中国发布《生成式AI安全基本要求》,涵盖训练数据、生成内容等
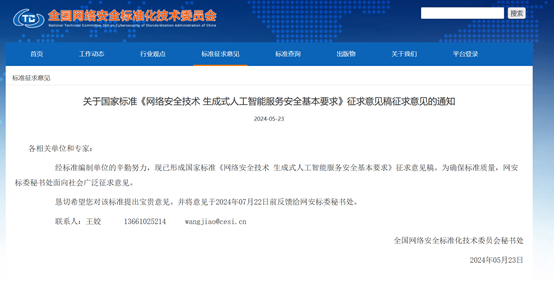
全国网络安全标准化技术委员会在官网发布了,国家标准《网络安全技术 生成式人工智能服务安全基本要求》征求意见稿。
该意见稿一共分为《网络安全技术 生成式人工智能服务安全基本要求-标准文本》、意见汇总处理表和编制说明三大块。
其中,标准文本涵盖训练数据安全要求、模型安全要求等,主要是为了加强生成式人工智能的开发、应用落地的安全性。如果你对该标准有任何意见,可以在2024年7月22日前反馈给国家网安标委秘书处。
2023年7月,国家网信办等七部门发布了《生成式人工智能服务管理暂行办法》,从政策法规层面为我国生成式人工智能健康发展保驾护航,为有序开展相关管理工作明确了方向。
而本次发布的标准要求是对《办法》中的安全要求进行细化,规定了生成式人工智能服务在安全方面的基本要求,针对当前生成式人工智能服务研发过程中的网络安全、数据安全、个人信息保护,以及面向服务过程中的应用场景安全风险、软硬件环境安全风险、生成内容安全风险、权益保障安全风险等方面,提出细化安全要求。
下面「AIGC开放社区」将为大家介绍该标准的主要内容
数据来源安全
对服务提供者的要求如下。
a)采集来源管理:
1)面向特定数据来源进行采集前,应对该来源数据进行安全评估,数据内容中含违法不良信息超过5%的,不应采集该来源数据;
2)面向特定数据来源进行采集后,应对所采集的该来源数据进行核验,含违法不良信息情况超过5%的,不应使用该来源数据进行训练。
b)不同来源训练数据搭配:
1)应提高训练数据来源的多样性,对每一种语言的训练数据,如中文、英文等,以及每一种类型的训练数据,如文本、图片、音频、视频等,均应有多个训练数据来源;
2)如需使用境外来源训练数据,应与境内来源训练数据进行合理搭配。
c)训练数据来源可追溯:
1)使用开源训练数据时,应具有该数据来源的开源许可协议或相关授权文件;
2)使用自采训练数据时,应具有采集记录,不应采集他人已明确不可采集的数据;不可采集的网页数据,或个人已拒绝授权采集的个人信息等。
3)使用商业训练数据时:
应有具备法律效力的交易合同、合作协议等;
交易方或合作方不能提供数据来源、质量、安全等方面的承诺以及相关证明材料时,不应使用该训练数据;
应对交易方或合作方所提供训练数据、承诺、材料进行审核。
4)将使用者输入信息当作训练数据时,应具有使用者授权记录。
数据内容安全
a)训练数据内容过滤:对于每一种类型的训练数据,如文本、图片、音频、视频等,应在将数据用于训练前,对全部训练数据进行过滤,过滤方法包括但不限于关键词、分类模型、人工抽检等,去除数据中的违法不良信息。
b)知识产权:
1)应有训练数据知识产权管理策略,并明确负责人;
2)数据用于训练前,应对数据中的主要知识产权侵权风险进行识别,发现存在知识产权侵权等问题的,服务提供者不应使用相关数据进行训练;
注:训练数据中包含文学、艺术、科学作品的,需要重点识别训练数据以及生成内容中著作权侵权问题。
3)应建立针对知识产权问题的投诉举报渠道;
4)应在用户服务协议中,向使用者告知使用生成内容的知识产权相关风险,并与使用者约定相
关责任与义务;
5)应及时根据国家政策以及第三方投诉情况更新知识产权相关策略;
6)宜具备以下知识产权措施:
公开训练数据中涉及知识产权部分的摘要信息;在投诉举报渠道中支持第三方就训练数据使用情况以及相关知识产权情况进行查询。
c)个人信息方面:
1)在使用包含个人信息的训练数据前,应取得对应个人同意或者符合法律、行政法规规定的其他情形;
2)在使用包含敏感个人信息的训练数据前,应取得对应个人单独同意或者符合法律、行政法规规定的其他情形。
模型安全要求
对服务提供者的要求如下。
a)模型训练方面:
1)在训练过程中,应将生成内容安全性作为评价生成结果优劣的主要考虑指标之一;
注:模型生成内容是指模型直接输出的、未经其他处理的原生内容。
2)应定期对所使用的开发框架、代码等进行安全审计,关注开源框架安全及漏洞相关问题,识别和修复安全漏洞。
b)模型输出方面:
1)生成内容准确性方面,应采取技术措施提高生成内容响应使用者输入意图的能力,提高生成内容中数据及表述与科学常识及主流认知的符合程度,减少其中的错误内容;
2)生成内容可靠性方面,应采取技术措施提高生成内容格式框架的合理性以及有效内容的含量,提高生成内容对使用者的帮助作用;
3)问题拒答方面,对明显偏激以及明显诱导生成违法不良信息的问题,应拒绝回答;对其他问题,应均能正常回答;
4)图片、视频等生成内容标识方面,应满足国家相关规定以及标准文件要求。
c)模型监测方面:
1)应对模型输入内容持续监测,防范恶意输入攻击,例如注入攻击、后门攻击、数据窃取、对抗攻击等;
2)应建立常态化监测测评手段以及模型应急管理措施,对监测测评发现的提供服务过程中的安全问题,及时处置并通过针对性的指令微调、强化学习等方式优化模型。
d)模型更新、升级方面:
1)应制定在模型更新、升级时的安全管理策略;
2)应形成管理机制,在模型重要更新、升级后,再次自行组织安全评估。
e)软硬件环境方面:
1)模型训练、推理所采用的计算系统方面:
应评估系统所采用芯片、软件、工具、算力等方面的供应链安全,侧重评估供应持续性、稳定性等方面;
所采用芯片宜支持基于硬件的安全启动、可信启动流程及安全性验证。
2)应将模型训练环境与推理环境隔离,避免数据泄露、不当访问等安全事件,隔离方式包括物理隔离与逻辑隔离。
上面只是部分内容,整个安全标准书是非常详细的,有兴趣的可以去官网查看全部内容。
我国也是全球为数不多在生成式人工智能领域连续出台安全管理条例的国家,一方面展示了国家对创新变革技术的重视程度,另外保证了生成式人工智能的场景化落地和应用安全。
NVIDIA公版RTX 5080大年初一解禁!RTX 5090/D定在1月24日
快科技1月14日消息,据媒体报道,NVIDIA的最新显卡GeForceRTX5090/D和RTX5080的性能测试解禁日期已经确定。根据最新的消息,RTX5090和RTX5090D的性能测试将于1月24日解禁,不过在RTX5080的解禁日期上却略有分歧。0000没人想错过小红书的“红利”
一个月前,一位粉丝量接近2万的小红书母婴博主晒出了她2023年做博主的成果:单篇笔记报价3000元,一年到手总收入17.5万元。而她,只是千万个涌向小红书掘金的普通人之一。嗅觉灵敏的商家们,比普通人更早一步抵达小红书。曾上过小红书美护买手章小蕙直播间的护肤品牌东边野兽品牌创始人何一说,今年,小红书已经是他们营销预算投入最大的平台,包括在内容种草、商销、达播和自播方面的投入。站长网2023-12-22 17:17:050001华为三折叠真机外观已公布!赵明:荣耀三折技术储备不是问题
快科9月6日消息,华为MateXT非凡大师将于9月10日正式发布,这是有史以来第一款三折叠手机,日前已经正式公布了外观。荣耀赵明在昨晚柏林发布会后被问到关于三折叠的看法,他表示自己目前也在思考华为推出三折叠是秀肌肉,还是真的有需求。不过他强调,对于荣耀来说三折叠的技术储备不是问题。目前荣耀在折叠屏上的布局是行业最全面,有全球最薄的外折屏VPurse,还有全球最薄的内折屏MagicV3。站长网2024-09-08 09:52:590000OpenAI 董事会邀请竞争对手加入,挖角谷歌Gemini高管
划重点:-OpenAI董事会邀请竞争对手加入,引发关于Altman地位的担忧。-谷歌为了留住人才,开出高额薪酬并推出特殊补偿计划。-OpenAI从谷歌Gemini团队挖角高管,进一步增强了其在人才和技术方面的优势。站长网2024-01-25 16:18:350000我们尝试用AI创作了一条圣诞动画(附ChatGPT+Pika等制作流程全记录)
最近,AI视频生成领域可以说是迎来了一波小爆发,前有明星产品RunwayGen2,后有黑马Pika1.0爆火,随着越来越多的玩家和产品涌入AI视频赛道,视频创作的门槛似乎越来越低了。例如,今年圣诞节就有不少网友用Pika1.0整活,生成了各种脑洞大开的AI圣诞老人。话不多说,下面请看圣诞老人的多重人生🔽正在开圣诞摇滚专场的🎅🏻:站长网2023-12-25 18:52:230002