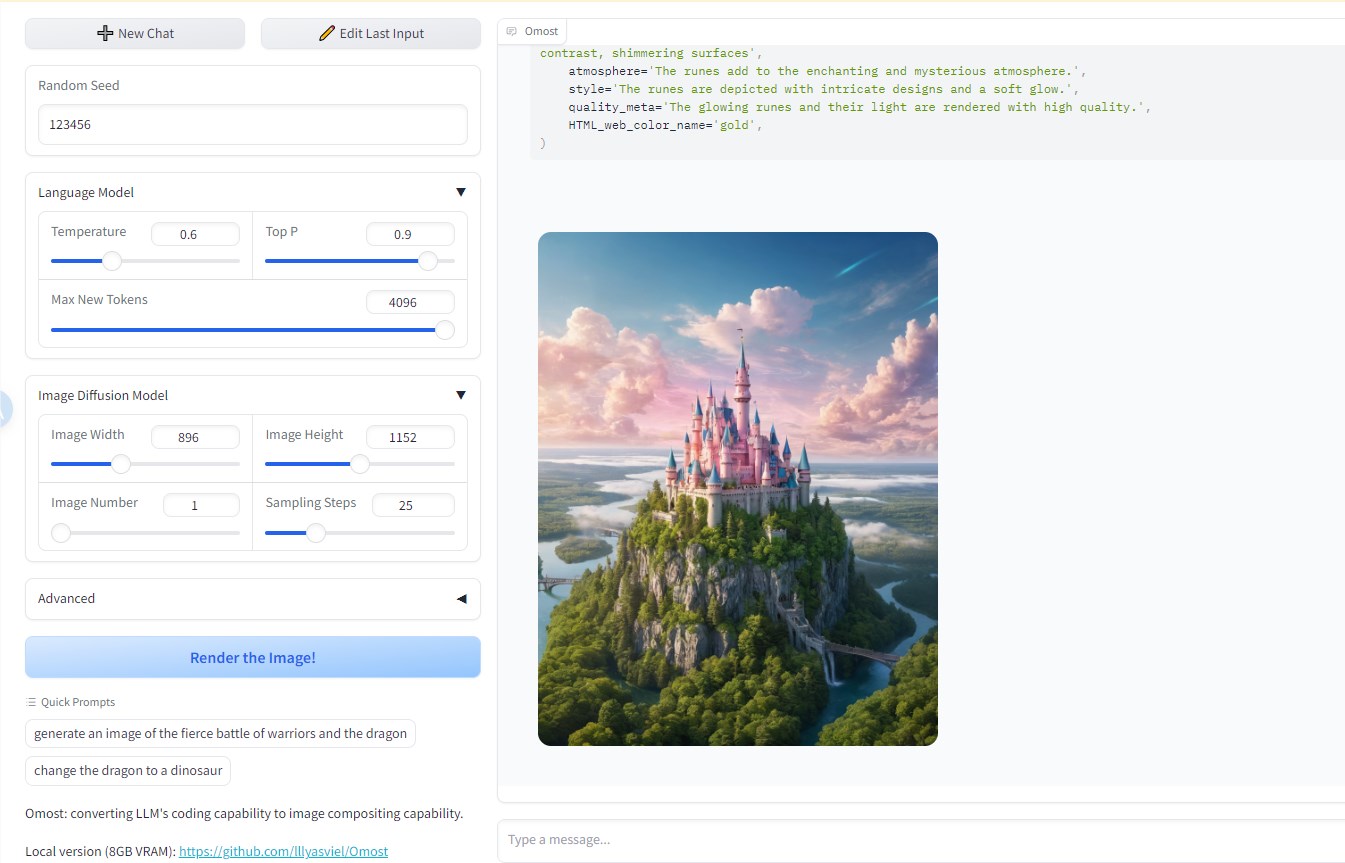
效果还不错。我们也可以将提示词复制到MJ中生成。效果如下:

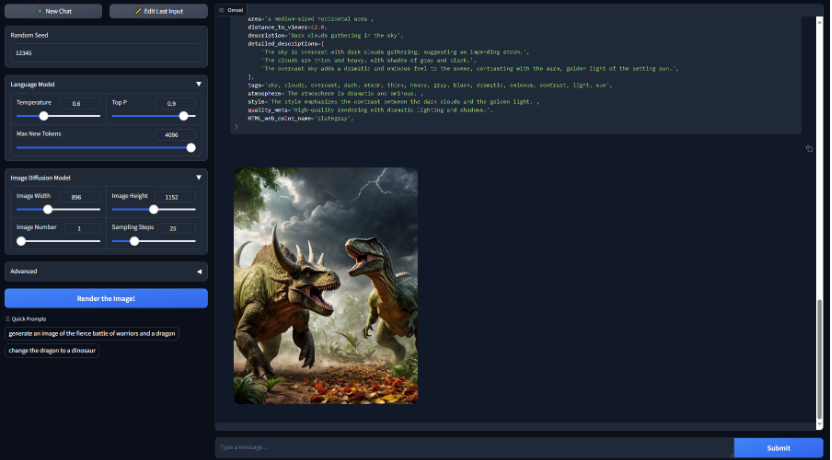
更牛逼的是,Omost已经完成的图像整体布局可以保留,如果你想修改画面中的某个元素,也只需要一句提示词即可。比如你原来的画面主体是龙,你可以直接把龙变成恐龙。
项目亮点:
自动扩展提示词:Omost能够将简单的提示词拆解成详细的描述,从图像整体到局部元素的位置和大小均能详细说明。例如输入“a funny cartoon batman fights joker”,系统会生成蝙蝠侠与小丑战斗的完整图像。
高灵活性:生成的图像布局可以保留,用户可以通过简单的提示词对图像中的某个元素进行修改。比如,将龙变成恐龙,系统会根据新提示生成修改后的图像。
图像位置编码:Omost通过将图像划分为729个不同的位置来简化图像元素的描述。每个位置包括预定义的参数,如位置、偏移量和区域,确保图像生成的准确性和细致度。
子提示系统:所有Omost LLM都经过训练,可以提供严格定义的“子提示”,这些子提示可以独立描述事物,并任意组合形成完整的提示。这种设计提高了提示词的灵活性和准确性。
注意力操纵:Omost使用注意力分数调整技术来控制图像生成过程中的区域关注度,实现更精细的图像生成。通过调整注意力分数,Omost能够生成符合提示词描述的图像元素。
提示前缀树:Omost引入提示前缀树技术,通过合并子提示来改进提示理解和描述。例如,可以将路径“a cat and a dog. the cat on the sofa”作为提示,从而生成相应图像。
Omost的实现和使用
Omost项目基于Llama3和Phi3变体模型,用户可以通过提供简单的提示词来生成复杂的图像。以下是该项目的几个关键组件:
位置和偏移量:将图像划分为9个位置,每个位置进一步划分为81个偏移量,共有729个边界框,用于描述图像元素的位置。
distance_to_viewer和HTML_web_color_name:用于调整图像元素的视觉表现,通过组合这些参数可以生成粗略的图像构图。
注意力操纵:基于注意力分数操作的baseline渲染器,通过调整注意力分数来控制不同区域的模型关注度。
应用和前景
Omost技术的推出,不仅简化了提示词的编写,还提高了图像生成的精确度和灵活性。其应用场景包括但不限于AI绘画、图像设计、广告创意、教育等领域。用户可以通过简单的提示词生成复杂的图像,为创意设计提供了强大的工具支持。
项目页:https://top.aibase.com/tool/omost
试玩地址:https://huggingface.co/spaces/lllyasviel/Omost
百川智能发布闭源大模型Baichuan2-53B 并开放API
百川智能发布了闭源大模型Baichuan2-53B,该模型全面升级了Baichuan1-53B的各项能力。Baichuan2-53B在数学和逻辑推理能力上表现出显著的提升,并且通过高质量数据体系和搜索增强的方法极大降低了模型幻觉,是目前国内幻觉问题最低的大模型。站长网2023-09-25 11:32:560000亚马逊云服务CEO表示,没有云服务就没有人工智能
本文概要:1.亚马逊云服务(AWS)首席执行官亚当·塞利普斯基基表示,人工智能(AI)与云计算密不可分,没有云就没有AI。2.塞利普斯基认为,目前只有大约10%的潜在客户已经转向了云计算,云计算市场的增长潜力巨大。3.AWS正积极投入AI领域,但也面临一些挑战,如与竞争对手的云服务合作以及硬件供应短缺。站长网2023-08-09 10:33:280000宇视科技推出宇视AIoT行业大模型“梧桐”
近日,千方科技全资子公司宇视科技发布AIoT行业大模型“梧桐”。该大模型集CV(计算机视觉)行业、NLP(自然语言处理)行业等于一身,能够充分满足多样化的任务和场景需求。据悉,宇视以通用大模型行业场景训练调优为架构,推出宇视AIoT行业大模型。能为合作伙伴共建生态、实现更多跨领域发展赋能,驱动CV行业二次变革。站长网2023-05-12 08:44:140000融资1亿美元的类ChatGPT模型开源啦!可商用,8个模型
上周二,「AIGC开放社区」为大家介绍了融资1亿美元的生成式AI平台Writer。该企业能在短短3年时间获得1.26亿美元总融资成为ChatGPT的主要竞争对手之一,与其精湛的技术密不可分,同时充分证明其模型有成功的应用案例并获得资本、用户的认可。站长网2023-09-25 09:26:160002英特尔高管称「Windows 12」将于 2024 年推出:AI 功能刺激更新需求
微软正在逐渐为Windows1123H2的全面发布做准备,这是Windows11操作系统的最新功能更新。然而,有许多未经证实的传言称,该公司正在为一项可能会或可能不被标记为Windows12的重大更新做准备。站长网2023-10-08 11:49:240000