用GPT-3.5生成数据集!北大天工等团队图像编辑新SOTA,可精准模拟物理世界场景
高质量图像编辑的方法有很多,但都很难准确表达出真实的物理世界。
那么,Edit the World试试。

来自北京大学、Tiamat AI、天工AI、Mila实验室提出了EditWorld,他们引入了一种新的编辑任务,即世界指令(world-instructed)图像编辑,它定义和分类基于各种世界场景的指令。

在一组预训练模型,比如GPT-3.5、Video-LLava 和 SDXL的支持下,建立了一个带有世界指令的多模态数据集。
在该数据集训练了一个基于扩散的图像编辑模型EditWorld,结果在其新任务的表现明显优于现有的编辑方法,实现SOTA。
图像编辑新SOTA
现有的方法通过多种途径实现高质量的图像编辑,包括但不限于文本控制、拖动操作以及inpainting。其中,利用instruction进行编辑的方法由于使用方便受到广泛的关注。
尽管现有的图片编辑方法能够产生高质量的结果,但它们在处理传达物理世界中真实视觉动态的世界动态方面仍然存在困难。
如图1所示,无论是InstructPix2pix还是MagicBrush都无法生成合理的编辑结果。

为了解决这一问题,团队引入了一项新的任务,称为world-instructed image editing,使图像编辑能够反映真实物理世界和虚拟媒体中的“世界动态”。
具体来说,他们定义并分类了各种世界动态指令,并基于这些指令创建了一个新的多模态训练数据集,该数据集包含大量的输入-指令-输出三元组。
最后,团队使用精心制作的数据集训练了一个文本引导的扩散模型,并提出了一种零样本图像操作策略,以实现world-instructed image editing。
根据现实世界以及虚拟媒体中的任务场景,将world-instructed image editing分为7种认为类别,并对每一种类别进行了定义与介绍,同时提供了一个数据样例。

随后团队设计了文本到图片生成以及视频分镜提取两个分支来获取数据集。
文本生成图片分支是为了丰富数据场景的丰富性,在该分支下,团队首先利用GPT生成文本四元组(包括input图片描述、instruction、output图片描述以及关键词),接着利用input以及output描述生成对应文本的图片,利用关键词对应的attention map对编辑位置进行定位获取编辑mask,与此同时为了保证前后两张图关键特征的一致性,团队引入了image prompt adaption的方法IP-Adapter,最后团队使用IP-Adapter以及ControlNet,结合output image的canny map以及input image的image prompt feature,利用Image Inpainting对output image进行调整,从而获得比较有效的编辑数据。
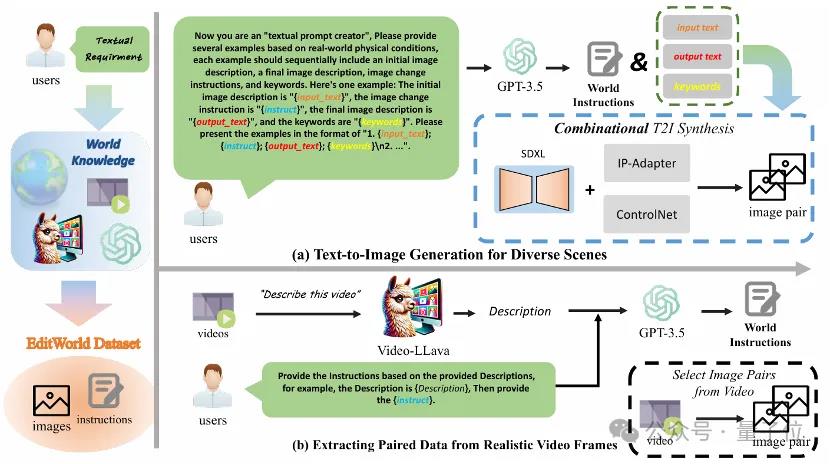
利用文本生成图片分支得到场景丰富的数据后,为了能向数据集中添加真实数据,团队从视频中提取高质量的关键帧作为编辑数据。具体来说,团队从视频分镜中提取相关性强且结构差异大两帧作为起始与末尾帧,并切分出一段新的分镜,利用多模态大模型对这段分镜的变化进行描述,最后团队以起始与末尾帧作为input image以及output image,以得到的描述作为instruction,这样就获得了需要的编辑数据。
再进一步,团队利用人工对生成数据进行recheck,从而进一步提升数据质量。
团队利用数据集对InstructPix2Pix模型进行finetune,同时为了保护非编辑区域实现更为精确的编辑,团队提出了post-edit策略。


最终可以看到,团队的方法可以很好地实现world-instructed image editing。
论文链接:
https://arxiv.org/abs/2405.14785
代码链接:
https://github.com/YangLing0818/EditWorld
耗资1.3万,ASU团队揭秘o1推理!碾压所有LLM成本超高,关键还会PUA
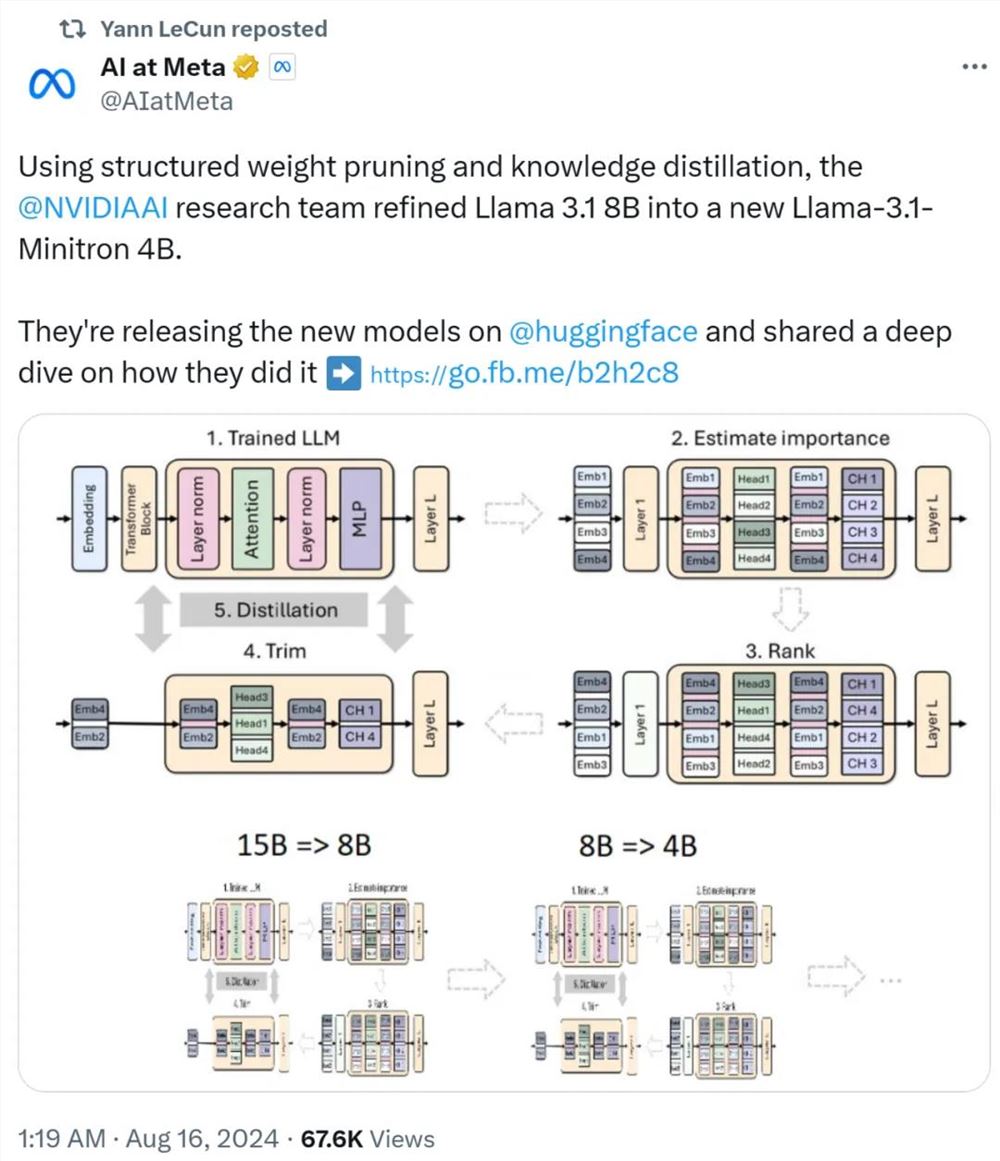
【新智元导读】LLM不会规划,大推理模型o1可以吗?ASU团队最新研究发现,o1-preview推理规划能力是所有模型之最,但仍未触及天花板。关键是,推理强,成本超高。LLM依然不会规划,LRM可以吗?OpenAI声称,草莓o1已经突破了自回归LLM常规限制,成为一种新型的「大推理模型」(LRM)。它能够基于强化学习,通过CoT多步推理。并且,这种推理过程的代价,是高昂的。站长网2024-10-06 23:35:010000英伟达玩转剪枝、蒸馏:把Llama 3.1 8B参数减半,性能同尺寸更强
上个月,Meta发布了Llama3.1系列模型,其中包括Meta迄今为止最大的405B模型,以及两个较小的模型,参数量分别为700亿和80亿。Llama3.1被认为是引领了开源新时代。然而,新一代的模型虽然性能强大,但部署时仍需要大量计算资源。因此,业界出现了另一种趋势,即开发小型语言模型(SLM),这种模型在许多语言任务中表现足够出色,部署起来也非常便宜。站长网2024-08-17 11:47:480000小鹏G6站起来了!小鹏8月交付新车13690台:同比暴涨4成
快科技9月1日消息,小鹏汽车今日公布最新交付成绩,8月份共交付新车13,690台,环比增长24%,同比增长43%,连续两个月交付突破万台。其中,作为小鹏的明星车型,小鹏G6本月交付突破7,000台,环比增长80%,累计交付突破11,000台,仅45天即实现交付过万。0000苹果推出降噪语言模型DLM 用于纠正ASR系统中的错误
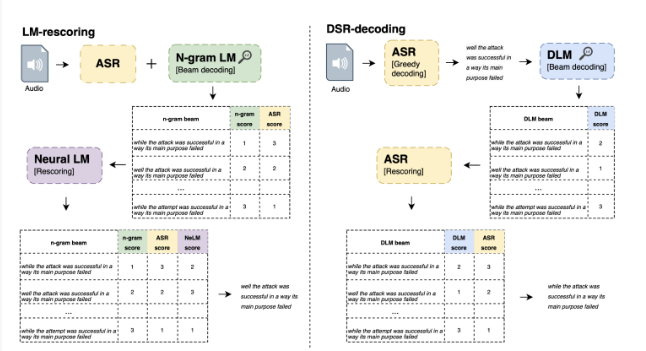
苹果最近推出了一项新的技术创新,去噪语言模型(DLM),通过大量合成数据的训练,取得了超越以往的成就,实现了自动语音识别(ASR)领域的最新性能水平。这项技术的核心在于使用文本转语音(TTS)系统创建音频,并将其输入ASR系统,通过这种方式产生了嘈杂的假设,与原始文本进行配对,从而训练DLM。该方法的关键要素包括升级的模型和数据、多说话人TTS系统、各种噪声增强策略以及新的解码技术。站长网2024-05-28 19:16:060002印度发布新规 要求人工智能公司发布模型前获得政府批准
站长之家(ChinaZ.com)3月4日消息:近日,印度电子和信息技术部本周向科技公司发布了一项新规,要求“重要”的人工智能公司在推出新模型之前需获得政府许可。该规定引发了科技界的强烈反对,许多人担心这会扼杀创新。印度风险投资公司和初创公司警告说,这种监管将损害印度在全球科技领域的竞争力。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2024-03-04 20:04:270000