一个读取excel数据处理完成后读入数据库的例子
最近收集了一批数据,各地根据问题数据做出反馈,但是各地在反馈的时候字段都进行了创新,好在下发的数据内容并没有改变,开始写的单进程的,由于时间较长,耗时380 秒,又改成多进程的,时间缩短为80-秒。现在把程序发出来,请各位大神进行指正。
import multiprocessing
import os
import time
import pandas as pd
from sqlalchemy import create_engine
import asyncio
import warnings
# warnings.simplefilter("ignore")
ywstrList=['经办机构', '原子业务编号', '原子业务名称', '风险名称','风险描述',
'校验规则结果', '创建时间', '风险提示信息', '业务日志号']
ywstrListMemo=['经办机构', '原子业务编号', '原子业务名称', '风险名称','风险描述',
'校验规则结果', '创建时间', '风险提示信息', '业务日志号','memo','time']
szlist = ['省本', '成都', '自贡', '攀枝', '泸州', '德阳', '绵阳', '广元',
'遂宁', '内江', '乐山', '南充', '眉山', '宜宾', '广安', '达州',
'雅安', '巴中', '资阳', '阿坝', '甘孜', '凉山']
# connect = create_engine('mysql pymysql://root:@127.0.0.1:3306/ywgk?charset=utf8')
connect = create_engine('mysql mysqlconnector://root:@127.0.0.1:3306/ywgk?charset=utf8')
# engine = create_engine('mysql mysqlconnector://scott:tiger@localhost/foo')
def findSZ(filename):
for sz in szlist:
if filename.find(sz) != -1:
return sz
return None
def ReadExcel(filename):
xlsdf = ''
xlsdf = pd.read_excel(filename)
""""
remove columns='sz' or '市'
"""
if "市" in list(xlsdf.keys().to_list()):
xlsdf.drop(columns='市', axis=1, inplace=True)
if "sz" in list(xlsdf.keys().to_list()):
xlsdf.drop(columns='sz', axis=1, inplace=True)
xlsdf = xlsdf.fillna("").astype('string')
return xlsdf
def filterDataOfSz(filename, xlsdf):
sz = findSZ(filename)
print(sz)
"""
筛选出包含对应市州的数据。
"""
if sz != None:
xlsdf = xlsdf[xlsdf['经办机构'].str[:2] == sz] # 筛出本市州数据
return xlsdf
def ConCatRestCols(xlsdf):
"""
去掉业务部分字段,保留市州反馈意见。
"""
print(xlsdf)
# if xlsdf==None:
#
print(filename "为空,需要处理")
#
return
xlfdf_keys_set = set(xlsdf.keys().to_list())
xlsdf_restkeys_set = xlfdf_keys_set - set(ywstrList)
xlsdf_restkeys_list = list(xlsdf_restkeys_set)
xls_rest_df = xlsdf.loc[:, xlsdf_restkeys_list] # 可以正确操作
xlsdf['memo'] = '#'
for col in xlsdf_restkeys_list:
xlsdf['memo'] = xlsdf[col]
#
return xlsdf
def SetTimeStamp(filename, xlsdf):
xlsdf['time'] = os.stat(str(filename)).st_mtime
return xlsdf
async def ProcessExcelAndtosql(filename, table):
df = ReadExcel(filename)
df = filterDataOfSz(filename=filename, xlsdf=df)
df = ConCatRestCols(df)
df = SetTimeStamp(filename=filename, xlsdf=df)
df = df.loc[:, ywstrListMemo]
print(filename)
print(df)
df.to_sql(name=table, con=connect, if_exists='append', index=False, chunksize=1000, method='multi')
def profile(func):
def wrapers(*args,**kwargs):
print("测试开始")
begin=time.time()
func(*args,**kwargs)
end=time.time()
print(f"耗时{end-begin}秒")
return wrapers
# async def getmsg(msg):
#
print(f'#{msg}')
#
await asyncio.sleep(1)
def getFiles(src:str):
import pathlib
files=[]
for file in pathlib.Path(src).rglob("*.xls?"):
files.append(str(file))
return files
def process_asyncio(files,table):
loop=asyncio.new_event_loop()
tasks=[loop.create_task(ProcessExcelAndtosql(filename,table)) for filename in files]
loop.run_until_complete(asyncio.wait(tasks))
@profile
def run(iterable,table):
process_count = multiprocessing.cpu_count()
# print(process_count)
pool = multiprocessing.Pool(process_count-2)
iterable=get_chunks(iterable, process_count)
for lst in iterable:
pool.apply_async(process_asyncio, args=(lst,table))
pool.close()
pool.join()
def main():
files = getFiles(r"e:\市州返回")
run(files, 'ywgk3')
def get_chunks(iterable,num):
# global iterable
import numpy as np
return np.array_split(iterable, num)
# import profile
if __name__=="__main__":
main()
本人只是编程的业余爱好者,只是把技术用于辅助工作,并没有深入研究技术理论,都是野路子,还请批评指正。
AI厂商拿Robots协议当草纸,互联网秩序“礼乐崩坏”
就在一众AI大模型厂商还在为盈利发愁时,英伟达靠卖算力已成功登顶全球市值第一公司的宝座,再次证明了当淘金热汹涌时候、只有卖铁铲的最赚钱。但训练大模型不仅要算力、还要有数据,以至于Reddit、X等内容平台纷纷做起了数据买卖这个生意。只不过,如今这个生意也越来越不好做了。站长网2024-06-29 22:14:320002Hinton揭秘Ilya成长历程:Scaling Law是他学生时代就有的直觉
2003年夏天的一个周日,AI教父Hinton在多伦多大学的办公室里敲代码,突然响起略显莽撞的敲门声。门外站着一位年轻的学生,说自己整个夏天都在打工炸薯条,但更希望能加入Hinton的实验室工作。Hinton问,你咋不预约呢?预约了我们才能好好谈谈。学生反问,要不就现在吧?站长网2024-05-27 16:34:330000百度:已有超300家伙伴参与文心千帆大模型平台内测
昨日,百度方面透露,目前已有超过300家伙伴参与文心千帆大模型平台内测,在400多个企业内部场景取得测试成效。百度表示,文心千帆大模型平台在多机多卡训练性能方面,可以更快达到收敛的状态,在全球权威AI基准评测MLPerf榜单中排名世界第一。站长网2023-05-19 11:24:590000斯坦福大学实锤GPT-4变笨了,OpenAI最新回应:确实存在“智力下降”
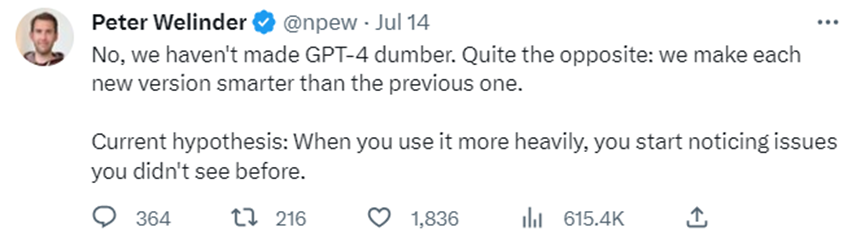
大模型天花板GPT-4,它是不是……变笨了?之前有不少用户提出质疑,并晒出了不少证据。对此,OpenAI7月14日澄清:“我们没有把GPT4弄笨。相反的,我们的每个新版本,都让GPT4比以前更聪明了。”PeterWelinder是OpenAI的产品产品VP但为了验证OpenAI的说法,斯坦福大学和加利福尼亚大学伯克利分校的三位研究员调查了3月至6月期间ChatGPT性能的变化。站长网2023-07-21 22:05:360000巨量引擎推出智能短视频脚本工具、智能成片等AIGC产品
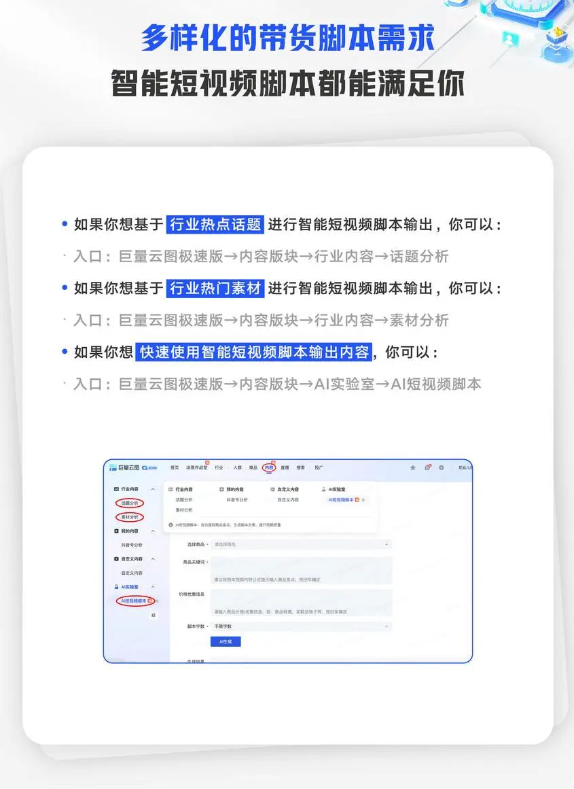
字节跳动旗下巨量引擎推出了一款智能短视频脚本工具,免费供抖音商家使用,可以帮助商家快速生成符合抖音标准的带货短视频,系统将为商家智能分析视频,锁定高光帧和拆解黄金公式,仅需20秒即可根据内容公式或自定义功能,自动生成爆款带货短视频脚本,商家使用智能短视频脚本工具后GMV提升了58%。站长网2023-09-20 11:16:090001